Top Computer Vision Generative Models in 2024
- Manuel Martin
- 17 min read
- 2 years ago
I like building ML systems that have a positive impact on the world. I also write about technical stuff. | Senior Data Scientist

Intro
Welcome to the comprehensive guide on the top computer vision generative models of 2024. As businesses continue to harness the power of generative AI, the impact on productivity and efficiency is undeniable, with a predicted global increase of 1.5%.
In this article, I collected the most innovative models that have been trending in recent months. We'll explore their exceptional quality, versatility across various applications, and help you decide how to improve your team's productivity and efficiency.
Moreover, the substantial investments in this technology and its side effects, highlighted by an 800 million dollar project halted from a notable figure like Tyler Perry, underscore the significant impact of these advanced tools. Whether you're looking to enhance your operational capabilities or seeking a competitive edge, understanding these key players in the generative AI landscape is essential.
Why Are Generative Models the Next Big Thing in Computer Vision?
Generative AI systems have ignited a revolution in the way people interact with technology. The way in which language models like ChatGPT have been boosted to provide a chat human-like interface for anyone with access to the internet has been the key to this paradigm shift that has already had a large economic impact. We can already see evidence in the stock market, venture capital investments on start-ups, and daily news of how every company is adopting Generative AI technology in various ways.
With the advent of generative computer vision and large language models, multi-modality has emerged as a very natural interface to humans. These models not only interpret what you say and respond to you coherently, but they can also create as well as understand visual content, all by using AI. A lot of the excitement is mainly driven by the vast opportunities to increase productivity by automating tasks, but also to level up creative image-based tasks such as in design, marketing, advertising, and so on.

Different systems like OpenAI’s Dall-E for text-to-image generation, SORA for text-to-video generation, GPT-4V with multimodal abilities, Stability AI’s Stable Diffussion 3 and MidJourney are the most relevant examples.
Top Computer Vision Models to Watch Out For
As a brief historical introduction to why the field has evolved so quickly in recent years, it is worth highlighting the following architectures and the papers in which they were first published:
- Variational Autoencoders: VAEs, introduced by Diederik P.Kingma and Max Welling in 2013.
- Generative Adversarial Networks: GANs, created by Ian Goodfellow in 2014.
- Diffusion Models: Jascha Sohl-Dickstein in Deep Unsupervised Learning using Nonequilibrium Thermodynamics in 2015.
- Vision Transformers (ViTs): Vision Transformer (ViT) architecture, introduced by Dosovitskiy et al. in 2020
These discoveries have paved the way for a very prolific era for researchers, open source contributors, and engineers to push the boundaries of the computer vision field. In this blog, we will delve exactly into that exciting new era of high quality and diverse landscape of generative computer vision models that are shaping the future of image and video synthesis.
These models represent a frontier in the automation and enhancement of visual tasks. From product design and marketing to advanced surveillance systems just to name a few. They offer unparalleled efficiency and creativity. They can automate the generation of visual content, significantly reducing the time and cost associated with traditional methods, and provide insights from visual data at a scale previously unattainable. For businesses, this means faster time-to-market for new products, more engaging and personalized marketing campaigns, and enhanced decision-making capabilities through visual analytics. Moreover, as industries increasingly rely on digital and visual interfaces to interact with their customers, mastering these technologies becomes a competitive necessity, enabling companies to stay ahead in innovation and customer engagement.
1. DALL-E 3
Original paper: Improving Image Generation with Better Captions
Company: OpenAI
Website: https://openai.com/dall-e-3
Architecture
The latest architecture of DALL-E 3 hasn’t been fully disclosed. But if we take a look at DALL-E 2, we see that it employs a two-stage process. The initial stage involves a variational autoencoder (VAE) that encodes images into a lower-dimensional latent space, facilitating efficient manipulation.
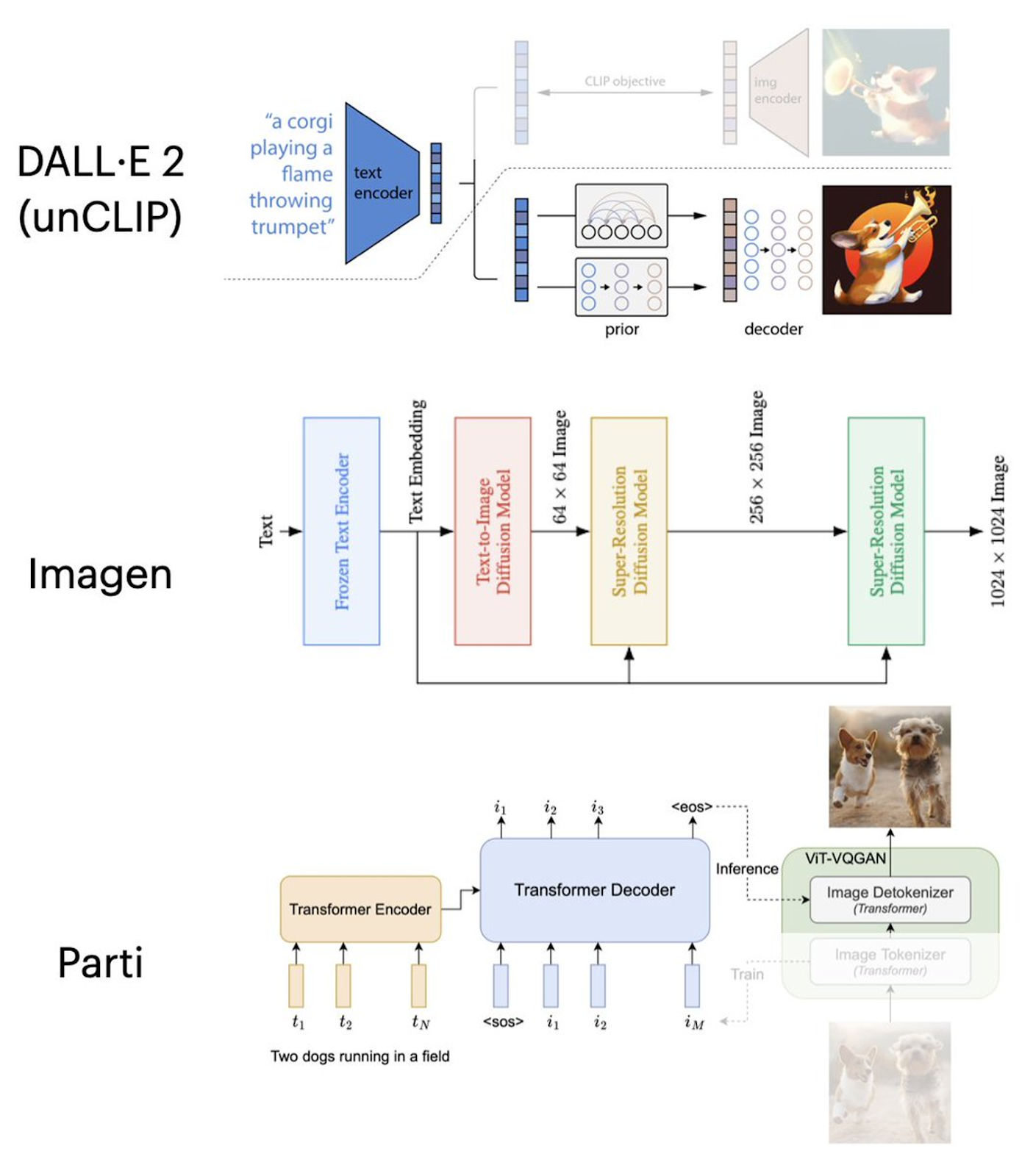
DALL-E 3 is an AI system that takes text prompts and generates images. It is built upon the GPT-3 model, a transformer-based language model.
Trained on text-image pairs, DALL-E 3 can create images based on textual descriptions by sequentially generating tokens to form the image. The model can manage object characteristics, spatial relations, viewpoints, orientations, and even blend diverse concepts to create unique objects.

One key difference with predecessors is that DALL-E 3 uses a bespoke image captioning model trained by OpenAI team to recaption the training dataset with synthetic data. When training the text-to-image models with these data they discovered that the performance of prompt following abilities improved greatly.
Pros
- Precision: DALL-E 3 excels in understanding and translating textual descriptions into highly detailed and accurate images.
- Safety Measures: Incorporates safety features to prevent the generation of harmful or inappropriate content like violence or adult material.
- Ethical Considerations: OpenAI collaborates with experts to test and mitigate biases, ensuring responsible and reliable image generation.
Cons
- Complex Prompts: While precise, the success of image generation can depend on the specific phrasing of the prompt.
- Object Confusion: As the number of objects increases, DALL-E 3 may struggle with connections between objects and their colors.
2. Stable Diffusion 3
Original paper: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Company: Stability AI
Website: https://stability.ai/news/stable-diffusion-3

Architecture
While detailed architecture specifics for Stable Diffusion 3 (SD3) were not directly outlined in the initial query results, it can be inferred that SD3 continues to evolve from its predecessors by enhancing its text-to-image synthesis capabilities.
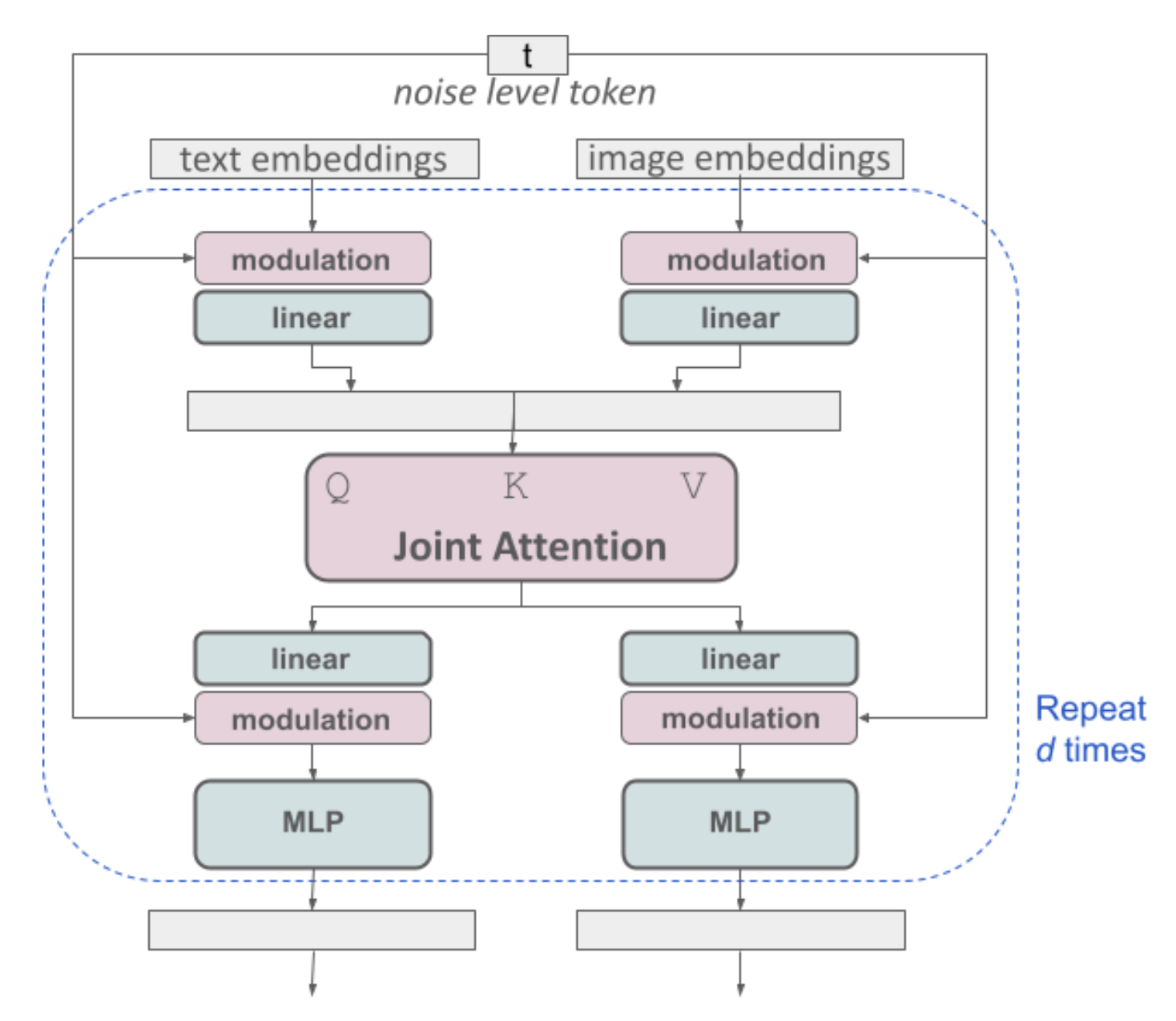
The architecture likely builds on rectified flow transformers, optimizing for high-resolution image synthesis through improved noise sampling techniques and a transformer-based approach that allows for a bidirectional flow of information between text and image tokens. This innovative approach employs separate weights for the two modalities, improving text comprehension and image quality.
Pros
- Improved Performance: SD3 demonstrates superior capabilities in handling detailed prompts, producing high-resolution images that maintain a strong adherence to the provided text, showcasing enhanced prompt understanding and image quality.
- Flexibility and Efficiency: The model has been optimized to reduce memory requirements significantly, removing the need for a memory-intensive text encoder during inference without considerably impacting performance.
- Scalability: The architecture shows predictable scaling trends, meaning improvements correlate directly with increased model size, which has not yet reached a performance plateau.
- Realism and Detail: SD3 excels in generating images with fine detail and photorealism, surpassing previous models in creating visually appealing and authentic-looking images.
Cons
- Reduced Text Adherence Without T5 Encoder: Removing the T5 text encoder to save memory impacts the model's ability to adhere closely to textual prompts, especially affecting typography generation.
- Potential for Misuse: While not directly mentioned, the power of generative AI models like SD3 invariably comes with the risk of misuse, such as generating misleading or harmful content. Ensuring responsible use is a critical ongoing concern.

3. Midjourney V2
Original paper: N/A
Company: Midjourney
Website: https://www.midjourney-v6.com/
Architecture
Similar to DALL-E 3, the architecture of Midjourney V6 is not disclosed. It introduces several enhancements over its predecessors, focusing on generating more lifelike and detailed images. It has improved its core algorithms for enhanced realism, more coherent prompt responses, and the integration of in-image text capabilities.

Key features include two new upscalers for higher resolution outputs, a style mode for raw, less opinionated results, and an improved ability to follow longer and more detailed prompts.
Pros
- Enhanced Realism: V6 significantly pushes the boundaries of photorealism in AI-generated art, making the images it produces more detailed and lifelike.
- Improved Prompt Coherence: The model has been fine-tuned to follow prompts more accurately, capable of handling longer and more complex inputs efficiently.
- In-Image Text Capability: A notable advancement in V6 is the ability to include legible text within the images, adding a new dimension of creativity and functionality.
- Advanced Upscaling: The introduction of improved upscaling options enhances the resolution of generated images, offering outputs that are more refined and visually appealing.
Cons
- In-Image Text Imperfections: While the in-image text feature marks a significant improvement, it is not perfect. The system performs well with common words but may struggle with less familiar terms or phrases, requiring multiple attempts to achieve the desired result
4. Imagen 2
Original paper: N/A
Company: Google Deepmind
Website: https://deepmind.google/technologies/imagen-2/
Architecture
Imagen 2 represents Google DeepMind's most sophisticated evolution in text-to-image diffusion models, designed to produce high-quality, photorealistic outputs that faithfully reflect the user's prompts. The architecture builds upon its predecessor by integrating:

- A large frozen T5-XXL encoder to transform input text into embeddings, which a conditional diffusion model then uses to generate a base image at a resolution of 64×64 pixels. This process is further refined through text-conditional super-resolution diffusion models that incrementally upscale the image to resolutions of 256×256 and finally to 1024×1024 pixels.
- Enhanced image-caption understanding is achieved by adding more descriptive details to image captions in the training dataset, helping the model better grasp a broader range of user prompts and the nuances within them.
- The model also incorporates specialized image aesthetics models based on human preferences to condition Imagen 2 towards generating images that align with human-like qualities of good lighting, framing, exposure, sharpness, etc..
- Fluid style conditioning and advanced inpainting and outpainting capabilities allow for more creative control over the style and editing of generated images, with the system capable of integrating new content into original images or extending them beyond their initial borders.
Pros
- Photorealism: Imagen 2 excels at generating high-fidelity, photorealistic images closely aligned with user prompts, outperforming other models in quality and detail.
- Enhanced Detail Processing: It shows remarkable improvement in accurately rendering complex details, particularly in challenging areas like human hands and faces.
- Style Flexibility: Users can easily manipulate the style of generated images, thanks to the model's advanced conditioning capabilities.
- Editing Capabilities: Imagen 2 enables inpainting and outpainting, allowing for significant editing and customization of images.
Cons
- Accessibility and Open Use: Google has decided not to release the code or a public demo of Imagen 2 due to the potential risks of misuse, limiting access to the broader research and developer community.
- Social and Cultural Biases: Preliminary internal assessments reveal that Imagen 2 may encode harmful stereotypes and biases, particularly in generating images of people, activities, events, and objects.
- Quality Variation: While Imagen 2 generates more lifelike images, its performance may vary, particularly when portraying people, where it can sometimes struggle with image fidelity.
5. Dreamlike Photoreal
Dreamlike Photoreal 2.0 (https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0) leverages the Stable Diffusion 1.5 architecture as its foundation, emphasizing photorealism and the integration of photographic elements into prompts. The model is tailored for high-resolution image synthesis, with a training focus on 768×768 pixel images. Its architecture supports efficient scaling to higher resolutions, maintaining image quality and detail. The incorporation of server-grade A100 GPUs accelerates the image generation process, enabling the model to handle multiple images simultaneously without compromising on speed or quality.
Pros:
- High-Resolution Image Synthesis: The model's training on 768×768 pixel images and its ability to efficiently scale to higher resolutions ensure it can produce high-quality, detailed images. This is particularly beneficial for applications requiring fine detail and clarity.
- Photorealistic Outputs: Emphasizing photorealism and the integration of photographic elements into prompts means the model is capable of generating images that closely mimic real-life photographs. This makes it suitable for tasks where realistic image generation is paramount.
- Based on Stable Diffusion 1.5 Architecture: Leveraging a proven architecture ensures reliability and the potential for broad application. Stable Diffusion is known for its balance of quality and generation speed, providing a solid foundation for Dreamlike Photoreal 2.0.
- Efficient Scaling: The model's architecture supports efficient scaling to higher resolutions without a significant loss in image quality or detail. This scalability is crucial for diverse applications, from digital art
Cons:
- High Computational Resources Required: The utilization of server-grade A100 GPUs for accelerating the image generation process implies that significant computational resources are necessary. This may not be as accessible or cost-effective for individuals or smaller organizations without access to such hardware.
- Potential for Overfitting to Photorealistic Styles: While the emphasis on photorealism and photographic elements enhances realism, it could limit the model's versatility in generating abstract or stylistically diverse images. This focus might not cater to users seeking more artistic or non-photorealistic outputs.
- Complexity in Prompt Engineering: Given the model's sophistication and focus on high-resolution, photorealistic images, users may face a learning curve in crafting effective prompts that fully leverage its capabilities. This could present a barrier to entry for less experienced users.
- Possible Ethical and Misuse Risks: The ability to create highly realistic images raises ethical concerns, particularly regarding the creation of deepfakes or misleading content. Users and platforms will need to consider safeguards and ethical guidelines to prevent misuse.
- Scalability vs. Cost Trade-off: While the model is designed for efficient scaling to higher resolutions, the associated costs in terms of computational resources and processing time could rise significantly. This may impact the feasibility of large-scale projects or iterative design processes where rapid generation is required.

This architectural setup is optimized for real-world applications requiring rapid generation of photorealistic images with complex details.
Top Text-to-Video Models to Watch Out
6. Runway Gen-2
Company: Runway
Web: https://research.runwayml.com/gen2
Architecture: Runway's Gen-2 model, part of their AI video generation offerings, is a diffusion model that generates videos from text prompts or existing images. It was trained on a dataset of 240 million images and 6.4 million video clips.

Pros:
- It's one of the first commercially available text-to-video models, providing around 100 seconds of free video generation.
- Gen-2 passes a surface-level bias test, showing a bit more diversity in the content it generates compared to some other models.
Cons:
- Videos suffer from low frame rates, resulting in almost slideshow-like appearances in some cases.
- Generated clips often have a graininess or fuzziness, and there are issues with consistency regarding physics or anatomy.
- The model struggles with understanding nuance in prompts, sometimes focusing on specific descriptors while ignoring others.
Examples:
7. Pika Labs 1.0
Company: Pika Labs
Web: https://pika.art/about
Architecture: Pika 1.0 is designed as an "idea-to-video" model, allowing users to start with various inputs such as text, an image, or a video clip and transform them into something new. It aims to make video creation simpler and more accessible.
Pros:
- The model supports a wide range of content, including 3D animations, live-action clips, and cinematic videos.
- Offers extensive customization options, including frame rate adjustments, aspect ratio changes, and motion element tweaks.
Cons:
- Early tests showed inconsistencies in video output quality, with some results being blurred or subjects appearing deformed.
- There may be limitations in the model's current ability to fully realize the user's vision without additional refinement and updates.
Examples:
- Introducing Pika 1.0, An Idea-to-Video Platform
- Pika Labs 1.0! Everything you NEED to know in 4 mins
- Pika 1.0 Complete Guide for Beginners! - Best Free Ai Video Generator
8. Open AI Sora
Company: OpenAI
Web: https://openai.com/sora
Architecture: Sora, developed by OpenAI, stands out with its use of a diffusion transformer model. It generates high-definition videos up to a minute long, improving upon issues like occlusion and maintaining consistent style across cuts.

Sora is built on an adapted version of the DALL-E 3 technology, combining a diffusion model with a transformer to process video data similarly to textual data.
Pros: Capable of producing detailed high-definition videos with complex camera motions and multiple characters, demonstrating a significant leap in video generation technology.
Cons: Despite its advancements, Sora struggles with simulating complex physics, understanding causality, and differentiating left from right. It also restricts prompts for certain types of content in line with safety practices.
Each of these models showcases the rapid advancement in text-to-video generation technology, offering a range of tools for creative professionals and enthusiasts alike. However, they also reflect ongoing challenges in achieving consistent quality, realism, and understanding of nuanced prompts.
Examples:
- Introducing Sora — OpenAI’s text-to-video model
- OpenAI Sora’s first short film - "Air Head," created by shy kids.
9. Meta Emu
Original Paper: Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Company: Meta
Web: https://www.google.com/search?q=meta+emu&sourceid=chrome&ie=UTF-8
Architecture: Emu Video, introduced by Meta, implements a novel approach to text-to-video generation utilizing diffusion models. The process is bifurcated into two stages: initially generating an image based on text, and subsequently producing a video by integrating both the text and the previously generated image.

This factorized method simplifies the video generation process, avoiding the necessity for a deep cascade of models that previous systems required. Emu Video operates using just two diffusion models to produce videos of 512x512 resolution at 16 frames per second, each four seconds long.
Pros:
In human evaluations, Emu Video significantly outperformed previous models such as Google's Imagen Video, NVIDIA’s PYOCO, and Meta’s own Make-A-Video, showcasing a preference in both quality and faithfulness to the text prompt. Specifically, it was favored over Make-A-Video by 96% of respondents for quality and by 85% for faithfulness to the prompt. The model's ability to animate user-provided images based on text prompts set new benchmarks, demonstrating superior performance compared to prior works.
Cons:
While detailed cons specific to Emu Video were not highlighted in the sources, general challenges in AI-generated content include potential issues with achieving perfect realism, especially with complex scenarios or highly detailed prompts, and ensuring the ethical use of such technology to avoid the creation of misleading or harmful content.
Examples:
10. Google Lumiere
Original Paper: Lumiere: A Space-Time Diffusion Model for Video Generation
Company: Google
Web: https://lumiere-video.github.io/
Architecture: Google's Lumiere is a text-to-video diffusion model that stands out for its innovative approach to video synthesis, employing a Space-Time U-Net architecture. This model generates the entire temporal duration of the video in one pass, contrasting with conventional methods that synthesize keyframes and then fill in gaps for motion, often leading to inconsistencies. It down- and up-samples both spatially and temporally, processing the video in multiple space-time scales, directly generating full-frame-rate, low-resolution videos before upscaling for final output.

This method allows Lumiere to maintain global temporal consistency across videos, a notable advancement over previous models that might only ensure local continuity between keyframes.
Pros
- High-Quality Outputs: Lumiere can produce high-quality, realistic videos directly from text prompts or still images, achieving state-of-the-art results in text-to-video generation.
- Versatility: The model supports a wide range of content creation tasks, including image-to-video, video inpainting, and stylized generation, making it a powerful tool for various video editing applications.
- Temporal Consistency: Unlike other models, Lumiere generates videos by considering both spatial and temporal dimensions simultaneously, resulting in smoother and more coherent videos without the common issues of error accumulation or hallucinogenic artifacts seen in other approaches.
Cons:
- Computational Demand: The complex architecture and the process of generating videos through space-time down- and up-sampling could potentially demand high computational resources, although specific details on computational efficiency are not extensively discussed.
- Limited Public Testing: As of the latest updates, Google has not widely released Lumiere for external testing, and the preprint detailing its architecture and capabilities has not undergone peer review. This means that the broader research and developer community has had limited access to evaluate its performance and limitations thoroughly.
- Sample Size and Diversity: The evaluation of Lumiere's capabilities, based on a dataset of 30 million videos with text captions, could be seen as limited by the diversity and representativeness of these datasets for real-world applications. Also, the model's performance has been primarily showcased through demos and selected prompts, which may not fully represent its capabilities across a broader range of scenarios.
Examples:
- Introducing Lumiere: A space-time diffusion model for video generation
- Googles New Text To Video BEATS EVERYTHING (LUMIERE)
Use Cases of Visual Generative AI Models
Visual generative AI has transformed sectors such as the creative industries, healthcare, autonomous driving, and future tech innovations. It enables the generation of original art and efficient product designs in the creative sphere, elevating creativity and streamlining workflows.
In healthcare, it aids in precise diagnostics and surgery by enhancing image analysis and offering virtual practice environments, thus improving accuracy and safety.
Autonomous vehicles rely on AI for real-time data processing, navigation, and obstacle detection, enhancing responsiveness to changing conditions. Looking ahead, AI promises advances in environmental protection, bespoke entertainment, and intuitive interfaces, suggesting a future where AI amplifies human visual creativity and decision-making.
Yet, this growth brings challenges like ethical biases, environmental impacts of AI training, and the debate over specialized versus generalized models. Tackling these issues involves developing more refined algorithms, utilizing diverse data, and adopting green computing and renewable energy in AI training. Research is directed towards creating versatile models, enhancing learning processes, ensuring content consistency, and refining evaluation techniques. Overcoming obstacles in content integration, audio matching, and improving model transparency and management remains crucial, highlighting the need for progress in bias identification and mitigation to ensure equitable AI use.
This evolving domain highlights the critical role of cross-disciplinary cooperation in AI development, focusing on leveraging AI's benefits responsibly while addressing its ethical and practical complexities.
Conclusion
In 2024, businesses are finding exciting ways to use generative AI models like DALL-E 3 and Stable Diffusion 3 to innovate and solve problems creatively. These tools are game-changers for industries ranging from marketing and design to product development, allowing companies to generate unique visuals or videos quickly and efficiently. This not only speeds up the creative process but also opens up new avenues for engaging with customers and standing out in the market. For instance, companies can create custom content for advertising campaigns or design prototypes at a fraction of the time and cost it used to take.
These examples we just mentioned are the most obvious. But the range of possibilities and opportunities is wide and even the most niche business can leverage what this technology can offer. Not only from a productivity improvement point of view but also as an idea amplifier. Personalized end-to-end experiences can only scale by using Generative AI. Whether you want to create a movie tailored to your interests, design the interior of your living room according to your home style or learn about a specific topic taking into account your background, the power of generating content in any possible form is essential.
In the upcoming years, there are several challenges ahead. Making this technology accessible for every type of business remains the essential cornerstone. This tradeoff will be a limiting factor for some years, but leaders need to start preparing their companies to adapt to this imminent paradigm shift to stay ahead of the competition.



