7 Best Machine Learning Workflow and Pipeline Orchestration Tools 2024
- Eryk Lewinson
- 11 min read
- 2 years ago
Book Author, Tech Writer | Senior Data Scientist

In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines. These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment.
In this article, we will first briefly explain what ML workflows and pipelines are. Then, we will provide an overview of the best tools currently available on the market. Some of these were developed by big tech companies such as Google, Netflix, or Airbnb. Each of these tools is used by hundreds of companies (tech and non-tech!) around the world to streamline their data and ML pipelines. By the end of this article, you will be able to identify the key characteristics of each of the selected orchestration tools and pick the one that is best suited for your use case!
A primer on ML workflows and pipelines
Before exploring the tools, we first need to explain the difference between ML workflows and pipelines.
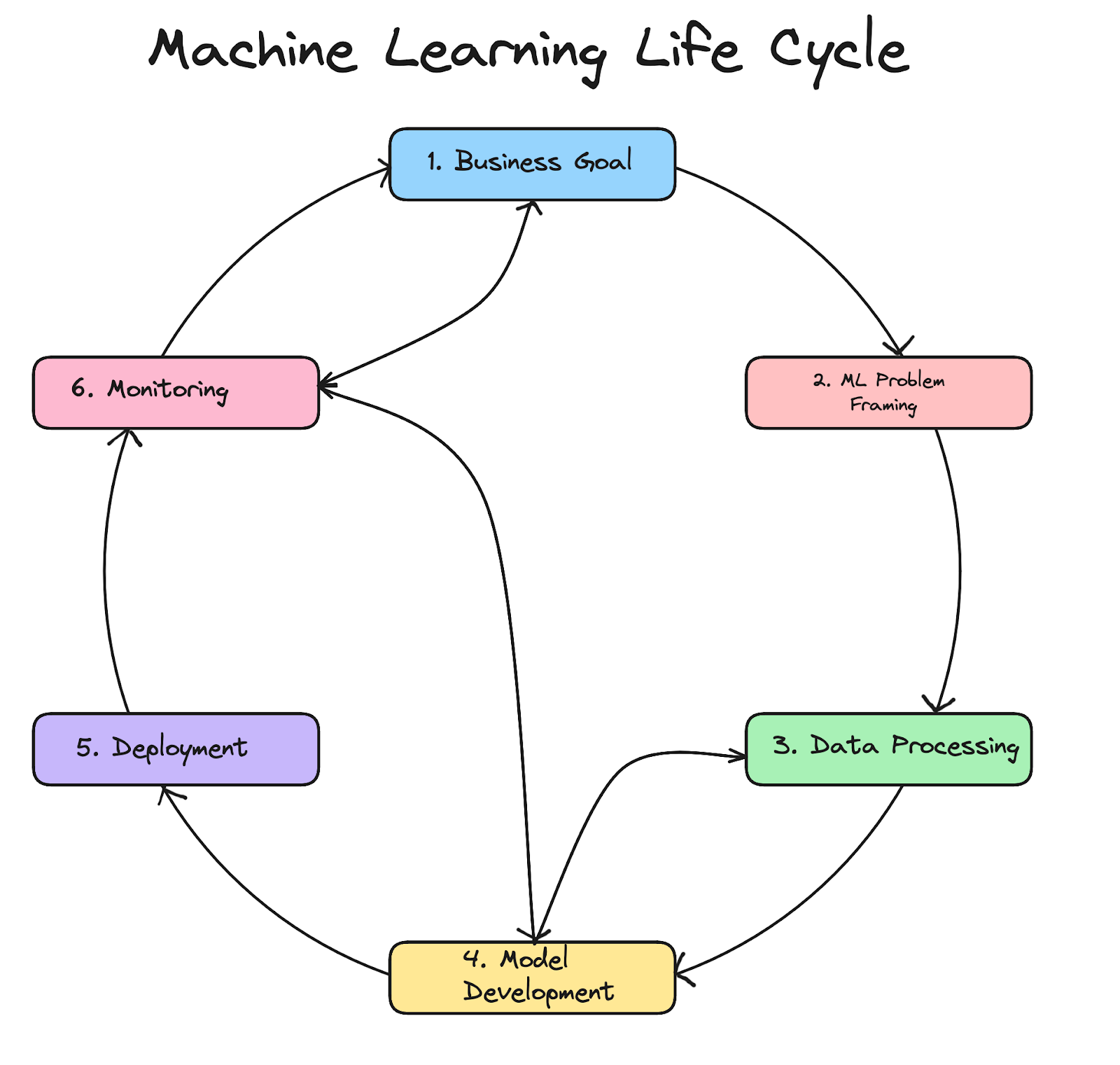
A machine learning workflow refers to the sequence of steps or tasks involved in the entire process of building a machine learning model. A typical workflow consists of several steps, such as data collection, data preprocessing (which includes data cleaning, transformation, and feature engineering), and all the steps connected to the model itself: model selection, training, evaluation, hyperparameter tuning, deployment, and finally monitoring.
In essence, workflows help organize and structure the machine learning project, making it easier to manage and iterate on different aspects of model development.
On the other hand, a machine learning pipeline is a sequence of components that define the machine learning workflow. Each component in the pipeline receives input data, performs some transformation or calculation, and then passes the output to the next component. These components not only include data processing steps, but also cover various stages related to model development.
The key advantages of building ML pipelines include:
- Workflows are reproducible and consistent across different datasets, experiments, and collaborators.
- It is much easier and faster to move the ML project to the production phase.
- As the workflows are mostly automated, the data science team can focus more on developing new solutions instead of maintaining the existing ones.
- Some components of the pipelines, such as data processing steps or hyperparameter tuning, can be reused for other projects.
To summarize, ML workflows represent the sequence of tasks involved in building an end-to-end machine learning project. Pipelines represent a specific implementation of that workflow.
Orchestration tools
Now that we understand what ML workflows and pipelines are, let's explore orchestration tools. These tools provide frameworks and interfaces that enable us to create and manage the infrastructure of workflows and their pipelines.
As you will soon discover, there are many ML workflow and pipeline orchestration tools available on the market. As such, selecting a solution for a project or organization may be a daunting task, and we might face choice overload. When making this decision, we should consider the following characteristics of the tools:
- Closed- or open-source
- Maturity
- Scalability
- Flexibility
- Ease of use
- Integration
- Community support and documentation
- Enterprise-friendliness or readiness
- Cost
- Programming language
The best orchestration tools
In this section, we will go over the most popular orchestration tools available on the market. One thing to mention up front: the order does not reflect any kind of ranking or preferences!
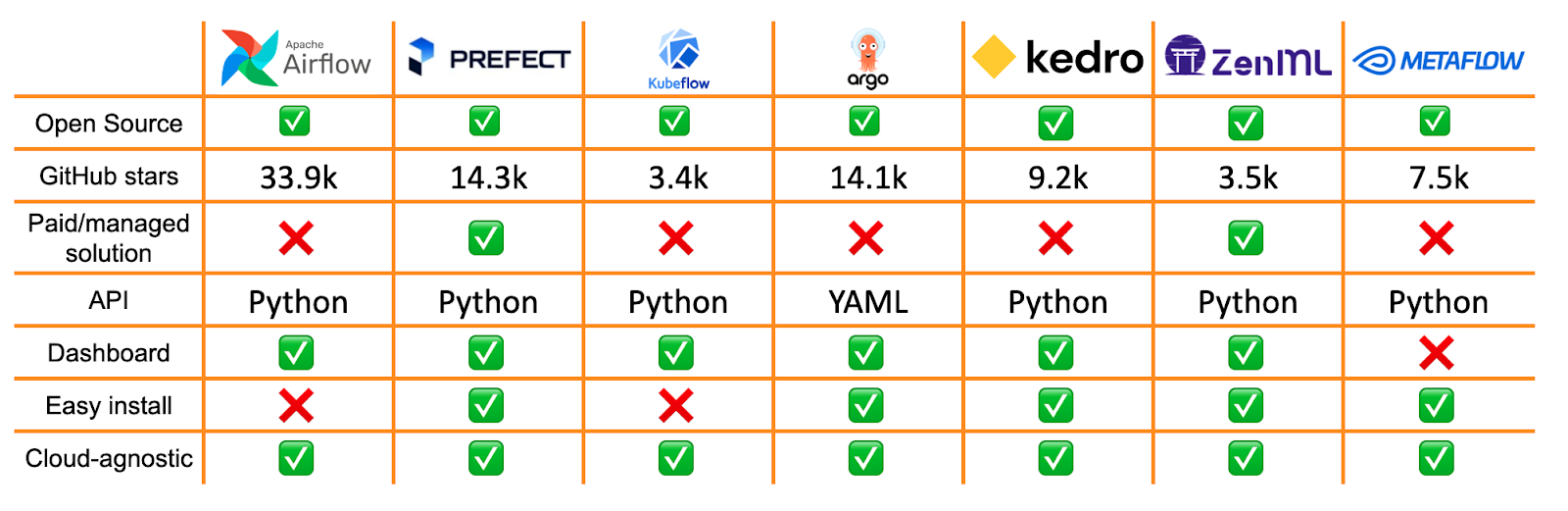
Before you start looking into the specific tools, you can find a summary table containing the most important information on the covered orchestration tool. Hopefully, you can use it as a cheatsheet that will help you make a decision for your next project!
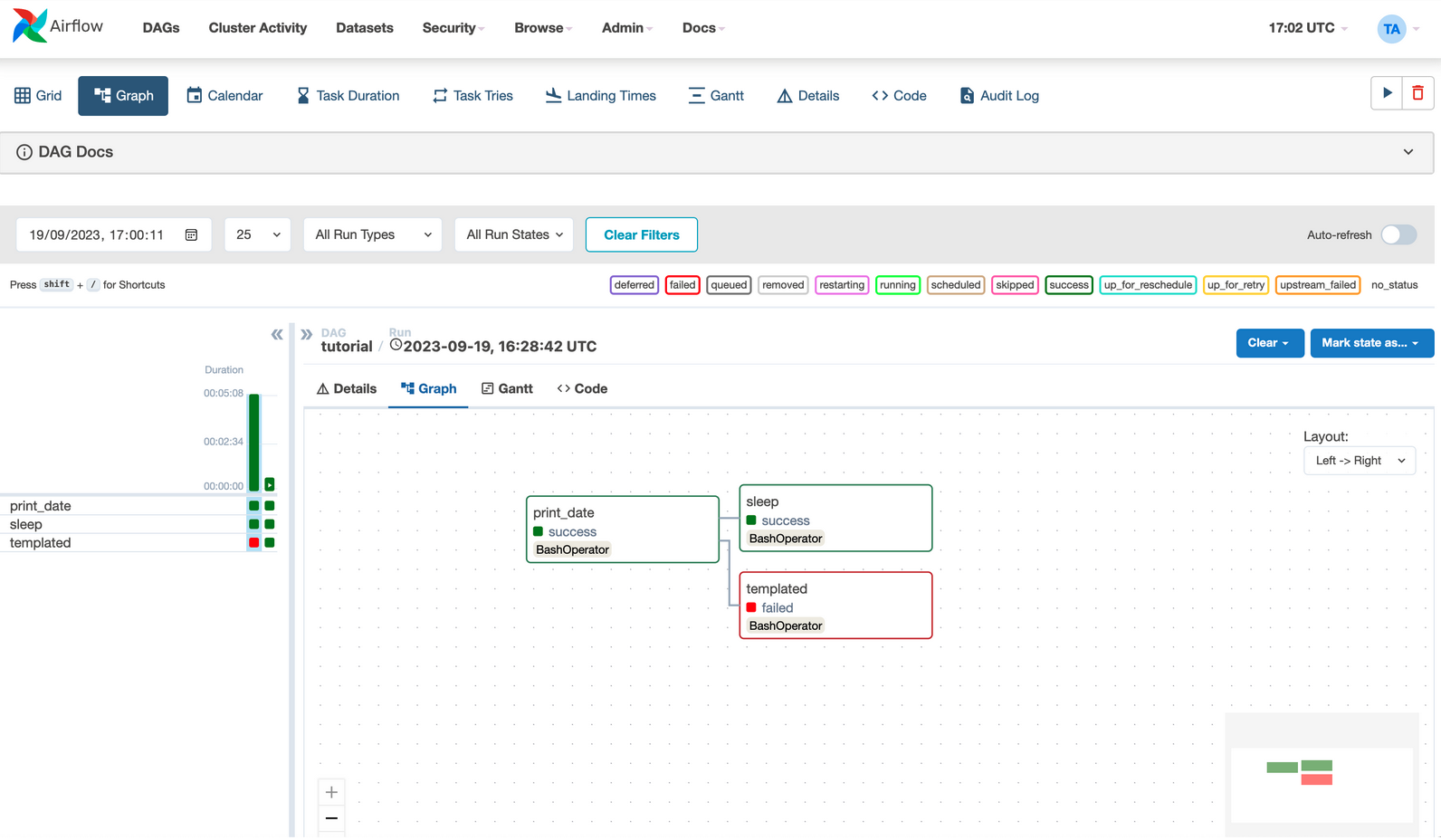
Airflow
Airflow is an open-source orchestration tool used to programmatically create, schedule, and monitor pipelines. The project was created in 2014 by Airbnb and has been developed by the Apache Software Foundation since 2016.
Key characteristics include:
- Maturity: Probably the most mature and widely adopted of the tools mentioned in this article. This also means that it comes with a large community and comprehensive documentation.
- Programming language: Airflow is very versatile. Thanks to its various operators, it is integrated with Python, Spark, Bash, SQL, and more.
- UI: Airflow provides an intuitive web user interface in which we can organize and monitor processes, investigate potential issues in the logs, etc.
- Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines.
- Flexibility: Airflow was designed with batch workflows in mind; it was not meant for permanently running event-based workflows. Also, while it is not a streaming solution, we can still use it for such a purpose if combined with systems such as Apache Kafka.
Miscellaneous
- Workflows are created as directed acyclic graphs (DAGs).
- Airflow operates in the selected environment and doesn’t require Docker images for pipelines. This removes the need for complex CI/CD.
- However, the above also means that we must install all the libraries used in any of the DAGs in the environment. In case we do not use containers, all pipelines are launched within the same environment. This can lead to dependency conflicts.
- While all pipelines are automatically registered, they are not versioned. This means that the latest version of code is used.
- The code structure is a bit limited - all DAGs must be defined in the same directory for them to be picked up by Airflow. In other words, the code defining the DAGs of multiple ML projects must be in the same repo.

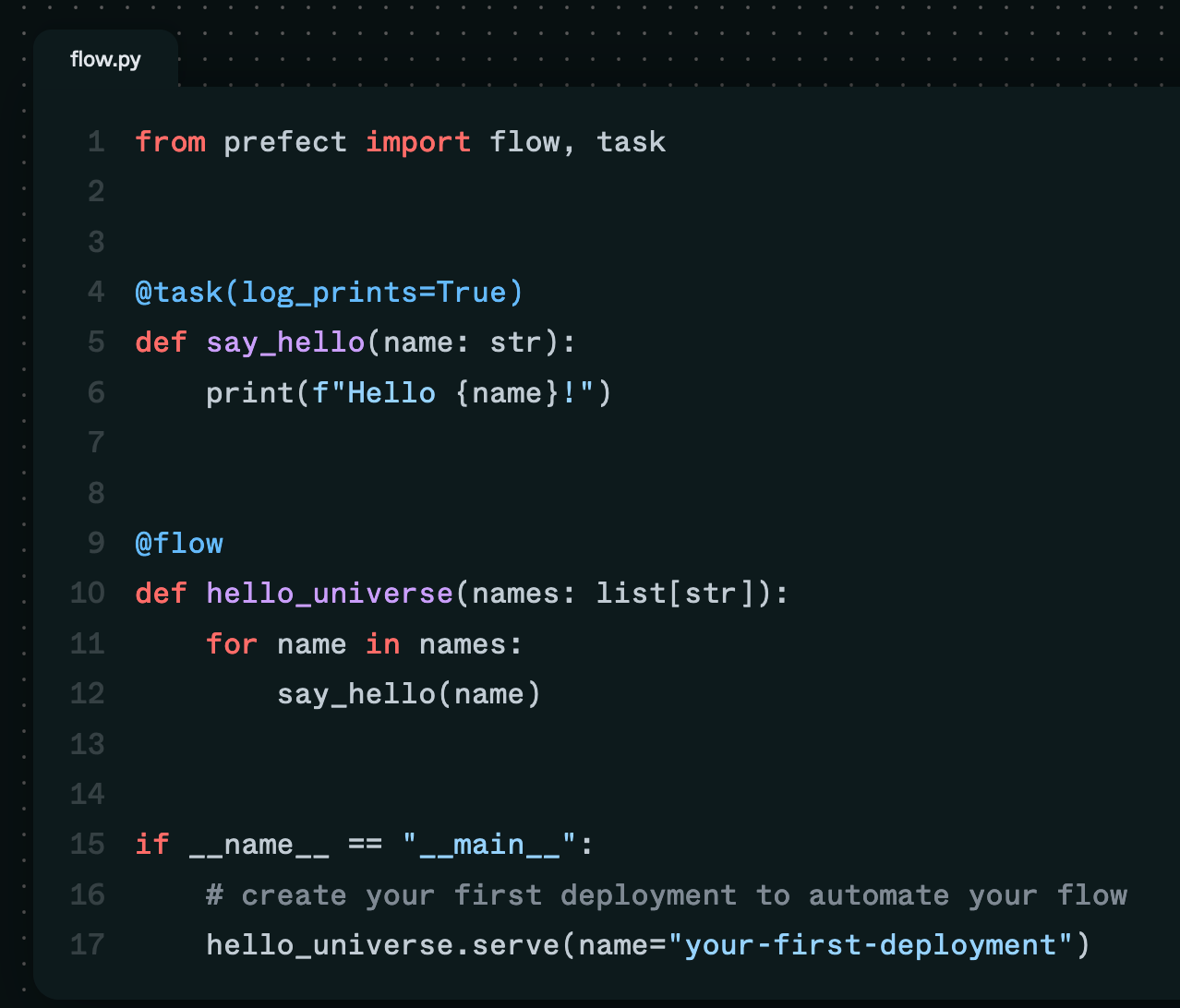
Prefect
Prefect is an open-source orchestration platform for building, observing, and managing workflows between and across applications.
Key characteristics include:
- Licensing model: An open-source and lightweight tool that can be used to build end-to-end ML pipelines.
- Programming language: It offers a simple way to transform Python code into an interactive workflow application. By using dedicated decorators, we can access features such as scheduling, automated retries, failure notifications, distributed execution, caching, and more.
- Enterprise-readiness: We can use the open-source version to host the orchestration engine locally, or we can opt for the hosted service (Prefect Cloud). With the hosted service, we gain access to additional features such as permissions and authorization, team management, SLAs, and more.
- UI: Activities can be tracked and monitored via both the self-hosted instance and the managed dashboard.
- Ease of use: Prefect might not be easy to use with complex pipelines that use auxiliary files. That is because if the entire flow is not contained within one file, currently it is not possible to register it from one machine and launch it on another. This means that all supporting files should be placed in a Docker container and that normally requires us to configure a full CI/CD pipeline.
- Maturity: As it is a relatively new tool, it is not as mature as some of the other ones in this article. Also, it is a bit more difficult to find resources online other than the official documentation.
Miscellaneous
- With Prefect, we can standardize workflow development and deployment across our organization.
- As workflows can be exposed through an API, other teams can programmatically access pipelines or connected business logic.
- Prefect supports individual environments for pipelines.
Kubeflow Pipelines
Kubeflow is an orchestration tool developed by Google. It focuses on building and deploying scalable and reproducible end-to-end ML workflows on Kubernetes.
Key characteristics include:
- Licensing model: Open-source tool focusing on deployment to Kubernetes.
- UI: Offers a centralized dashboard with an interactive user interface. However, the UI is not always intuitive, and some simple tasks might require quite a few actions to complete.
- Flexibility: Kubeflow is a very flexible tool allowing us to organize pipelines and their versions. We can have several versions of the same pipeline, and each one of them is stored, not only the last one. An additional benefit is that it also makes it very easy to roll back to any previous version.
- Ease of use: It is more complex than other tools and favors slow iteration cycles.
- Ease of use: It might be a bit tricky to debug locally, as we need to have Kubernetes installed on our machine.
- Ease of use: Updating pipelines with even slight code changes requires the full CI/CD (image rebuilding and pipeline re-registration), which can be time-consuming.
Miscellaneous
- The reusable components and pipelines allow us to quickly build end-to-end solutions.
- Other Kubernetes-based tools like KALE simplify the process of building the pipelines.
- Offers support for JupyterLab, RStudio, and VS Code.
- Supports training of ML/DL models with the most popular frameworks (TensorFlow, PyTorch, MXNet, and XGBoost, etc.), using AutoML tools, and additionally offers hyperparameter tuning, early stopping, and neural architecture search.
- Works well with the leading cloud providers.
- Thanks to containerization, we can have custom environments for different pipelines.
- Each ML project can be a separate Git repository with CI/CD that registers pipelines on Kubeflow.
Argo
Argo Workflows is an open-source, container-native workflow engine for orchestrating parallel jobs on Kubernetes.
Key characteristics include:
- Programming language: Argo is the most popular workflow execution engine for Kubernetes, and pipelines are defined using YAML files.
- Ease of use: Its CI/CD is configured directly on Kubernetes - no need for any other software.
- Scalability: Argo can support ML-intensive tasks.
- Scalability: Allows for easy orchestration of highly parallel jobs.
Miscellaneous
- Implemented as a Kubernetes Custom Resource Definition (CRD) - individual steps of the workflow are taken as a container.
- Cloud-agnostic and can run on any Kubernetes cluster.
- Multi-step workflows are modeled as a sequence of tasks, and dependencies between tasks are captured using a DAG.
Kedro
Kedro is an open-source workflow orchestration library initially developed by McKinsey. Its goal is to utilize software engineering best practices to build reproducible, maintainable, and modular data science pipelines.
Key characteristics include:
- Scalability: It supports single- or distributed-machine deployment.
- Flexibility: Through a series of data connectors, Kedro's data catalog takes care of saving and loading data across many different file formats and file systems.
- UI: Kedro offers a visualization tool for inspecting the data pipelines.
Miscellaneous
- Kedro encourages building workflows from reusable components, each with a single purpose.
- It is lightweight.
- It offers a project template based on Cookiecutter Data Science.
- By leveraging pipeline abstraction, we can automate dependencies between Python code and workflow visualization.
- It can be used to set up dependencies and configurations.
- Offers logging and experiment tracking.
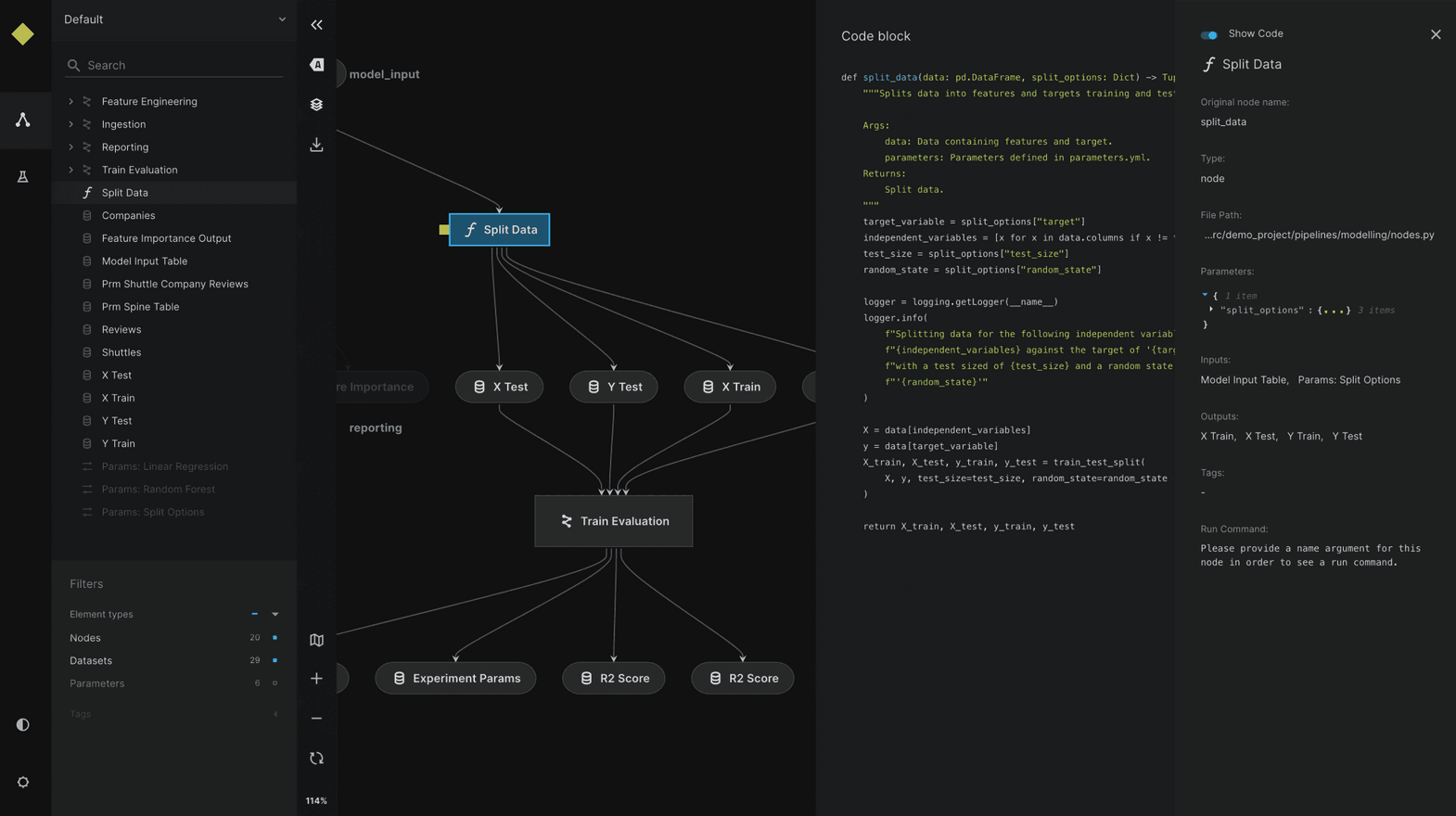
ZenML
ZenML is a lightweight, open-source MLOps framework for creating production-ready ML pipelines.
Key characteristics include:
- Ease of use: Allows translating observed patterns from research/experimentation in a Jupyter notebook into a production-ready ML environment.
- Programming language: Creates simple, Pythonic pipelines that work both locally and on an orchestrated backend (e.g., via Skypilot or another orchestrator defined in your MLOps stack).
- Integration: It can work alongside other workflow orchestration tools (Airflow cluster or AWS SageMaker Pipelines, etc.) to provide a simple path to getting your ML model into production.
- Integration: ZenML does not automatically track experiments. However, it offers integration with popular tools such as MLFlow, Weights & Biases, or Neptune.
- Scalability: Currently, ZenML pipelines do not handle distributed computing (tools like Spark), but they easily scale vertically.
- UI: Offers an extensive UI that allows for full observability of the workflows.
- Enterprise-readiness: Offers a paid managed ZenML server, which is safe to use with your data, as only the metadata is tracked there.
Miscellaneous
- Its approach to structuring the ML codebase allows for a seamless transition to production.
- Supports deploying to any of the leading ML cloud platforms.
- Excels when a team uses multiple tools with no central platform.
- Offers a single place to track and version data, code, configuration, and models. Additionally, it provides lineage.
- When using ZenML, infrastructure and run configuration are abstracted from code through a YAML config.
- Automatically creates containers and deploys the workflows to the cloud.
- It does not package and deploy models. Instead, it focuses on cataloging the models and metadata, which in turn streamlines model deployment.
- We can set up alerts and monitoring of the ML pipelines.
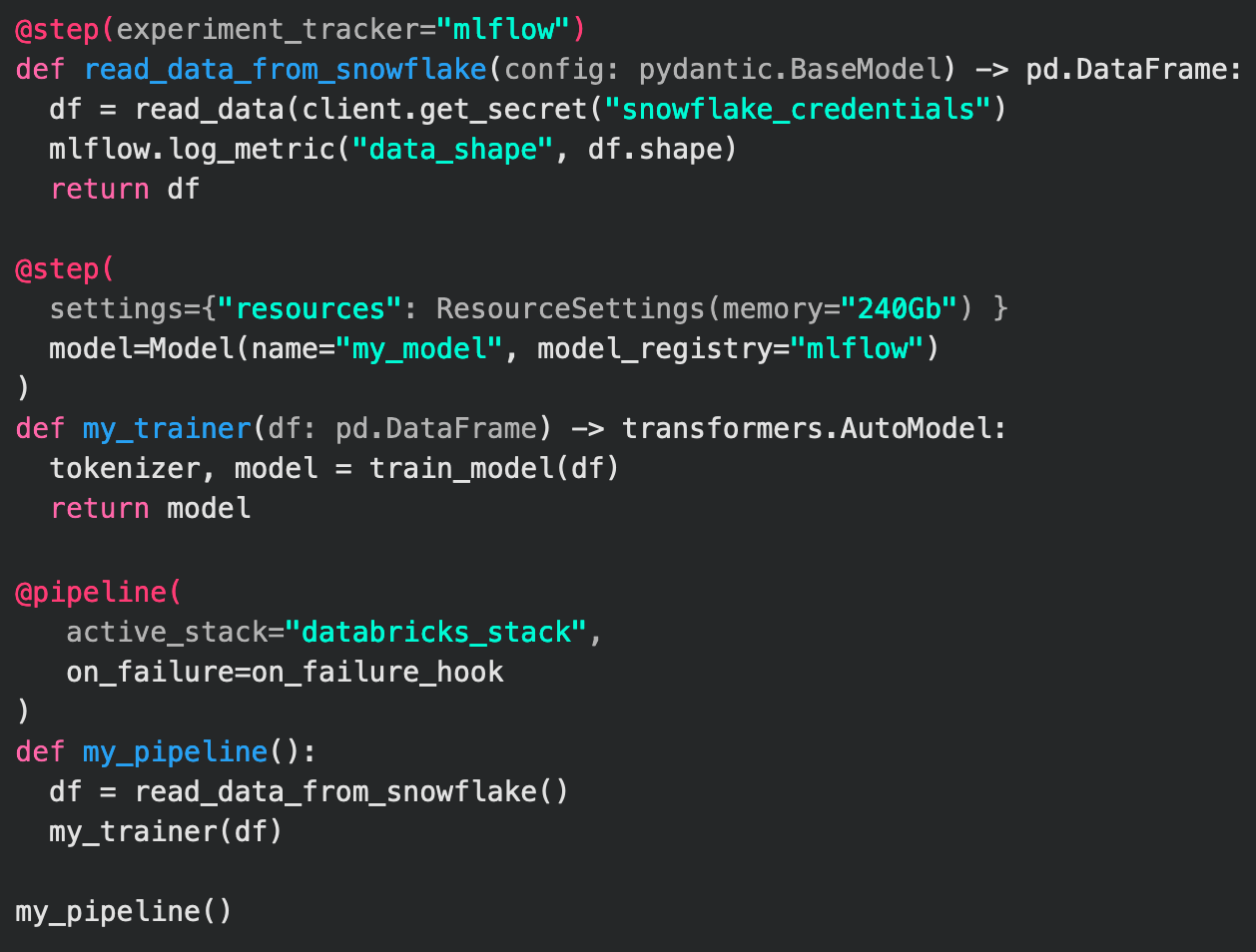
Metaflow
Metaflow is a lightweight framework developed by Netflix that makes it easy to build and manage real-life ML projects.
Key characteristics include:
- Licensing model: An open-source project developed by Netflix.
- Flexibility: Metaflow covers all the pieces of an ML stack: modeling, deployment, versioning, and orchestration.
- Ease of use: Supports workflows favored by data scientists: kicking off with Jupyter notebooks, then developing with Metaflow. Testing and debugging can be carried out locally, while the results are stored and tracked automatically.
- Ease of use: Deploying experiments to production is as simple as a single click of a button without any code adjustments.
- Ease of use: As a human-centric framework, it is easy to start using it. Basic Python knowledge is required for that; there is no need to learn other domain-specific languages.
- Scalability: Provides a simple way to scale from a laptop to the cloud. The Metaflow stack can be easily deployed to any of the leading cloud providers or an on-premise Kubernetes cluster.
- Scalability: Metaflow is a battle-tested, highly scalable library. In Netflix, it was used for thousands of ML projects. Since then, it has been adopted by hundreds of companies.
- Integration: The Metaflow stack also seamlessly integrates with your organization’s infrastructure, security, and data governance policies.
Miscellaneous
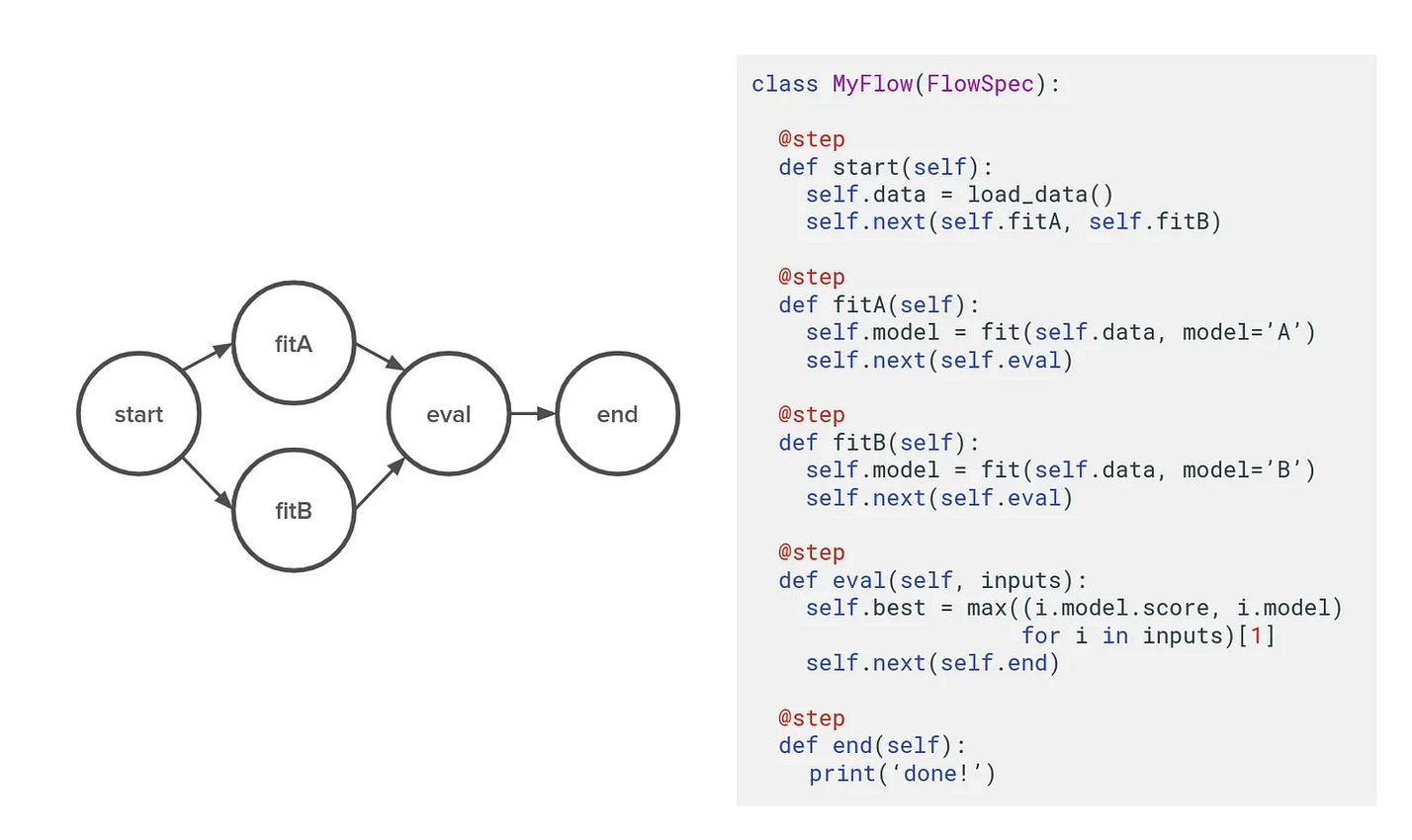
- When working with Metaflow, data scientists build pipelines as a DAG containing the computation steps of their workflow.
- A key difference between Metaflow and other frameworks is its built-in content-addressed artifact store. In simple terms, it means that it can load and store artifacts (e.g., data or models) as regular Python instance variables. The same approach works well once the code is executed on a distributed computing platform.
Other tools
As we have already mentioned, there is a plethora of tools available on the market. In this article, we have not managed to cover all of them. That is why we also provide some other ones you might be interested in exploring:
- Dagster - https://github.com/dagster-io/dagster
- KALE (Kubeflow Automated pipeLines Engine) - https://github.com/kubeflow-kale/kale
- Flyte - https://github.com/flyteorg/flyte
- MLRun - https://github.com/mlrun/mlrun
- Luigi - https://github.com/spotify/luigi
- Couler - https://github.com/couler-proj/couler
- Valohai - https://valohai.com/
- Genie - https://github.com/Netflix/genie
- Tekton - https://github.com/tektoncd
- Mage - https://github.com/mage-ai/mage-ai
Wrapping up
We have covered quite a lot of ground! To recap:
- ML workflows represent the sequence of tasks involved in building an ML project.
- Pipelines represent a specific implementation of that workflow.
- Orchestration tools provide frameworks and interfaces that enable us to create and manage the infrastructure of workflows and their pipelines.
We have also looked at the 7 most popular orchestration tools available on the market. While there is no easy way to make a choice, we should definitely consider the following while making the decision: Is the tool open-source? How mature is it? Which language do we have to use? Is there a dashboard that we can easily use to inspect the workflows? Do we need a managed solution?



