How Creating Training-ready Datasets Faster Can Unleash ML Teams’ Productivity
- Noa Goldman
- 5 min read
- 3 years ago
Product Manager at heart. Noa’s forte is creating products specially made for engineers and tech-savvy geeks.

ML teams have a very important core purpose in their organizations - delivering high-quality, reliable models, fast. They are trusted to maintain and improve business outcomes by ensuring that their models will constantly improve, and perform without critical failures.
One of the most effective methods ML teams can use to quickly deliver high-quality models is to experiment with new datasets - collect large amounts of data from various places, find the use cases where your model is underperforming, zoom in to find the relevant data points, make this data training-ready, run an experiment, evaluate results, deploy to production in case the model’s performance was improved, and repeat - a complex process, filled with challenges from start to finish.
This process as a whole can be executed in many different ways like developing dedicated internal tools, product integrations, tons of scripting, or just manual work - all of which require a tremendous amount of time and effort, and mainly reduce productivity. With users’ productivity in mind, at DagHub we aimed for a solution that will provide ML teams with the whole process out of the box and with no extra effort.
This is how we came up with the Data Engine - an end-to-end solution for creating training-ready datasets and fast experimentation. Let’s explain how the Data Engine helps teams do just that.
Experimenting fast is both a virtue and a productivity hazard
As mentioned before, ML teams must experiment with new datasets to improve model performance, but this process can be resource-intensive.
Data collection is where the experiment begins
Any experiment process starts with data collection. The quality and quantity of the data can significantly impact a model's performance. ML engineers need access to a large and diverse data source that accurately represents the real-world scenarios they want the model to handle.
Insufficient or poor-quality data can lead to models that underperform or fail to generalize well. ML engineers need to spend significant time searching for or cleaning data while keeping everything organized and usable for the entire team, which reduces the time available for the important task - model improvements. Gathering high-quality and sufficient data can be time and effort-consuming.
Separating the wheat from the chaff in an ocean of data
To efficiently improve a model, ML teams have to experiment with relevant data - the data that represents use cases in which the model is underperforming - slicing and dicing the data to use only these specific data points out of an ocean of data that was previously collected.
The challenge of identifying underperforming use cases within a vast dataset negatively impacts ML engineer teams' productivity. Isolating relevant data points from a large pool of collected data is time-consuming, diverts focus, causes delays in model development, and hinders overall productivity.
Actually using your data
To be able to experiment with the relevant data, ML teams need to generate a high-quality dataset that can be used to train ML models effectively and efficiently. This involves data cleaning, transformation, and preprocessing, as well as ensuring appropriate labeling or annotation for supervised learning tasks.
Preparing and organizing data into a format suitable for training models presents significant challenges for ML teams. Data cleaning complexity, dealing with diverse data types, and preprocessing large volumes of data consumes time and resources. Balancing data preparation with actual model development becomes a productivity challenge, as it can lead to delays in experimentation and deployment.
Unleashing ML teams' productivity with Data Engine
Data Engine is a toolset built to make iterating on unstructured datasets easy by providing a seamless flow to create training-ready datasets. With users’ productivity on our mind, DagsHub created the Data Engine to allow ML teams to focus on what’s important - improving their models - by providing a seamless and intuitive flow that includes querying, visualizing, annotating relevant data points, and creating training-ready datasets to re-train your model.
Efficient Access to Diverse Data
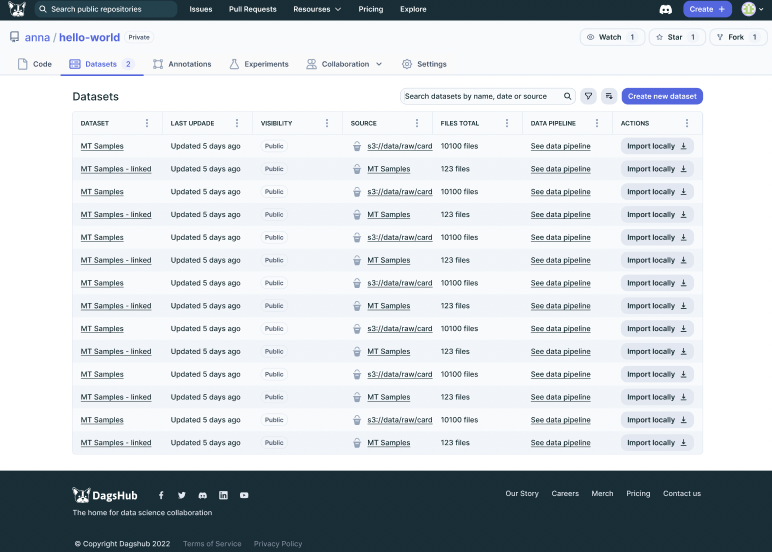
Through seamless integration with diverse data sources like S3, GCS, any S3 compatible storage, and even DVC remotes, Data Engine enables easy access to vast and varied datasets, saving valuable time and effort for ML engineers, and preventing unnecessary duplication of data. With Data Engine, ML teams can collect new data points to their storage of choice and add them into their Datasource. The platform automatically scans and provides a clear view of the data's status - which data points are new and when was the source last updated - ensuring data quality and reliability. Moreover, Data Engine offers the ability to save queries as new datasets, providing transparency on the data's origin and enabling accurate representation of real-world scenarios.
This high-quality and diverse dataset allows models to be trained effectively while saving valuable time and effort. ML teams can focus on refining models and driving improvements, accelerating model iteration speed, and boosting overall productivity.
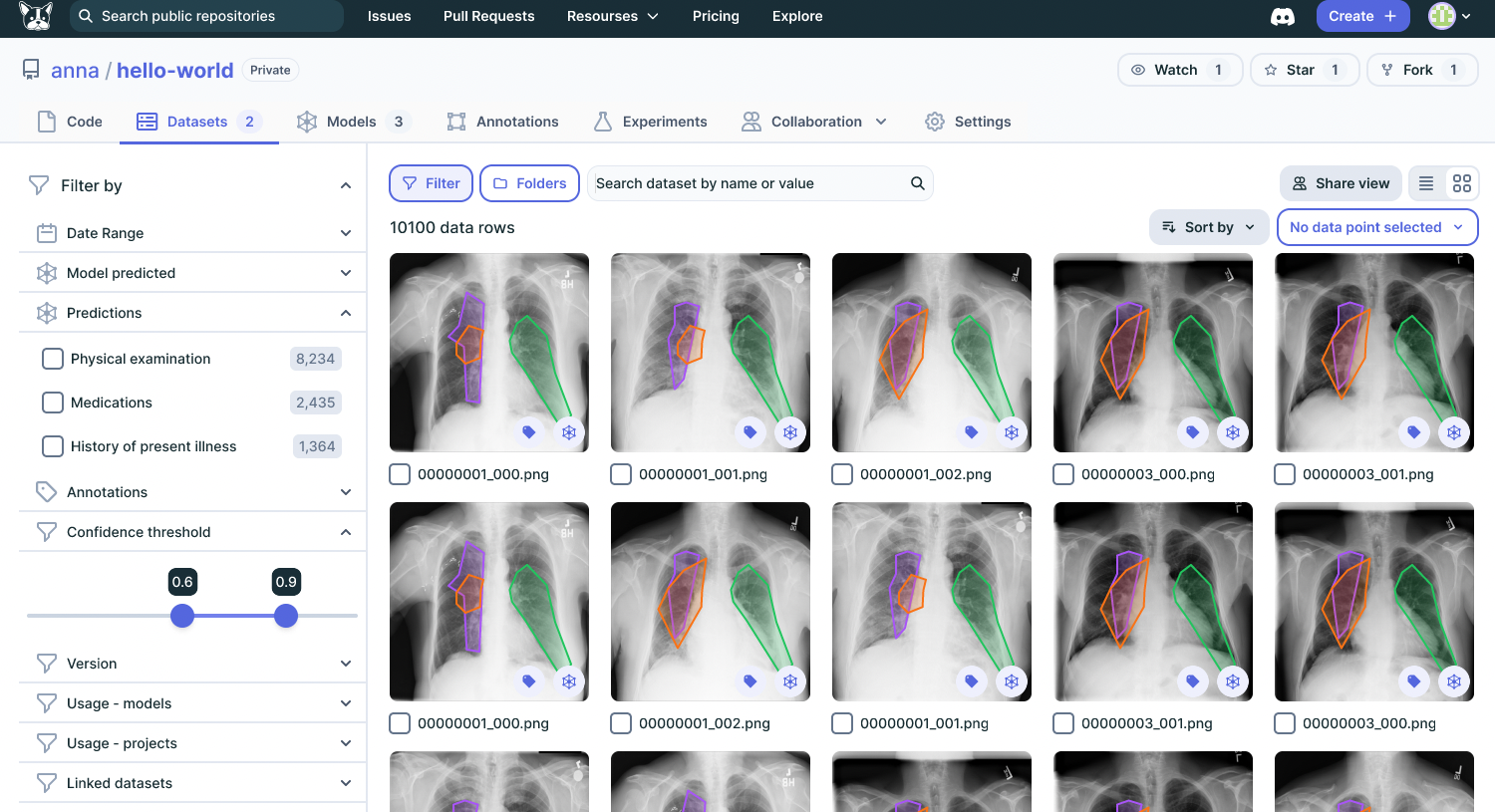
Targeting Data Selection for Underperforming Use Cases
Data Engine's seamless query and visualization capabilities allow ML teams to identify underperforming use cases within their datasets easily. With intuitive Pandas-like data queries that can be easily executed, ML teams can slice and dice their data, and zoom in only on the relevant data points. Knowing ML teams, we realize that sometimes there’s no replacement to visually inspect the data, this is why Data Engine provides out-of-the-box visualization for your datasets that include everything ML engineers need - from the actual data points to their enrichments; model predictions, metadata, and labels - to generate a new relevant dataset to experiment with.
By letting ML teams focus on specific data points relevant to model improvement, they can efficiently zoom in on critical aspects, saving time and effort spent searching for valuable insights in an ocean of data.
Seamless Data Usage for Model Training
Data Engine ensures that ML teams have a high-quality dataset readily available for model training. Automating data transformation and labeling facilitates smooth and efficient model development. ML engineers can focus on what they do best—create and improve their cutting-edge ML models.
In a Nutshell
DagsHub’s primary goal is to develop products that ML teams will find truly valuable and user-friendly. We deeply understand the mindset and workflow of ML engineers, which has driven us to create the Data Engine. By identifying the day-to-day tasks that consume significant time and effort, we have crafted an intuitive and seamless workflow that addresses these challenges.
Data Engine is a powerful tool that helps ML teams become more productive. It simplifies the process of collecting and organizing diverse data points, ensuring that real-world scenarios are well-represented in high-quality datasets. With automated data preparation and easy integration with various sources, ML teams can focus on refining their models and driving improvements. This speeds up the model iteration process and boosts overall productivity. By embracing Data Engine, ML teams can effortlessly navigate data complexities, revolutionize their daily tasks, and achieve remarkable results in the world of machine learning.
Try Data Engine’s end-to-end solution and experiment faster
Using Data Engine is easy and intuitive, check out our documentation and start experimenting fast.



