Announcing Data Science Pull Requests
- Dean Pleban
- 7 min read
- 6 years ago
Co-Founder & CEO of DAGsHub. Building the home for data science collaboration. Interested in machine learning, physics and philosophy. Join https://DAGsHub.com | DagsHub Co-Founder & CEO

A step forward for MLOps and unlocking Open Source Data Science
Today, we're releasing Data Science Pull Requests (DS PRs), which are Pull Requests (PRs), re-imagined for the data science (DS) workflow. This new capability unlocks a standard review process for data science teams, enabling them to merge data across different branches and accept data contributions across forks. This provides a better collaborative experience for teams in data science organizations and enables truly Open Source Data Science (OSDS) projects.
For more details, read on...
Introduction
When we started DAGsHub, we were focused on making data science collaboration possible. Specifically, we deeply care and rely on Open Source Software (OSS), and we set out on a mission to make OSDS as accessible and prevalent as OSS is today.
This meant that we were concerned about discoverability of data science projects and experiments to work on, understandability of the context of an experiment, reproducibility of its results, and finally, contributability of code-, data- and models- changed back to the original project.
When reviewing these processes and the existing solutions some things become clear:
- Discoverability means being able to answer the question "What should I do next?" – finding a project to work on, and within that project finding what experiments might be interesting or important.
It is solved mainly by experiment tracking systems, many of them using proprietary or black box formats that are hard to understand and migrate to/from.
DAGsHub goes beyond this by creating an experiment tracking system that relies on simple open formats (YAMLandCSV). This means you don't need to add obscure lines of code – everything works by automatically scanning and analyzing the git commits pushed into the platform. - Understandability means being able to answer the question "How should I do what I want to do?" – this usually consists of reviewing why, how, and what was already done in a project or experiment. The solution for this step is mostly manual and relies on self-documenting one's work and discussions with collaborators.
DAGsHub improves on this by providing a convenient interface into projects' code, data, models, and pipelines which give users a window into their projects' components, and how they interact with each other. - Reproducibility means setting up an exact copy of the experiment you want to work on. Many times this process is reduced to a Git commit and the experiment parameters (logged in the experiment tracking system). However, the true standard for reproducibility involves easily retrieving the same version of data, models, and other artifacts. It is best solved by using Git with some dedicated data versioning solution.
DAGsHub solves this by relying on open source tools such as Git and DVC to provide the standard discussed above – a complete copy of your project (code, data, models, parameters, and other artifacts) with one (or two) commands. - Contributability means that you can take a new experiment or result, and incorporate them back into the project you started from so that you don't need to maintain your result separately. Today, this is entirely manual, full of friction, and fundamentally non-existent.
We have many more things to build, but it was clear that one aspect needed to be covered first – a CONTRIBUTION mechanism.
Contributing – Data Science Pull Requests
The final step of the collaborative process is arguably the most important one. Without it, the workflow is one-sided, a monologue, which means collaboration isn't happening. Practically, Contributing can be broken down into two tasks - reviewing and merging contributions.
In software, both reviewing and merging are a part of the pull request process, but their focus was solely on code.
Data Science Pull Requests let you review experiments, code, data, models, and your pipelines, and merge changes to all of them automatically.
Data Science Review
If you've ever worked on a data science project with other people or tried reviewing someone else's data science work, you know how hard it is to get the information you need to understand someone else's work, or explain your own, so that the review process is meaningful. The process is slow and manual because systems are not built for review.
An automatic review process means changes and updates can be discussed and integrated faster into your project. You need to quickly see what has changed, discuss it, in context, and decide how to move forward.
What this means in practice:
- Commenting on experiments, in context – you can look at the new experiments that are being contributed as part of the DS PR, and compare them to the base experiment in the original project. See all the visualization and information, and add comments on these within the PR discussion with links to the relevant comparison/visualization.
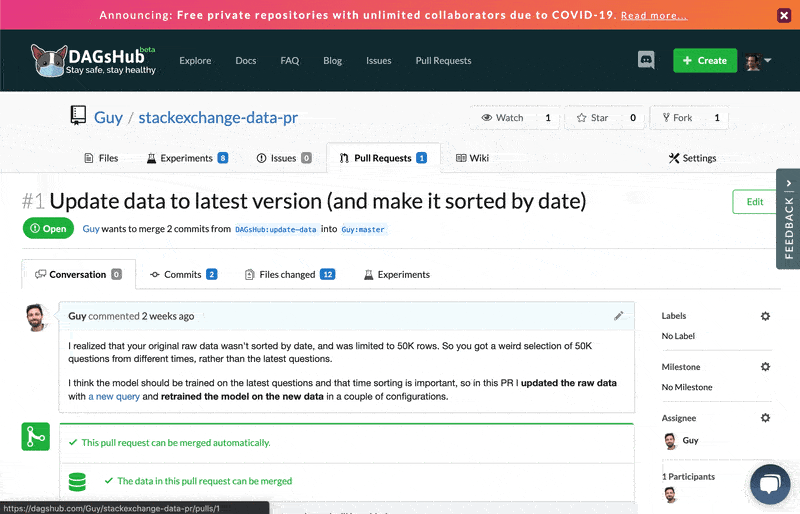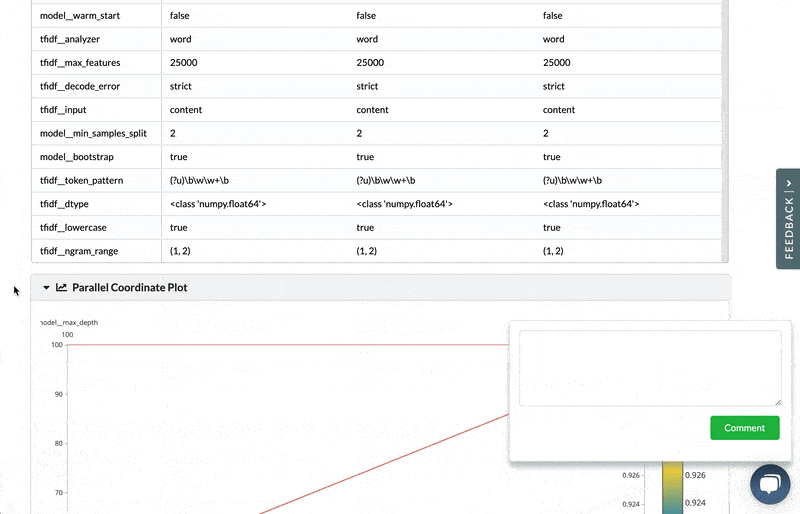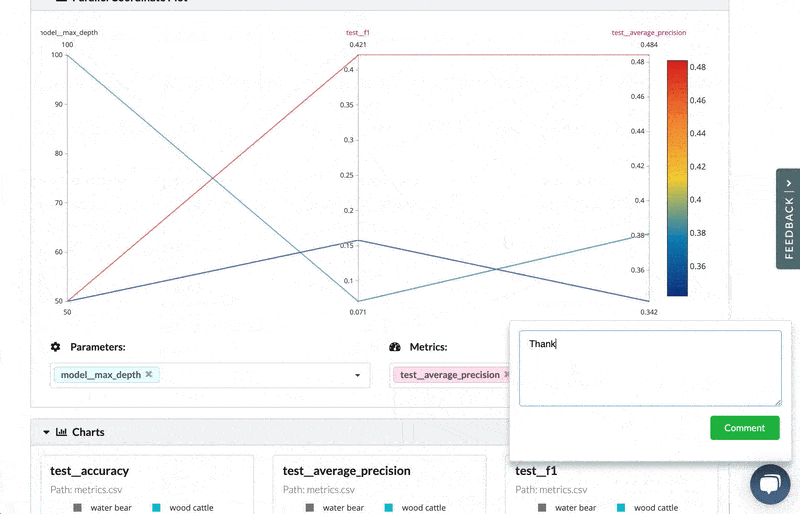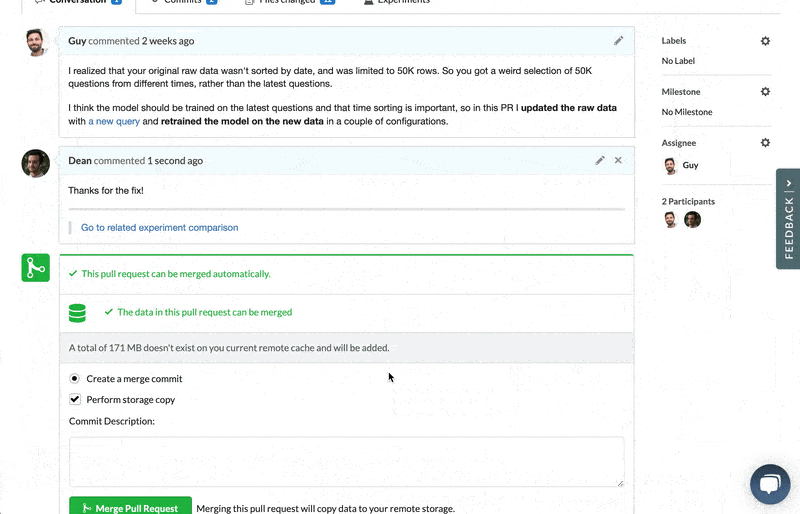
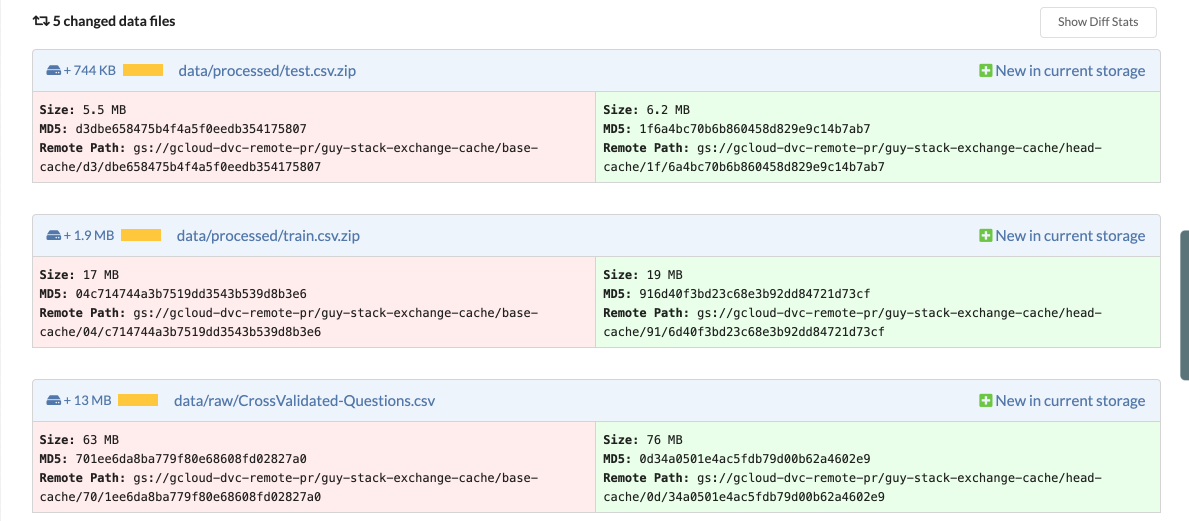
- See what data and models have changed (not just code) – view what data, model, and artifact files were added, removed, or modified. This means you can easily pinpoint changes and focus the discussion on what's important.
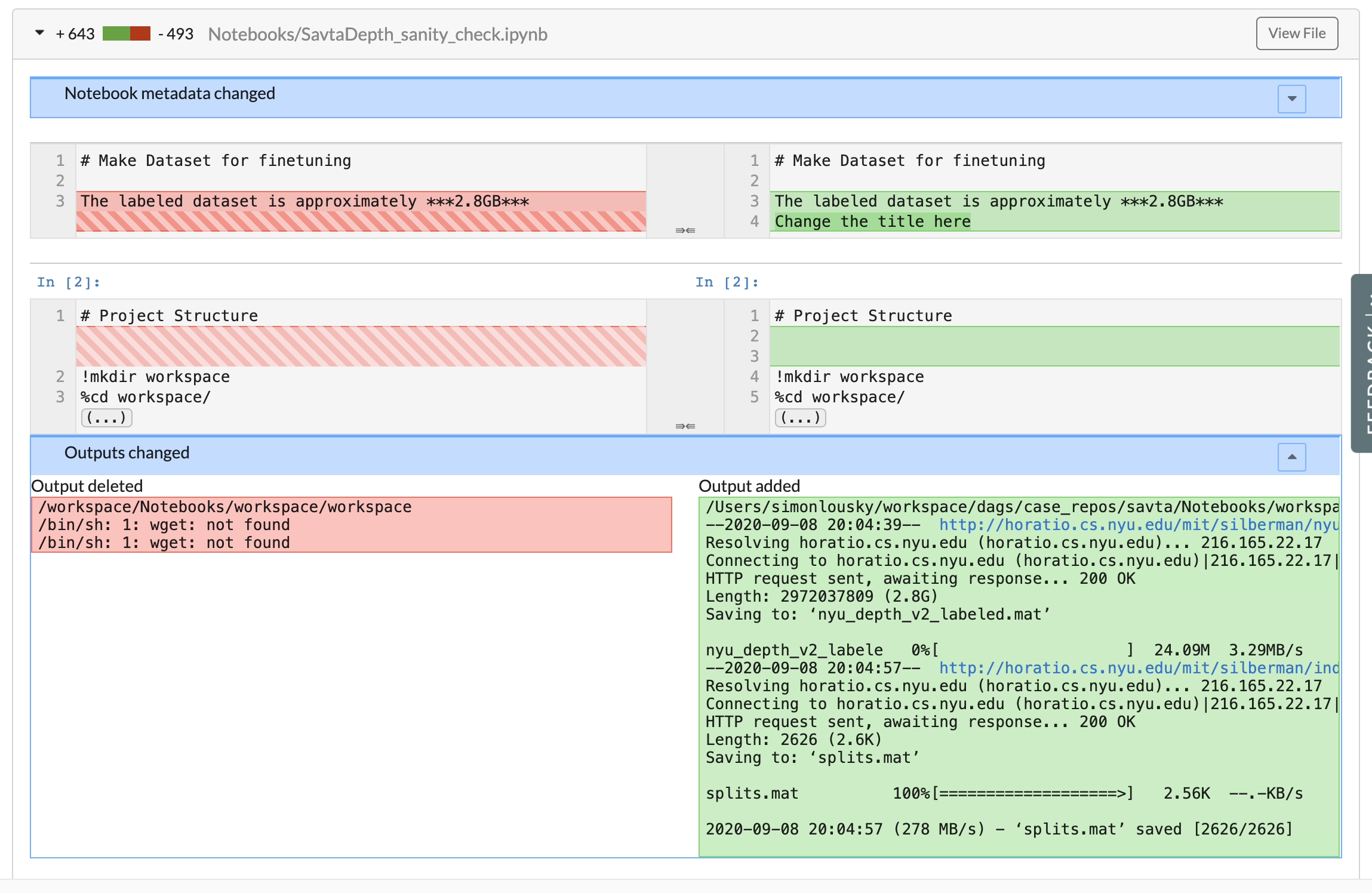
- Compare and diff notebooks side-by-side – notebooks are an important part of many data science projects. However, for a very long time, they haven't received adequate treatment in the review process, relying on diffs to the raw
JSONfile, which were mostly unreadable. You can now review the changes in an intuitive UI as part of the DS PR. Another benefit of this is that if you require a special visualization, you can commit a notebook with that visualization, and view the changes conveniently.
After reviewing a collaborator's work, we need a way to incorporate those changes, automatically. That's why we built data science merging.
Data Science Merging
Merging code is possible with Git, but as we already discussed, that is not the full picture for data science projects. With DS PRs, you can merge your data and other artifacts as well.
Data Merging
Everyone knows about bugs in code, but you might also have data bugs that you're not aware of. Examples include data that is not up to date, biased, or mislabeled. Assuming you found out about such a bug and you wanted to fix it – that would usually mean you need to agree on and perform some manual operation to update or add new data. With data merging, once you accept a DS PR, the new data would automatically be copied into your project in an entirely automatic process.
Artifact Merging
This doesn't end with just the raw data – data merging lets you merge models and any other artifact of your data pipeline (e.g. preprocessed data or 3d models). Take a case where one of the steps in a pipeline takes 2 weeks to run and results in some trained model or a processed dataset. If only raw data was merged, you'd have to run that excruciating 2-week process again. Artifact merging means that after a DS PR is merged, the resulting project is as reproducible as the original contribution.
After accepting a DS PR you are in the same state of your DS project, as you would after accepting a PR in a software project.
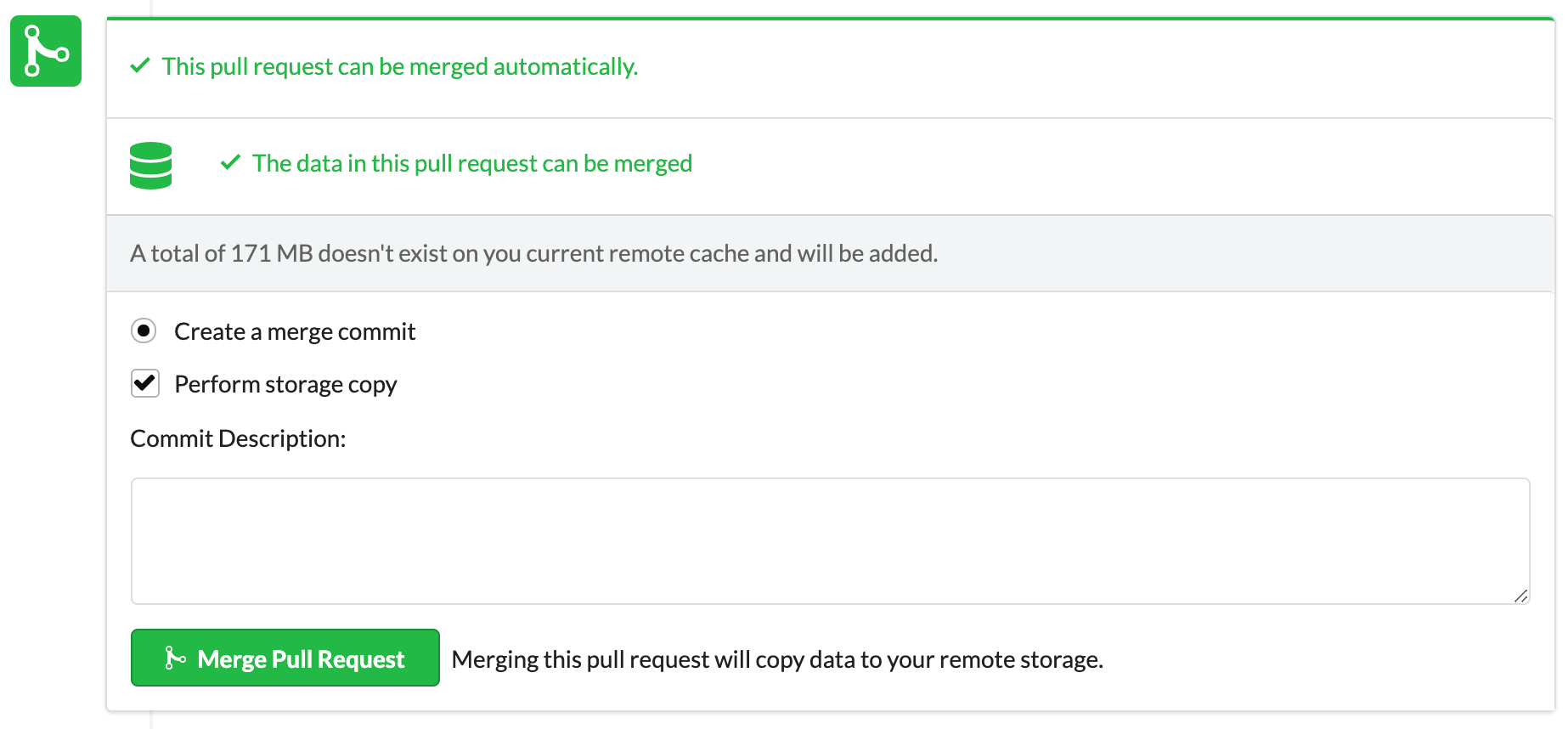
Data merging means you can accept data and models from contributors with ease, without giving each one full access to your data storage. This can reduce friction and speed up team efforts.
This last capability is especially useful for OSDS.
What does this mean for OSDS?
Open Source Data Science (OSDS) has the potential to have a similar effect on the world, as Open Source Software (OSS) had. It is DAGsHub's stated goal to promote OSDS and build the technology to make it as easy as possible. OSDS must come first, and industry workflows will mirror those in OSDS projects, as they have for OSS.
But let's face it – OSDS doesn't really exist yet. If you maintain some OSDS project and you want to accept contributions from people (like you would for OSS) – you have to do it entirely manually or resort to accepting only code changes (no way to accept data bug fixes – and we all know there are plenty).
From the individual contributor side, if you want to improve your ML portfolio by contributing to some OSDS project, you're also stuck. You have to either fork the project and not contribute your changes (which means their quality is never reviewed – you don't learn as much) or go through a painstaking manual effort[1].
DS PRs make OSDS possible by providing a standard interface and workflow to review and accept contributions from anyone, anywhere, and for any type of data science component.
We'd love to support open source data science projects that want to accept data science contributions from the community. Please reach out to us at osds@dagshub.com if this is relevant for you.
Thank You!
Thank you to all the people that gave us feedback before and while we were building DS PRs. We'd love to get your feedback as well on how DS PRs could be improved for the community – the best way to do this is to join our Discord channel. Looking forward to hearing your thoughts and seeing what people build with open source data science.



