

Level 3 - Experimentation¶
Level overview¶
Now that we have a project and the raw data, the next step is to try different types of data processing and models to learn what works better.
In real life, this part is often where things get complicated, difficult to remember, track, and reproduce.
The data versioning we set up will help us keep track of data and model versions, and easily reproduce and share them. But how will we compare the different experiments we're going to run?
It's a sadly common tale, of a data scientist getting really good results with some combination of data, model, and hyperparameters, only to later forget exactly what they did and having to rediscover it. This situation gets much worse when multiple team members are involved.
This level of the tutorial shows how using DagsHub's integration with MLflow allows us to easily keep a reproducible record of our experiments, both for ourselves and for our teammates.
Too slow for you?¶
The full resulting project can be found here:
 See the project on DagsHub
See the project on DagsHub
Using MLflow to track experiments¶
We're now at a point where we can start experimenting with different models, hyperparameters, and data preprocessing. However, we don't have a way to record and compare results yet.
To solve this, we can use MLflow, which will record information about each of our experiments to the MLflow server provided with each DagsHub repository. Then, we can search, visualize, and compare our experiments on DagsHub.
MLflow is already installed since it was already included in our requirements.txt, so we can start right away with adjusting our code.
Tip
Alternatively, you can download the complete file here: main.py
Let's make the following changes to main.py:
-
Add two import lines to the top of the file:
import dagshub import mlflow -
Next, we want to authenticate to DagsHub, which also points MLflow to our repo. Add these lines after all the import statements:
DAGSHUB_REPO_OWNER = "<username>" DAGSHUB_REPO = "DAGsHub-Tutorial" dagshub.init(DAGSHUB_REPO, DAGSHUB_REPO_OWNER) -
Before we can log our experiments to MLflow, we need to either create an experiment or get an existing one. Add the following helper functions somewhere, which lets you do this:
def get_or_create_experiment_id(name): exp = mlflow.get_experiment_by_name(name) if exp is None: exp_id = mlflow.create_experiment(name) return exp_id return exp.experiment_id -
Now, modify the
train()function:def train(): print('Loading data...') train_df = pd.read_csv(train_df_path) test_df = pd.read_csv(test_df_path) print('Engineering features...') train_df = feature_engineering(train_df) test_df = feature_engineering(test_df) exp_id = get_or_create_experiment_id("tutorial") with mlflow.start_run(experiment_id=exp_id): print('Fitting TFIDF...') train_tfidf, test_tfidf, tfidf = fit_tfidf(train_df, test_df) print('Saving TFIDF object...') joblib.dump(tfidf, 'outputs/tfidf.joblib') mlflow.log_params({'tfidf': tfidf.get_params()}) print('Training model...') train_y = train_df[CLASS_LABEL] model = fit_model(train_tfidf, train_y) print('Saving trained model...') joblib.dump(model, 'outputs/model.joblib') mlflow.log_param("model_class", type(model).__name__) mlflow.log_params({'model': model.get_params()}) print('Evaluating model...') train_metrics = eval_model(model, train_tfidf, train_y) print('Train metrics:') print(train_metrics) mlflow.log_metrics({f'train__{k}': v for k,v in train_metrics.items()}) test_metrics = eval_model(model, test_tfidf, test_df[CLASS_LABEL]) print('Test metrics:') print(test_metrics) mlflow.log_metrics({f'test__{k}': v for k,v in test_metrics.items()})
Note
Notice the calls made to MLflow to log the hyperparameters of the experiment as well as metrics.
Commit the changed file:
git add main.py
git commit -m "Added experiment logging"
Now, we can run the first experiment which will be recorded:
python3 main.py train
Now, let's record this baseline experiment's parameters and results. Remember that since we trained a new model, our outputs have changed:
$ dvc status
outputs.dvc:
changed outs:
modified: outputs
So we should commit them to DVC before committing to Git:
dvc commit -f outputs.dvc
# DVC will change the contents of outputs.dvc, to record the new hashes of the models saved in the outputs directory
git add outputs.dvc
git commit -m "Baseline experiment"
Running a few more experiments¶
Now, we can let our imaginations run free with different configurations for experiments.
Here are a few examples (with a link to the code for them):
- We can change the type of model:
- AdaBoost model – main.py with AdaBoost
- Random Forest model – main.py with Random Forest
- We can play around with parameters:
- We can try out different values for random forest's
max_depthparameter – main.py with different max depth
- We can try out different values for random forest's
- Etc.
After each such modification, we'll want to save our code and models. We make sure to commit our code first, because MLflow will point any runs done to a particular commit, if run from a Git repository. This lets you match up code changes with experiment results.
We can do that by running a set of commands like this:
git add main.py
git commit -m "Description of the experiment"
python3 main.py train
dvc commit -f outputs.dvc
git add outputs.dvc
git commit -m "Results of the experiment"
git add main.py
git commit -m "Description of the experiment"
python3 main.py train
dvc commit -f outputs.dvc
git checkout -b "Experiment branch name" # We recommend separating distinct experiments to separate branches. Read more in the note below.
git add outputs.dvc
git commit -m "Results of the experiment"
git checkout master
Of course, it's a good (but optional) idea to change the commit message to something meaningful.
Branching strategy for experiments
It's often hard to decide what structure to use for your project, and there are no right answers – it depends on your needs and preferences.
Our recommendation is to separate distinct experiments (for example, different types of models) into separate branches, while smaller changes between runs (for example, changing model parameters) are consecutive commits on the same branch.
Visualizing experiments on DagsHub¶
To see our experiments visualized, we can navigate to the "Experiments" tab in our DagsHub repo:
If you want to interact with the experiments table of our pre-made repo, you can find it here.
Here is what our experiments table looked like at this stage, after running a few different configurations:
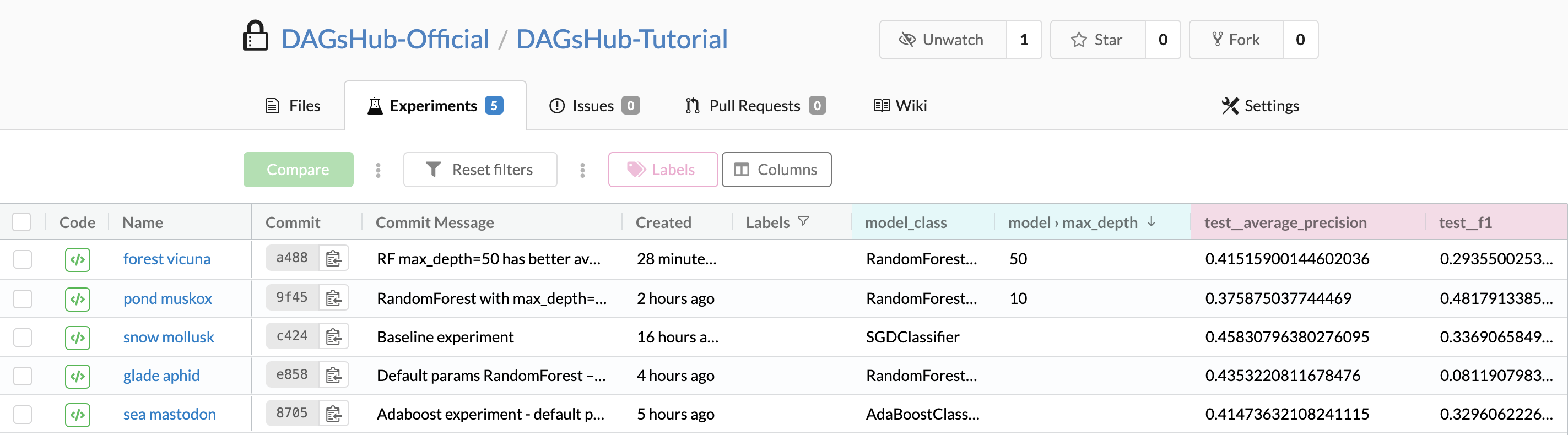
This table has a row for each detected experiment in your Git history, showing its information and columns for hyperparameters and metrics. Each of these rows corresponds to a single Git commit.
You can interact with this table to:
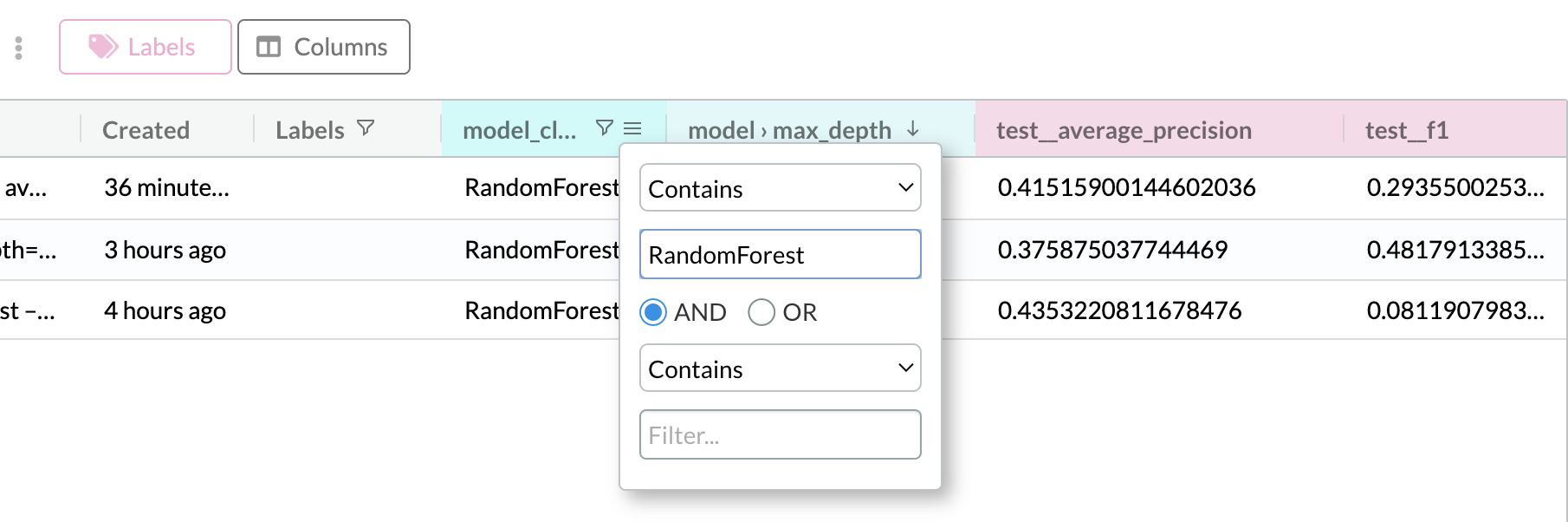
- Filter experiments by hyperparameters:
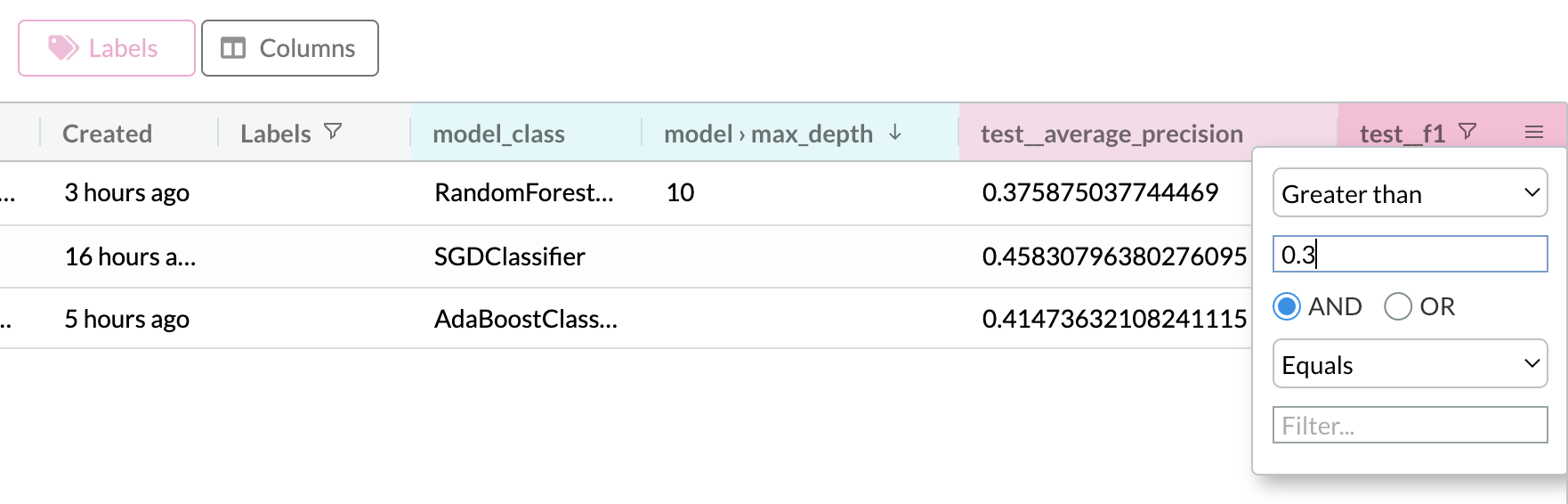
- Filter & sort experiments by numeric metric values - i.e. easily find your best experiments:
- Choose the columns to display in the table - by default, we limit the number of columns to a reasonable number:

- Label experiments for easy filtering.
Experiments labeledhiddenare automatically hidden by default, but you can show them anyway by removing the default filter.
- See the commit IDs and code of each experiment, for easy reproducibility.
- Select experiments for comparison.
For example, we can check the top 3 best experiments:
Then click on the Compare button to see all 3 of them side by side: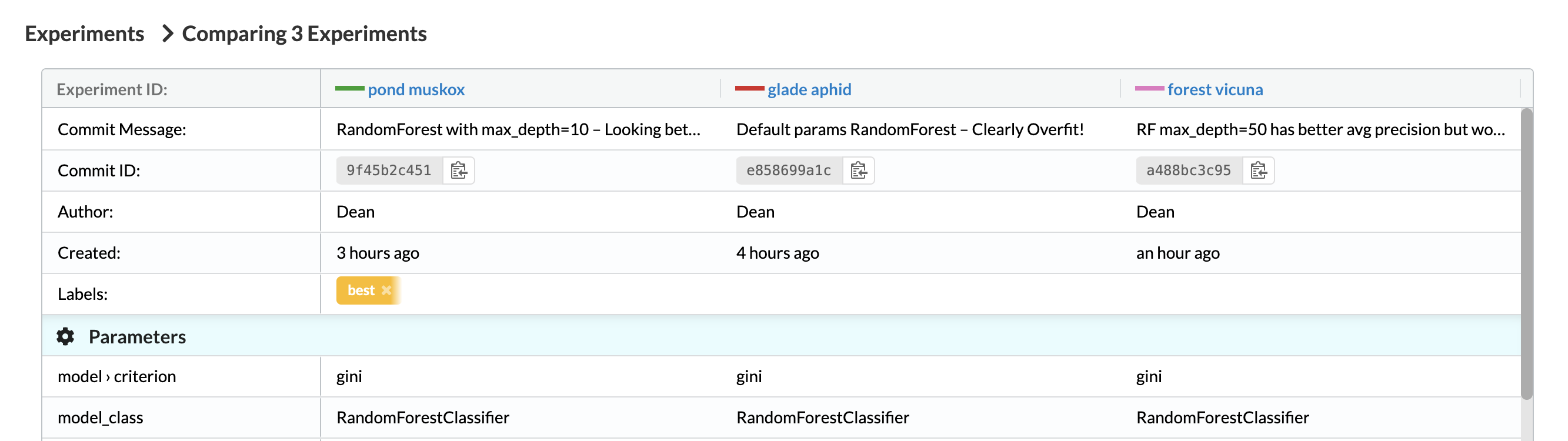

Next Steps¶
The next logical steps for this project would be to:
- Experiment more with data preprocessing and cleaning, and do so in a separate step to save processing time.
- Add more training data, and see if it improves results.
- Store the trained models & pipelines in a centrally accessible location, so it's easy to deploy them to production or synchronize with team members.
- Track different versions of raw data, processed data, and models using DVC, to make it easy for collaborators (and yourself) to reproduce experiments.
Stay tuned for updates to this tutorial, where we will show you how to implement these steps.
In the meantime, if you want to learn more about how to use DVC with DagsHub, you can follow our other tutorial, which focuses on data pipeline versioning & reproducibility.
