

DagsHub Pipelines¶
DagsHub Pipelines are a version-specific interactive presentation of your data pipeline. It visualizes the components defined within the pipeline (code, data, models, metrics, etc.), their relationship, and source. From DagsHub Pipelines, you can easily navigate to specific versions of all the files defined in the pipeline, view, diff, and comment to build your knowledge base as you go. DagsHub Pipelines provide a high-level, bird’s eye view of the entire project and can help review major updates or onboard new team members.
How do DagsHub Pipelines work?¶
DagsHub parses every git commit and looks for directed acyclic graph (simplified ‘DAG’; like in DagsHub!) files (e.g., dvc.yaml and dvc.lock).
When a new file or version is found, DagsHub processes them to generate a DAG presented in the root of your DagsHub repository. Here’s an example of what DagsHub Pipelines look like:
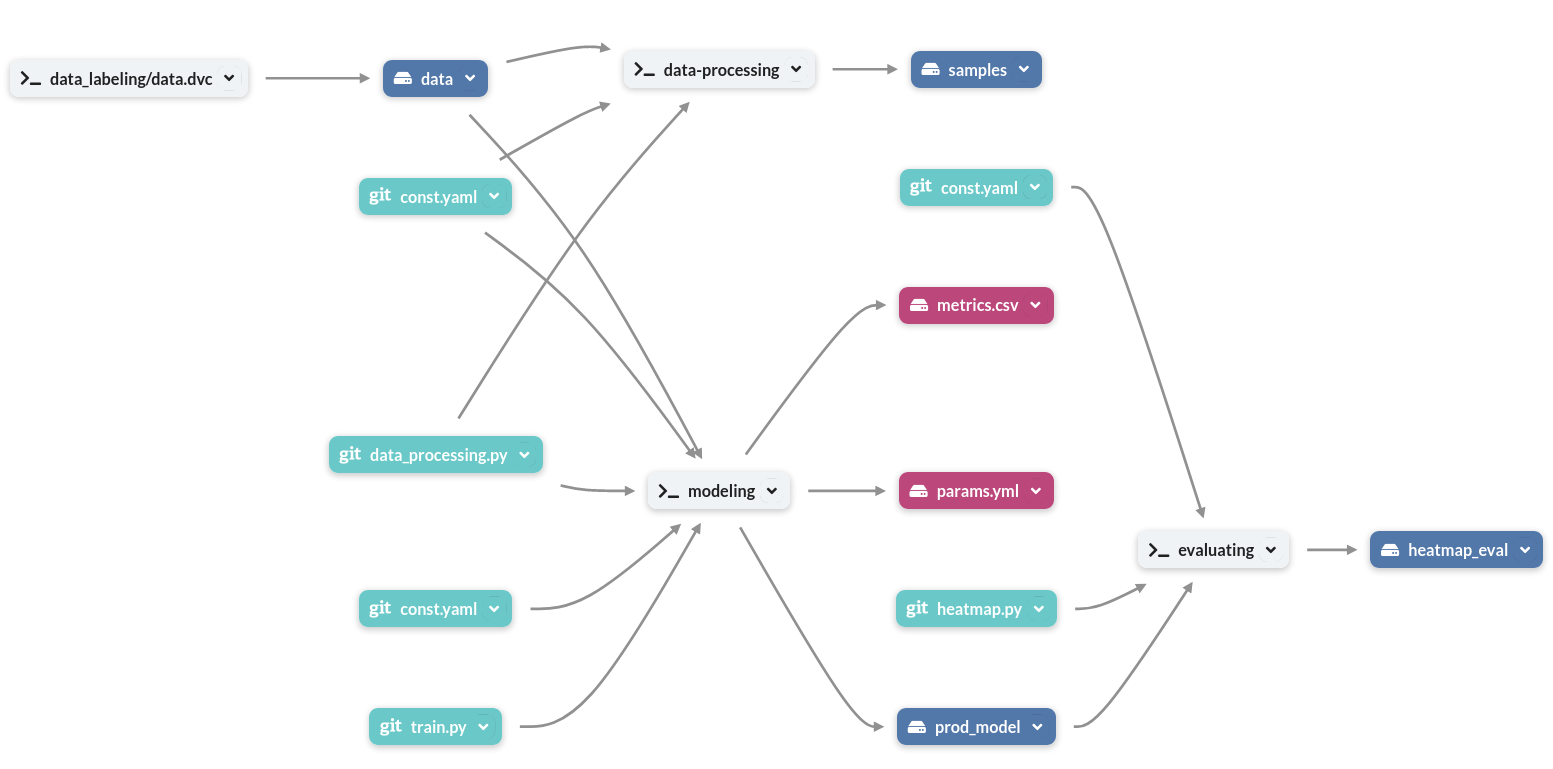
Info
Since pipelines are parsed on a per-commit basis, they are versioned through git by default. Therefore, each rendition holds a commit-specific version of the DagsHub Pipeline.
What are the components of a DagsHub Pipeline?¶
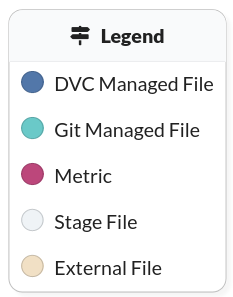
DagsHub Pipelines have five types of components that are color-coded:
- DVC Managed Files
- Git Managed Files
- Metrics
- Stage Files
- External Files
These components are in constant relation with one another, pivoting around stages. Dependencies are files used in order to run a particular stage. Metrics and outputs are the files generated by a particular stage. Outputs of one stage may be dependencies of another.
Stages are the commands connecting dependencies, outputs, and metrics by associating them to their relevant step within the entire process. The commands are run by the pipeline using the dependencies, and generating metrics and other outputs. Stages appear white in color, and are named during the building process of the pipeline.
Files may also be imported to your repository from external sources, such as the source to a dataset you may be using. These are color-coded pastel yellow. They are created using dvc import.
How to Create a Data Pipeline with DVC¶
Info
Below is a very brief run-through of the steps required to build your own data pipeline. For additional information, visit Iterative’s DVC Pipeline documentation.
Building a data pipeline is similar to building a lego creation, primary difference being the building blocks are stages. Much of building a pipeline revolves around stacking stages one after another.
The main command for this is dvc stage add. Example usage as follows:
$ dvc stage add -n featurization \
-d code/featurization.py \
-d data/test_data.csv \
-d data/train_data.csv \
-o data/norm_params.json \
-o data/processed_test_data.npy \
-o data/processed_train_data.npy \
python3 code/featurization.py
Where, the -n flag sets the name of the stage, -d flag sets the dependencies of the stage, and -o flag defines the outputs of the stage. The python command at the end defines the command run by the stage itself. Additionally, there’s also the -m for metrics, and -p flag for parameters.
What are dvc.yaml and dvc.lock files?¶
DagsHub uses dvc.yaml and dvc.lock to generate the pipeline.
A good way to contextualize these two files is that they are fundamentally interconnected. They work in tandem: dvc.yaml holds the pipeline itself, and dvc.lock defines the version of the referred files within the pipeline.
So, what information do they provide? Let’s examine a single stage within the files to make necessary comparisons:
stages:
featurization:
cmd: python3 code/featurization.py
deps:
- code/featurization.py
- data/test_data.csv
- data/train_data.csv
outs:
- data/norm_params.json
- data/processed_test_data.npy
- data/processed_train_data.npy
schema: '2.0'
stages:
featurization:
cmd: python3 code/featurization.py
deps:
- path: code/featurization.py
md5: ddf63559873ad5aa352565bb3b76bf0b
size: 1472
- path: data/test_data.csv
md5: c807df8d6d804ab2647fc15c3d40f543
size: 18289443
- path: data/train_data.csv
md5: c807df8d6d804ab2647fc15c3d40f543
size: 18289443
outs:
- path: data/norm_params.json
md5: 855b3da318f0dfd5eb36d4765092473a
size: 138861
- path: data/processed_test_data.npy
md5: 48b7c5120556c80e0c2c08602b53a216
size: 1280128
- path: data/processed_train_data.npy
md5: 48b7c5120556c80e0c2c08602b53a216
size: 1280128
Within dvc.lock's deps, we see the path to the first dependency - featurization.py. Below it, we have the md5sum hash of the file, as well as the size of the file itself. This is how DVC knows the state of files within the stage, and how it decides whether or not to execute code for any given stage. The high-level stages from dvc.yaml is interpreted to design the pipeline itself.
How to run a DVC Pipeline?¶
Once your pipeline is prepared, you would have defined an end-to-end process for reproduction. When you change components and want to observe the consequent changes, running the pipeline updates only the modified stages, saving time and resources.
dvc repro is the primary command used to run the pipeline.
You can add stage names - for example, dvc repro featurization - and it will run the featurization stage. By default, stages are cached; which means, if there is no difference within the dependencies of the stage between runs, it will not run again.
Tip
To force a cached stage to run, use the -f tag!
Known Issues, Limitations & Restrictions¶
- Currently, DagsHub only supports DVC pipelines. If you have a request for a custom pipeline, please visit our suggestions channel Discord and share your request.
- GUI-based stage editing works only below DVC v1.x.