Comparing Data Version Control Tools - 2020
- Guy Smoilovsky
- 7 min read
- 6 years ago
Co-Founder & CTO @ DAGsHub

Whether you’re using logistic regression or a neural network, all models require data in order to be trained, tested, and deployed. Managing and creating the data sets used for these models requires lots of time and space, and can quickly become muddled due to multiple users altering and updating the data.
This can lead to unexpected outcomes as data scientists continue to release new versions of the models but test against different data sets. Many data scientists could be training and developing models on the same few sets of training data. This could lead to many subtle changes being made to the data set, which can lead to unexpected outcomes once the models are deployed.
This blog post discusses the many challenges that come with managing data, and provides an overview of the top tools for machine learning and data version control.
The Challenges of Data Management
Managing data sets and tables for data science and machine learning models requires a significant time investment from data scientists and engineers. Everything from managing storage, versions of data, and access require a lot of manual intervention.
Storage Space
Training data can take up a significant amount of space on Git repositories. This is because Git was developed to track changes in text files, not large binary files. So if a team's training data sets involve large audio or video files, this can cause a lot of problems downstream. Each change to the training data set will often result in a duplicated data set in the repositories’ history. This not only creates a large repository but also makes cloning and rebasing very slow.
Data Versioning Management
When trying to manage versions, whether it be code or UIs, there is a widespread tendency— even among techies—to “manage versions,” by adding a version number or word to the end of a file name. In the context of data, this means a project might include data.csv, data_v1.csv, data_v2.csv, data_v3_finalversion.csv, etc. This bad habit is beyond cliché, with most developers, data scientists, and UI experts in fact starting out with bad versioning habits.

Multiple Users
When working in a production environment, one of the greatest challenges is dealing with other data scientists. If you’re not using some form of version control in a collaborative environment, files will get deleted, altered, and moved; and you will never know who did what. In addition, it will be difficult to revert your data to its original state. This is one of the biggest obstacles when it comes to managing models and datasets.
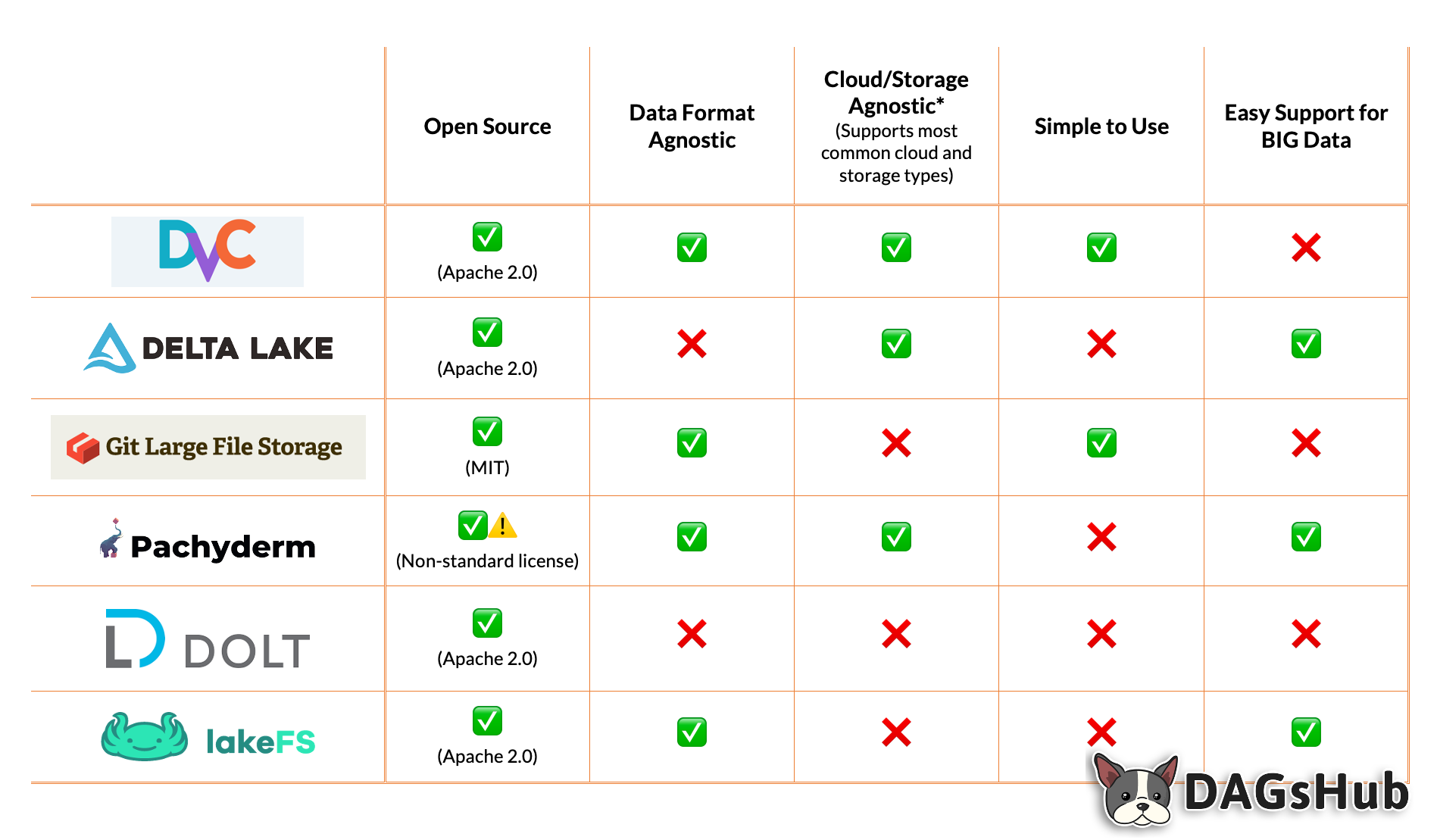
Reviewing the Best Data Version Control Alternatives
Data versioning is one of the keys to automating a team's machine learning model development. While it can be very complicated if your team attempts to develop its own system to manage the process, this doesn’t need to be the case.
Let’s explore six great, open source tools your team can use to simplify data management and versioning.
DVC
DVC, or Data Version Control, is one of many available open-source tools to help simplify your data science and machine learning projects. The tool takes a Git approach in that it provides a simple command line that can be set up with a few simple steps. DVC doesn’t just focus on data versioning, as its name suggests. It also helps teams manage their pipelines and machine learning models. In the end, DVC will help improve your team's consistency and the reproducibility of your models.
Pros
- Lightweight, open-source, and usable across all major cloud platforms and storage types.
- Flexible, format and framework agnostic, and easy to implement.
Cons
- DVC version control is tightly coupled with pipeline management. This means if your team is already using another data pipeline tool, there will be redundancy.
- DVC is lightweight, which means your team might need to manually develop extra features to make it easy to use.
Delta Lake
Delta Lake is an open-source storage layer to help improve data lakes. It does so by providing ACID transactions, data versioning, metadata management, and managing data versions.
The tool is closer to a data lake abstraction layer, filling in the gaps where most data lakes are limited.
Pros
- Offers many features that might not be included in your current data storage system, such as ACID transactions or effective metadata management.
- Reduces the need for hands-on data version management and dealing with other data issues, allowing developers to focus on building products on top of their data lakes instead.
Cons
- Delta Lake is often overkill for most projects as it was developed to operate on Spark and on big data.
- Requires using a dedicated data format which means it is less flexible and not agnostic to your current formats.
- Tool’s primary purpose is to act more like a data abstraction layer, which might not be what your team needs and can detour developers in need of a lighter solution.
Git LFS
Git LFS is an extension of Git developed by a number of open-source contributors. The software aims to eliminate large files that may be added into your repository (e.g., photos and data sets) by using pointers instead.
The pointers are lighter weight and point to the LFS store. Thus when you push your repo into the main repository, it doesn’t take long to update and doesn’t take up too much space.
This is a very lightweight option when it comes to managing data.
Pros
- Integrates easily into most companies' development workflows.
- Utilizes the same permissions as the Git repository so there is no need for additional permission management.
Cons
- Git LFS requires dedicated servers for storing your data. This, in turn, eventually leads to your data science teams being locked in as well as increased engineering work.
- Git LFS servers are not meant to scale, unlike DVC, which stores data into a more general easy-to-scale object storage like S3.
- Very specific and may require using a number of other tools for other steps of the data science workflow.
Pachyderm
Pachyderm is one of the few data science platforms on this list. Pachyderm’s aim is to create a platform that makes it easy to reproduce the results of machine learning models by managing the entire data workflow. In this regard, Pachyderm is “the Docker of data.”
Pachyderm leverages Docker containers to package up your execution environment. This makes it easy to reproduce the same output. The combination of both versioned data and Docker makes it easy for data scientists and DevOps teams to deploy models and ensure their consistency.
Pachyderm has committed itself to its Data Science Bill of Rights, which outlines the product’s main goals: reproducibility, data provenance, collaboration, incrementality, and autonomy, and infrastructure abstraction.
These pillars drive many of its features and allow teams to take full advantage of the tool.
Pros
- Based on containers, which makes your data environments portable and easy to migrate to different cloud providers.
- Robust and can scale from relativity small to very large systems.
Cons
- More of a learning curve due to so many moving parts, such as the Kubernetes server required to manage Pachyderm’s free version.
- With all the various technical components, it can be difficult to integrate Pachyderm into a company’s existing infrastructure.
Dolt
Dolt is a unique solution as far as data versioning goes. Unlike some of the other options presented that simply version data, Dolt is a database.
Dolt is an SQL database with Git-style versioning. Unlike Git, where you version files, Dolt versions tables. This means you can update and change data without worrying about losing the changes.
While the app is still new, there are plans to make it 100% Git- and MySQL-compatible in the near future.
Pros
- Lightweight and partially open source.
- SQL interface, making it more accessible for data analysts compared to more obscure options.
Cons
- Dolt is still a maturing product in comparison to other database versioning options.
- Dolt is a DB, which means you must migrate your data into Dolt in order to get the benefits.
- Built for versioning tables. That means that it won’t cover other types of data (e.g images, freeform text).
LakeFS
LakeFS lets teams build repeatable, atomic, and versioned data lake operations. It's a newcomer on this scene, but it packs a punch. It provides a Git-like branching and version control model that is meant to work with your data lake, scaling to Petabytes of data.
Similar to Delta Lake, it provides ACID compliance to your data lake. However, LakeFS supports both AWS S3 and Google Cloud Storage as backends, which means it doesn't require using Spark to enjoy all the benefits.
Pros
- Provides advanced capabilities such as ACID transactions for easy-to-use cloud storage such as S3 and GCS, all while being format agnostic.
- Scales easily, supporting very large data lakes. Capable of providing version control for both development and production environments.
Cons
- LakeFS is a relatively new product, so features and documentation might change more rapidly compared to other solutions.
- Focused on data versioning, which means you will need to use a number of other tools for other steps of the data science workflow.
Do You Really Need Data Versioning?
For all the benefits of data versioning, you don’t always need to be investing a huge effort in managing your data. For example, much of data versioning is meant to help track data sets that change a great deal over time.

Some data, like web traffic, is only appended to. Meaning that data is added but rarely if ever changed. This means that the data versioning that is required to create reproducible results is the start and end dates. This is important to note, as in such cases, you might be able to avoid all the setup of the tools referenced above. You will still need to manage the start and end dates to ensure you’re testing on the same data every time, as well as the models you are creating. However, in these cases you won’t necessarily need to commit all the data to your versioning system.
Summary
Managing data versions is a necessary step for data science teams to avoid output inconsistencies.
Whether you use Git-LFS, DVC, or one of the other tools discussed, some sort of data versioning will be required. These data versioning tools can help reduce the storage space required to manage your data sets while also helping track changes different team members make. Without data versioning tools, your on-call data scientist might find themselves up at 3 a.m. debugging a model issue resulting from inconsistent model outputs.
Yet all of this can be avoided by ensuring your data science teams implement a data versioning management process.



