

Level 0 - Data Exploration¶
![]()
Level overview¶
This level of the tutorial covers downloading the data and performing some basic analysis of it to see what we have.
The full analysis can be found in this Colab notebook, but we'll go over the main points and conclusions together.
If you want to just skip ahead to the code, you can go straight to the next level.
Description of the data¶
Our data is a CSV file describing questions on the Cross Validated Stack Exchange, a Q&A site for statistics.
It was generated from the Stack Exchange API with this query. To make things easier for you, we already ran the query and saved its result in our public storage, so you can download it straight from here.
The data itself looks like this (click to get a full-size view):
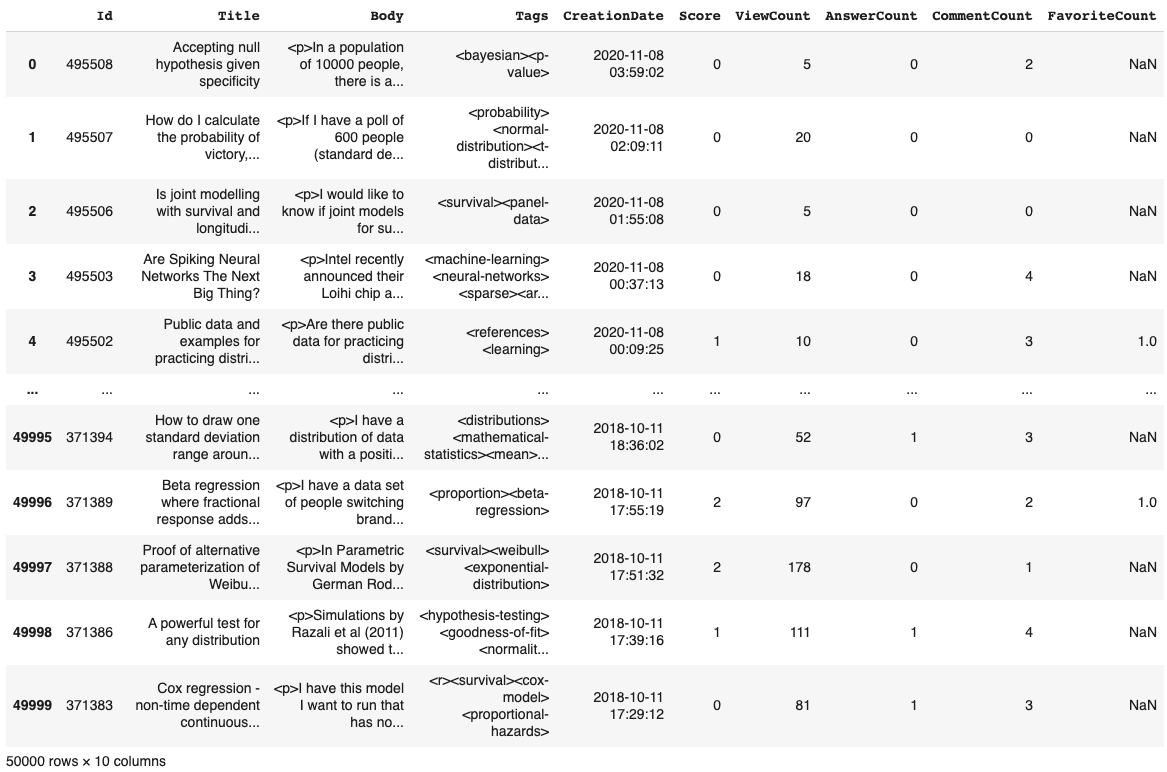
The columns are pretty self-explanatory - we have:
- Two textual features (
Title&Body).
We can already tell that this text is full of HTML tags, which we will probably need to clean to get good results.
- One string column that is the list of
Tagsfor this question. - Some numeric features:
Score, ViewCount, AnswerCount, CommentCount, FavoriteCount. - One
CreationDatefeature that needs to be processed correctly.
Our objective¶
Each question on Cross Validated can be labeled with a set of topic tags, to make it easier for experts to find & answer.
For this tutorial, our goal will be to predict whether a given Cross Validated question should be tagged as a machine-learning related question.
This is a supervised binary classification task, and the ground truth can be found in the Tags column:
df['MachineLearning'] = df['Tags'].str.contains('machine-learning')
One important thing to note is that only about 11.1% of the data is labeled positive. This means that we're dealing with an imbalanced classification problem, and we will need to take this into account when choosing our performance metrics, and possibly use special sampling strategies or model configurations.
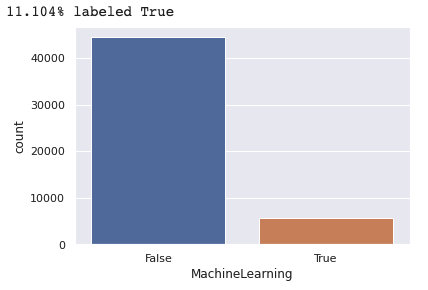
Conclusions from data exploration¶
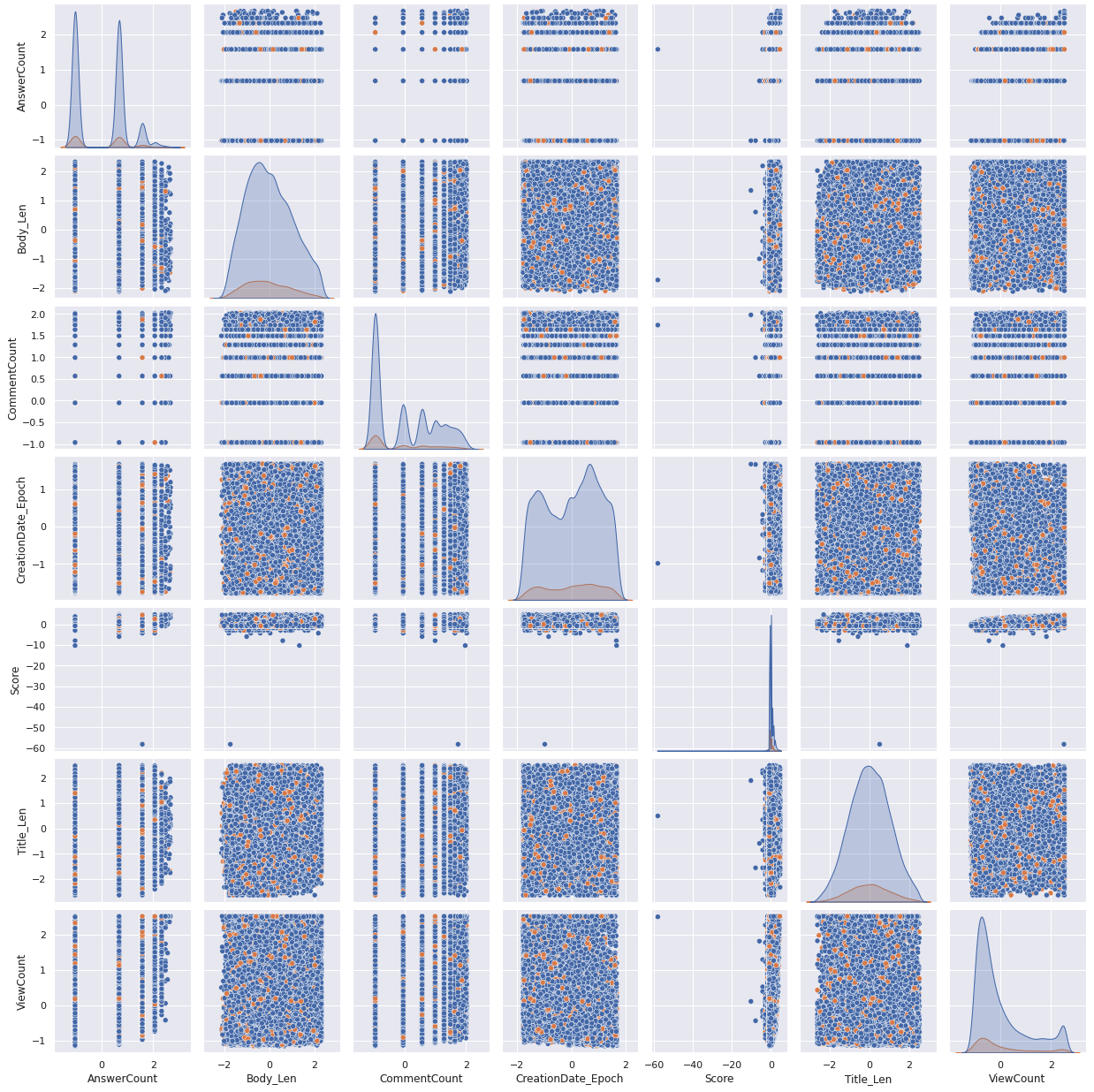
- Our label
MachineLearningis not too strongly related to any other single feature. - We should drop the
FavoriteCountcolumn since it's highly correlated withScoreand contains mostlyNaN. Score, ViewCount, AnswerCountare highly skewed, so we'll take that into account in data preparation.
Numeric features¶
After massaging the numerical features so that they're scaled and less skewed, here are their distributions (click to get a full-size view):
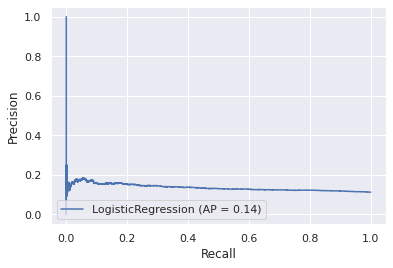
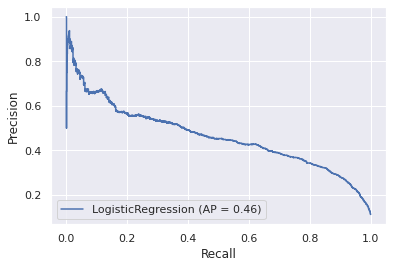
These scaled numerical features were good enough to train a simple logistic regression classifier, that performs only slightly better than random. This can be seen in the model's precision-recall curve:
Text features¶
It makes sense that most of the information on a question's topic will be contained in its text content.
To turn the two textual features of the data into something we can train an ML model on, we first concatenate them:
df['Text'] = df['Title'] + ' ' + df['Body']
And then train a TfidfVectorizer
using this text column. For now, we don't do any fancy text processing - we just use the default logic contained in TfidfVectorizer.
This is already enough to get a very decently performing model:
Looking at the terms learned by the trained TfidfVectorizer, we can note some possible directions for improvement:
- Various numbers, like
00,00000000eetc. It could be useful to prevent this splitting of numbers into many different terms in the vocabulary since it probably won't matter to classifying the text. - Multiple terms are grouped due to an underscore, like
variable_2. This is probably an artifact of embedded Python or TeX code. It might help the model if we break these down into separate terms. - Remember, the questions contain embedded HTML. While we're not seeing any terms that were clearly garbage created by HTML, it's a good bet that it will be useful to clean up the HTML tags in the text.
- Of course, there's room to experiment with different hyperparameters of the
TfidfVectorizer- vocabulary size, ngram range, etc.
Next steps¶
We got a good sense of our data, the type of preprocessing required, and managed to train some decent classifiers with it.
At this point in a Python data science project, it's common to take the conclusions and working code from the exploratory notebook, and turn them into normal Python modules. This enables us to more easily:
- Create reusable components that will be useful as the project matures.
- Use code versioning tools like Git.
- Make the process more reproducible by defining a clear pipeline (order of operations) for the data and model training.
- Automate running and tracking of experiments.
- Version our different experiments and models, so that we preserve knowledge and don't risk losing work by accident.
In the next level of this tutorial, we'll take what works from this notebook and turn it into a Python project, before going forward with data versioning and experimentation to find the best performing model for our problem.