Datasets should behave like git repositories
- Simon Lousky
- 7 min read
- 6 years ago
Developer @ DAGsHub
Problems emerging from data are common in research as well as in the industry. Those problems are dealt with as part of our project, but we usually don't bother solving them at their origin. We fix the data locally once, and we go on with our project. This is certainly a valid method in some cases, but as we share data more and more between projects, we are finding ourselves repeating the same processes over time and across teams. This issue is particularly true for public datasets shared by many people to train many machine learning models. I will show you how to create, maintain, and contribute to a long-living dataset that will update itself automatically across projects, using git and DVC as versioning systems, and DAGsHub as a host for the datasets.
Iterations over my dataset
Changing datasets is a common process
I remember that during my undergraduate studies, I had to generate an instance segmentation model for cucumber plant parts, using a custom dataset of segmented leaves, cucumbers, and flowers. At a very early stage, I discovered I couldn't get reasonable results with the data given initially. I decided I would fix the annotations myself on about a dozen pictures. As expected, this solved 80 percent of the issues I was having. This is a good opportunity to say that manual data labor is underrated. Investing a few hours in fixing the data was the best thing I could do for the project. Then, of course, I went on with my life, leaving the fixed dataset on the lab computer, but knowing that eventually, my fixes were going to vanish.
Naturally, this process was gradual. I started with the original dataset, then I fixed a part of the annotations. At some point, I added completely new pictures, decided to redo some of them. I iterated over the data with multiple manipulations over time. Many of them I treated as "Debug trial-and-errors", naturally not keeping track of my working directory rigorously. During those iterations, I ran training sessions, while doing my best to keep a detailed record of my "experience". If you are still reading, you probably understand exactly what I am talking about. Well, the world has changed since then, and many data versioning tools have evolved to help. This is a good opportunity to recommend this comparison between data version control tools we published at the end of 2020.
What is data versioning?
While my project was a total mess data-wise, its code was very well tracked by git. The reason is that I could just run the following magical commands that everyone knows:
git add .
git commit -m "fixed training input directory"
Back then I wasn't able to do any magical command of that sort for my data. Now, with DVC and DAGsHub in the world, this is no longer the case. There is no reason on earth why you should not at least have a simple code and data versioning system set in place. If you are not familiar with DVC, I recommend you go through this basic data versioning tutorial, but it is not a prerequisite to understand the rest of this post. All you really need to know is that now we have a new, magical command:
dvc commit
That will create a snapshot of the tracked data, without inflating your git repository.
Introducing living datasets
While data versioning solves the problem of managing data in the context of your machine learning project, it brings with it a new approach to managing datasets. This approach, also described as data registries here, consists of creating a git repository entirely dedicated to managing a dataset. This means that instead of training models on frozen datasets - something researchers, students, kagglers, and open source machine learning contributors often do - you could link your project to a dataset (or to any file for that matter), and treat it as a dependency. After all, data can and should be treated as code, and follow through a review process. You can read more about that in another post about data bugs and how to fix them.
Warning - Don't continue reading if you feel threatened by knowledge!

I am joking, of course, this isn't going to be rocket science at all. In fact, I will demonstrate how to use such a living-dataset in a project similar to my university project.
Creating a data registry to use it as a living-dataset
In order to demonstrate this new concept of living-datasets, I have set one up myself, as well as a machine learning model using it as a dependency.
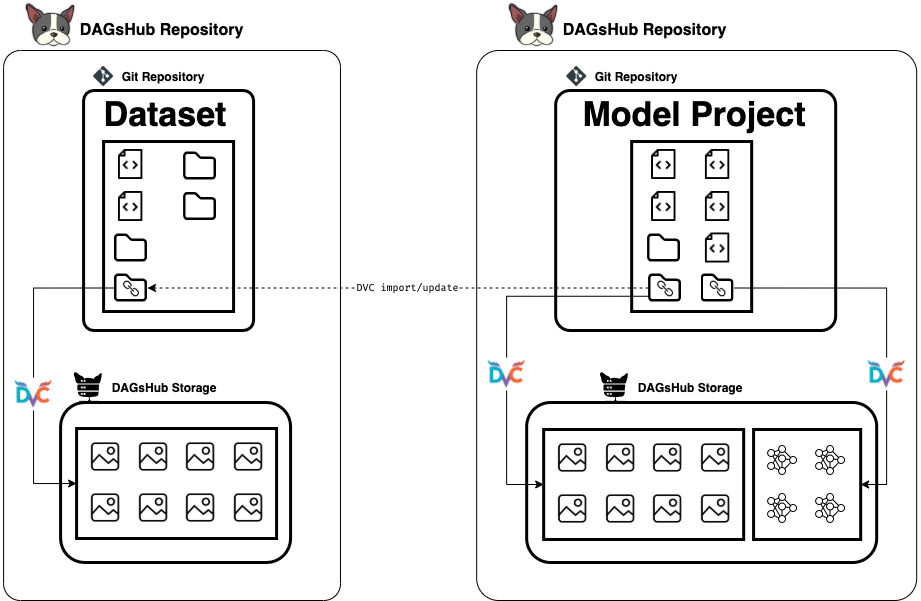
Repository A - AKA the living dataset, is going to be a simple project, with magical metadata files that point to real big files stored in a dedicated storage. I can organize the dataset files into directories, add code files with utils functions to work with it, or whatever I see fit to store and present my dataset to whoever might want to consume it.
Repository B - AKA the machine learning project, is where I want to use the files stored in my living-dataset. This repository will import a directory from Repository A using DVC, and this will do the trick of having that directory manageable and updatable.
To create a data registry, just create a git + DVC directory.
mkdir my-dataset && cd my-dataset
git init
dvc init
Congrats! Your living-dataset is alive. Now we need to add some files to it.

In my case, I took a handful of screenshots from a beloved TV Show, and annotated my favorite character in it, using the awesome open source COCO annotator project.
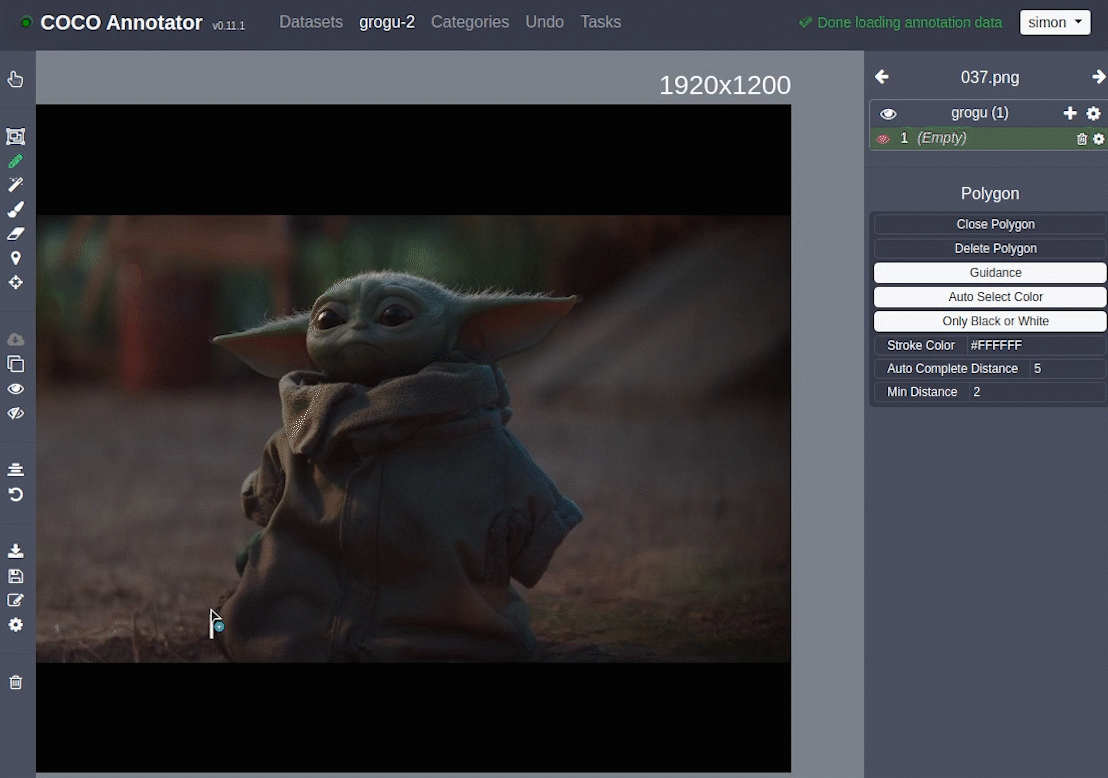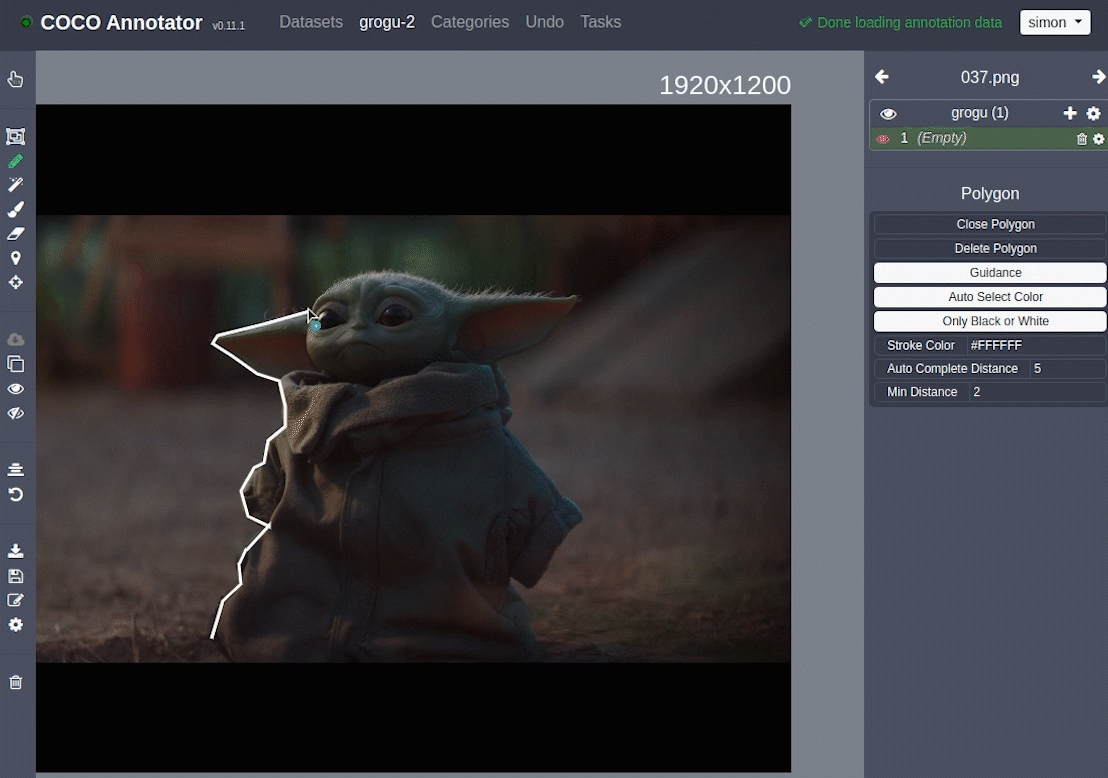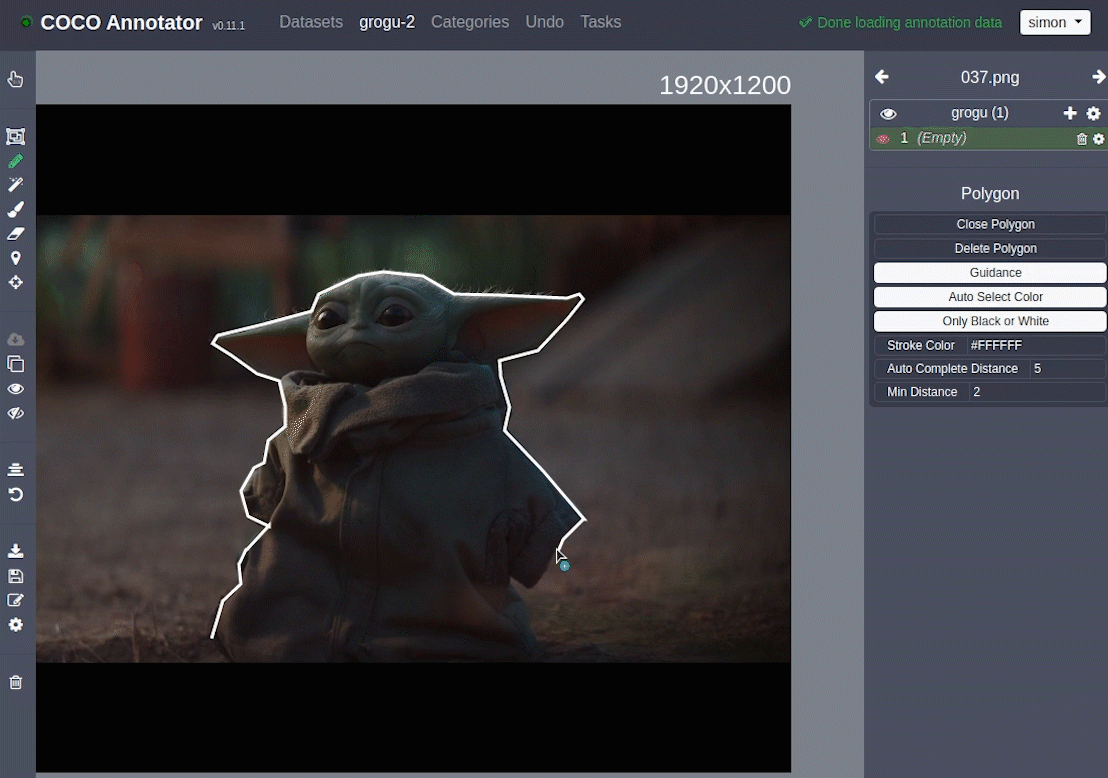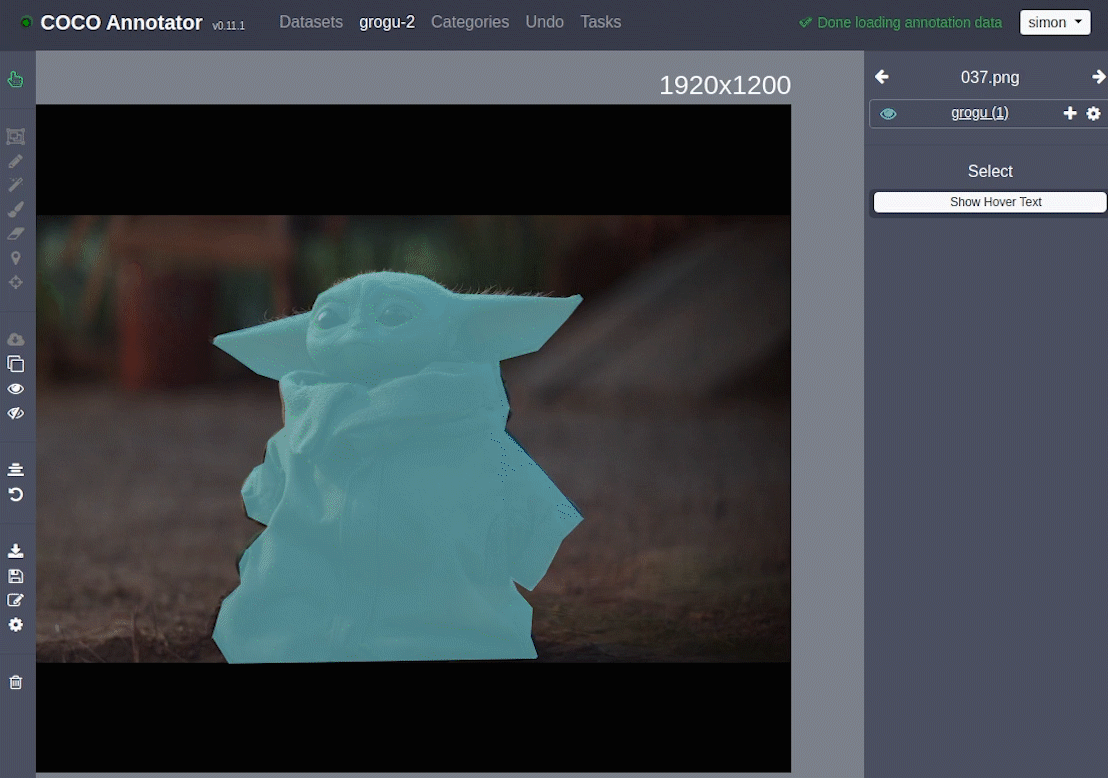
After annotating around 40 pictures, I knew it was going to be enough for a pre-trained Mask-RCNN with a ResNet50 backbone, to give decent results (15 would have probably been enough too, but it was too fun to stop). I exported a .json annotation file, put it in my repository along with the screenshots I took. At this point my working directory looked like this:
.
├── annotations
│ └── grogu.json
└── images
├── 000.png
├── 001.png
.
.
.
├── 206.png
└── 208.png
Then I ran the magic commands to start tracking the data files.
dvc add annotations
dvc add images
git add . && git commit -m "Starting to manage my dataset"
Since I like visualizations I wrote a script in this python notebook to render previews of my dataset into a preview directory, which will also be tracked by DVC. Then I just push my code and data to my remote repository, so that I can access it from everywhere, and share it with my collaborators.
git push origin master
dvc push -r origin
Note: I skipped the part of opening a repository on GitHub / DAGsHub and setting up the remote storage, the tutorial should cover that.
Using a living-dataset in a machine learning project
Now it is time to use my dataset as a dependency in my machine learning project. I will not be able to recreate my cucumber project from school, since I do not have access to the data, so I will substitute the cucumbers with the beloved fictional character from above.
I want my project directory to look like the following:
.
├── data
│ ├── preprocessed
│ └── raw
└── src
I want to import a directory from my dataset and treat it as raw files. I can do it by running from inside my repository:
mkdir -p data/raw
dvc import -o data/raw/images \
https://dagshub.com/Simon/baby-yoda-segmentation-dataset \
data/images
dvc import -o data/raw/annotations \
https://dagshub.com/Simon/baby-yoda-segmentation-dataset \
data/annotationsThis will specifically download the directories images and annotations from inside my dataset repository, and keep information on how to continue tracking the changes made in it. More on tracking the changes will be explained later, but this is pretty much it.
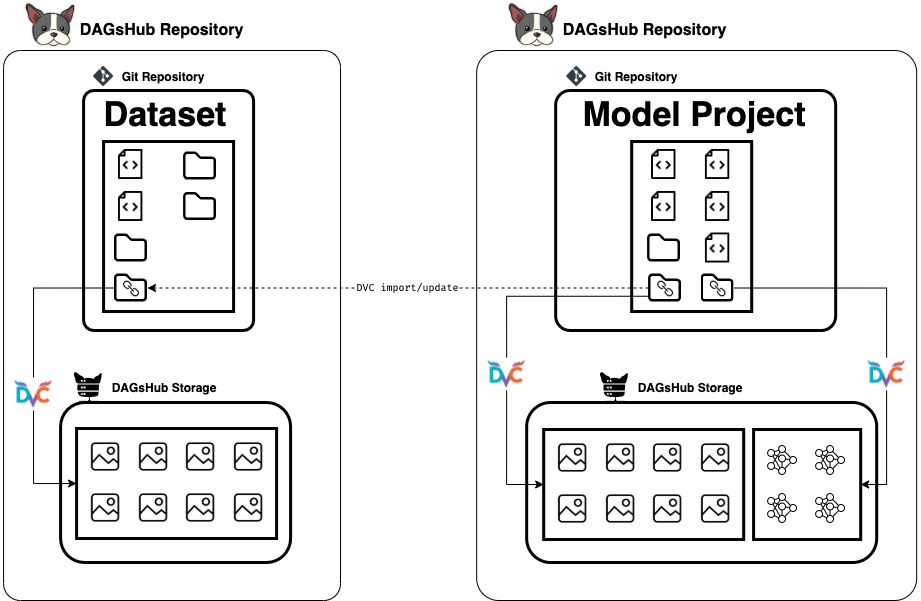
In the chart above you can see a representation of how it works. The arrows go in the direction of dependencies. Every time I know the dataset has changed, I just run the command
dvc update
The command above will check for changes in the tracked ref of the repository, and pull them to my local directories. Then I re-run my pipeline from scratch - Train my model, save the best one, and commit my results. Notice that we can use this method of dvc import + dvc update to get the output model as a dependency in another project if we wanted to.
A call for collaboration
First, I want to thank you for reading along, I hope you enjoyed it. The project is still a work in progress (but what project isn't?). So if you find mistakes, or improvements to make, either in the dataset or the model, then just contribute to them! It's fairly easy to fork repositories, pull the data, push it, and merge it. Especially with data-science pull requests. The process can easily be adapted to any segmentation dataset, so feel free to do so as well.
Special thanks to Asher and Or, my fellow students from the original segmentation project that gave me inspiration for this mini-project.
Here are some results just for fun!




