ML CI/CD with Jenkins Part 1 –Data Pipelines and Continous Machine Learning in DagsHub
- Puneetha Pai
- 10 min read
- 5 years ago
MLE @ThoughtWorks. A generalist with keen interest in Open Source contribution and MLOps patterns.

This is the first part of two part series blog, discussing how you can achieve Continuous Delivery in Machine Learning (CD4ML) using Jenkins and DVC pipelines.
In this blog we will discuss how to setup this automation process for your project and few use-cases which are achieved as a bi-product of this automation.
For an in depth explanation of the stages see part 2 of this blog post where we explain concepts such as why it's a good practice to run jenkinsfile in a container.
TL;DR
- Data Science projects are unique but still can adopt many of the learnings from Software Delivery Principles and Methodologies.
- MLOps comes under the umbrella of DevOps. It addresses the rituals to take models running in Data Scientists’ laptops to production.
- Versioning your data and models is the first step to achieve reproducible results and DVC has done a great job on it.
- Adding to it, "Data Science Pull Request from DAGsHub and CML- Continuous Machine Learning from DVC, addresses a few nuances of DS projects, and applying standard CI/CD practices to ML projects.
- While CD4ML - Continuous Delivery for Machine Learning, gives us standard practices and principles around Delivery in Machine Learning,CML is one possible implementation, relying on Github Actions.
- In this blog we will be extending the ideas of CML, and implement it using Jenkins pipeline and DVC pipelines, with the help of DAGsHub's Jenkins plugin.
- The core of this post is how we automate running DVC pipelines, as part of the Jenkins CI/CD Pipeline. If it’s one thing, you want to get from this blog; that would be this Jenkinsfile.
By the end of this post, you will learn how to set up a Jenkins pipeline for your project, define an end-to-end Machine Learning pipeline with DVC, including standardized CI processes for your project. On the way, I’ll show you a simple and elegant way of managing your experiments, based on Git branches and commits, which will make your life much better, especially when working in a team on complex projects.
Need for Automation:
Automation in a delivery project helps us introduce standards of working, seamless collaboration practices, ensures product quality, eliminates tedious repetitive manual efforts, and mainly reduces our time to production. Software delivery projects have evolved over the span of 2-3 decades, and best practices/principles have emerged with time.
On the other hand, Data Science and Machine Learning projects are still in an evolving space where people are trying out different methods and sharing what works for them. Data Science is quite a vast space, with new research getting published on a day-to-day basis, and DS projects are more dynamic in nature, so the ideal workflow and automation tools haven't been consolidated yet.
This post will show how we can apply automation which speeds up your research, helps in ensuring reproducibility and better handling of results.
Treating experiments like potential new features in a software project opens up many possibilities for improving our engineering practices.
We will be discussing two major use cases along with other best practices that can be applied in DS projects. The first is how you can achieve remote training of your models, i.e schedule an automation process to run your experiment/training job on a remote server. The second is how you can add transparency to the Pull Request review process, where you would be able to compare experiments to better judge the code changes. Both of these use cases help you standardize your experiment/research execution and evaluation, plus achieve seamless collaboration in the team.
Prerequisites for using Jenkins
There is a lot of knowledge and information on Jenkins and how to use it around the web. In the limits of this post, I’ll assume you already know how to configure pipeline jobs in Jenkins UI, save credentials as secrets, and how to use them in pipeline steps.
Before you move on, these are few things you should already have set up:
- Set up a running Jenkins Server, which executes your CI pipeline. You can follow the instructions in JenkinsDockerSetup to do so, or just set it up normally.
- Few essential Jenkins plugins are: Docker Pipeline plugin, to run our jobs as containers and Branch Source plugin (Github, DAGsHub), to discover Branches and Pull Requests from the repository.
- You have an end-to-end Machine Learning DVC Pipeline, that you want to run with Jenkins Pipeline. If you don’t have one, you can use my example project that I created for this post.
Note: The reference project has been developed in Python, but the same concepts should be applicable to other ML projects using other technologies.
A note about pipelines:
I know we are talking about Jenkins pipeline, DVC pipeline, automating one pipeline to run another pipeline. There you go, I said it, the tongue twister of the post.
Addressing the elephant in the room, the Jenkins pipeline is a Continuous Integration/Delivery pipeline. We use it to automate our build process, which ensures safe and seamless integration of changes from the team to the main branch and also automates the delivery. We define our build steps and checks in a file called Jenkinsfile in the root directory of our project, which Jenkins Sever understands and executes for us.
In Machine Learning projects, the DVC pipeline defines steps to run our experiments. Usually, the DVC pipeline involves stages like Data Ingestion, Processing, Modelling, Evaluation/Prediction, etc. DVC lets us define our ML pipeline in the dvc.yaml file and helps us run the ML experiments. DVC is a natural choice for ML pipeline, as it versions the experiment results, optimizes the stages to run, by checking stage dependencies and deciding what should and shouldn’t run.
The blog post will guide you on how you can automate running your experiment. i.e running DVC pipelines in your CI/CD, Jenkins Pipeline.
Jenkins pipeline for CI:
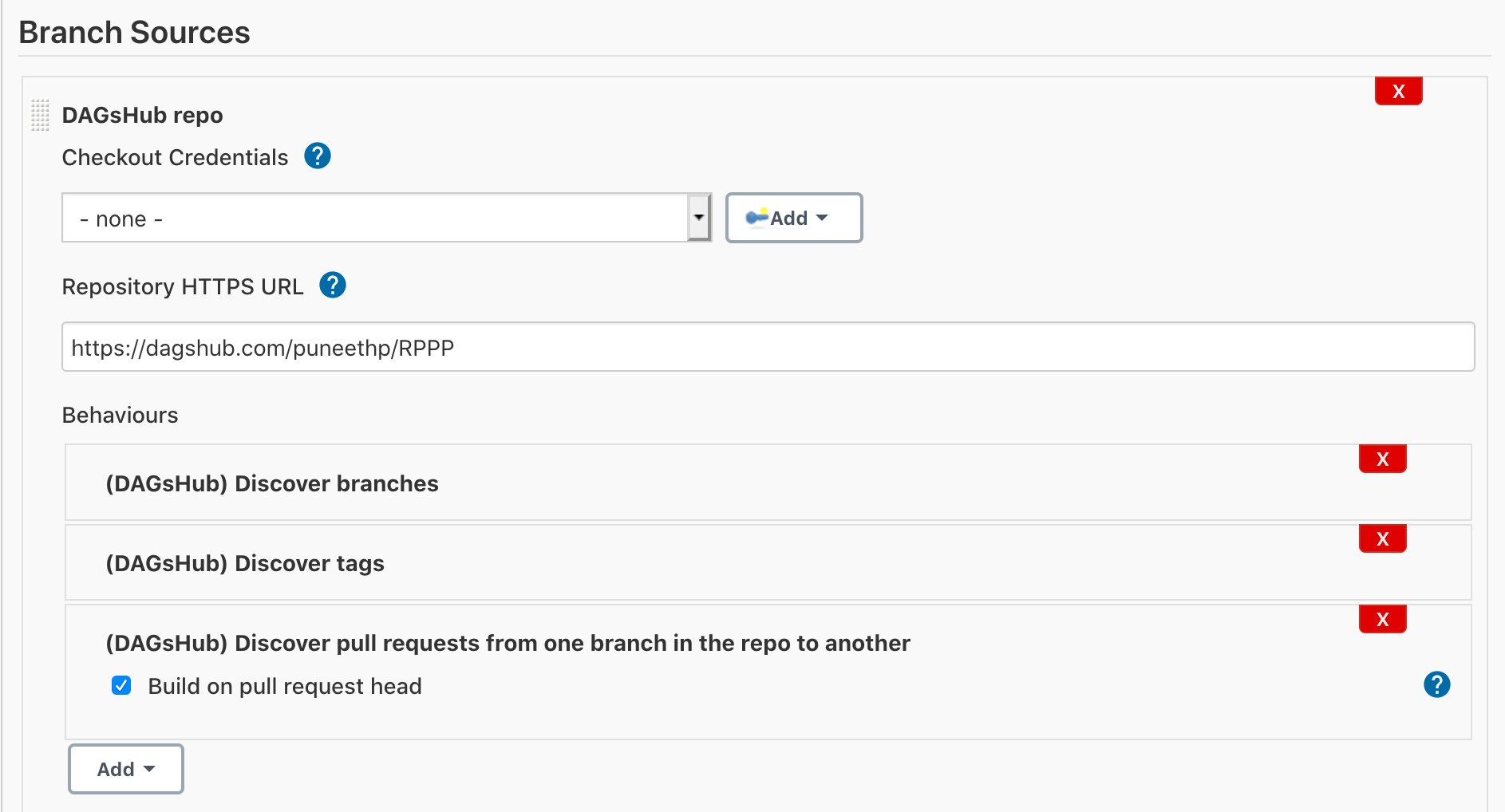
We want to create a Multibranch pipeline job so that our build runs for all the branches, i.e experiments of all the branches are run and compared when the Pull Request is raised. To create a Multibranch Pipeline Job, you can follow along with creating a Jenkins pipeline documentation
After creating a job, open the Configure tab to verify your Project Repository URL and the path of the Jenkinsfile inside your repository. This is how Jenkins will know, for each branch, what to execute as part of the build process.

Stages in the Jenkins Pipeline
Here are a few stages that we will be defining in our Jenkins Pipeline:

- Run Unit tests
- Run Linting tests
- DVC specific stages
- Setup DVC remote connection
- Sync DVC remotes
- On Pull Request
- Execute end-to-end DVC experiment/pipeline
- Compare the results
- Commit back the results to the experiment/feature branch
Use Cases:
Once you have the above setup running for your project, let's discuss a few handy use-cases which are achieved by this automation.
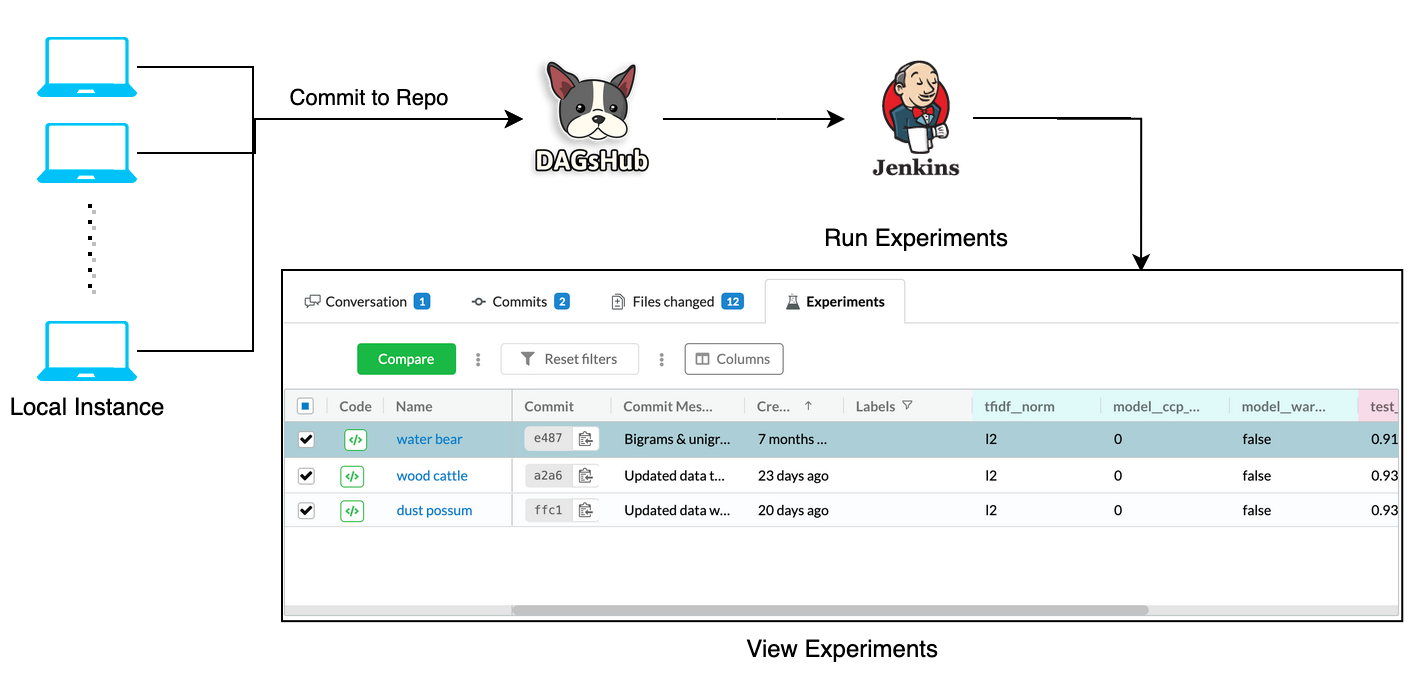
Using Jenkins for Remote Training:
Quite often in DS projects, training of models is a time and resource-consuming process. Ideally, we would like to make a few changes and schedule these training jobs to run offline, without obstructing our work. This is achievable through Remote Training Jobs, where you schedule training jobs to run on a remote, high-performance machine, and the job replies back with the results for review after completion.
Reasons you would want to do remote training of your models are:
- Everyone loves automation.
- Your model training can be a very time-consuming process. You want to schedule a training job and then get notified with results when the job is finished.
- GPUs and compute needs for training are not present in your local development environment.
- To eliminate costly data transfers between storage to the job environment, you want to run a training job as close to the data source as possible.
- Due to WFH and low network bandwidth constraints, you want to work on cloud machines to reduce your network load and latency.
- Standardization of the environment and process to make sure everyone is measuring the same thing on the same machine.
This automation is achievable with the following two stages of our Jenkins pipeline:
- Update DVC Pipeline
- Commit back Results
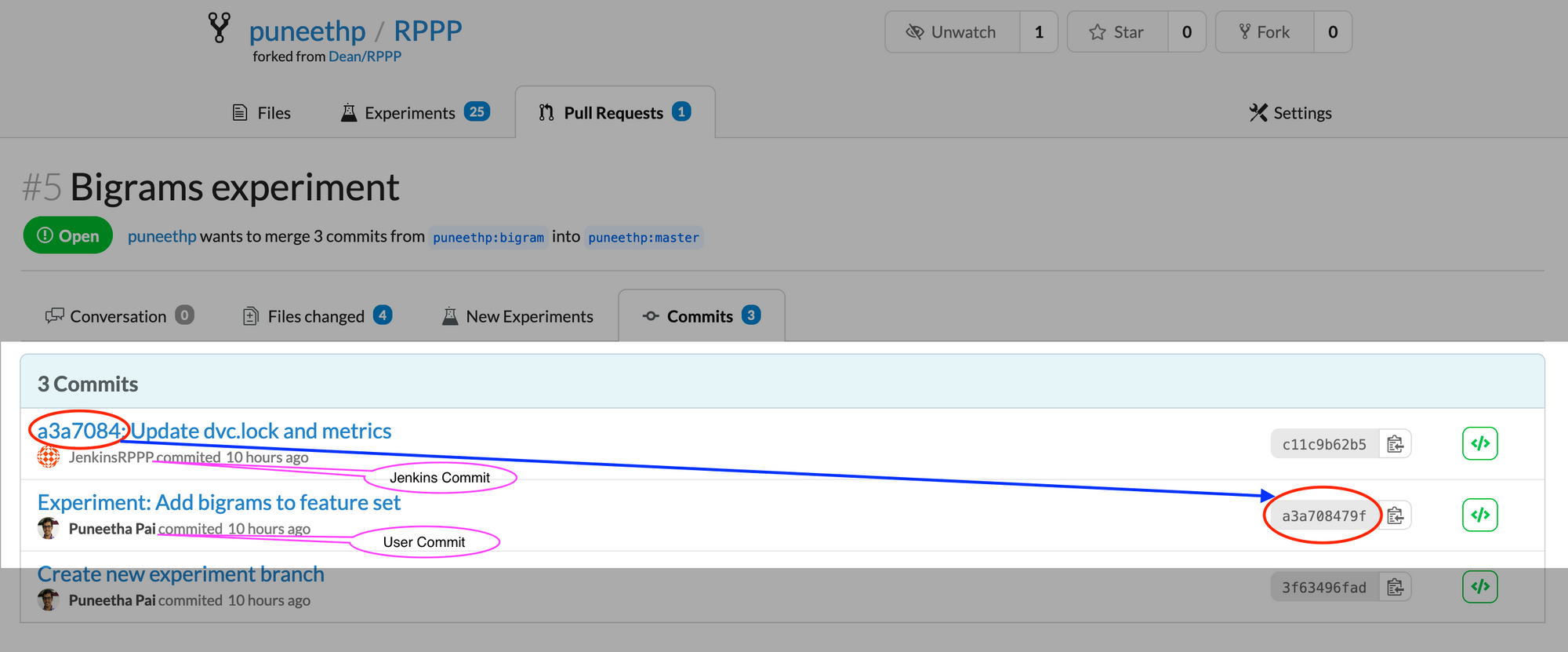
This means for any new experiment, create a new experiment branch, and define your experiment by changing the code, data, parameters, and/or any other dependency in the DVC pipeline. As long as we can trigger the DVC pipeline execution (i.e your experiment execution), Jenkins and DVC will execute the experiment for you. When we create a pull request for the experiment branch to the target branch, the above two stages execute the experiment and save the results back (metrics to Git remote and artifacts to DVC remote).
Reviewing Experiment Results with Jenkins:
If we use Jenkins for remote training, it’s important to consider how we evaluate the results of a training session.
Jenkins will commit the results back (metrics to Git and data/models to DVC). You can review them as follows:
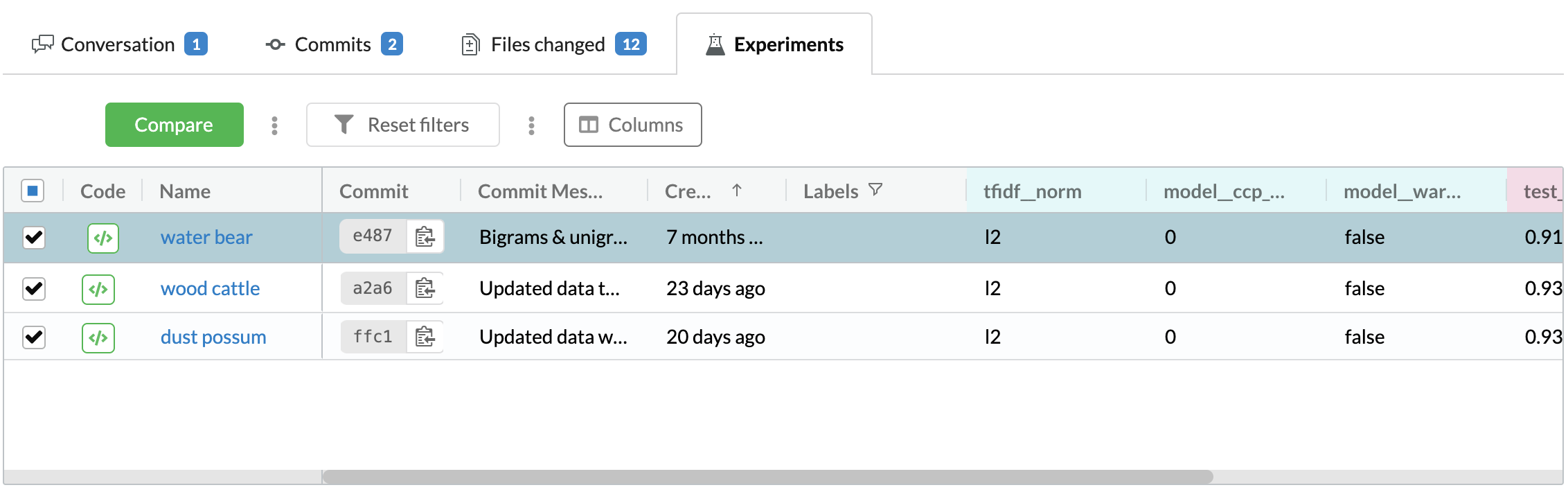
Using DAGsHub
If you use DAGsHub to manage your repo, you can use its Data Science Pull Requests features to automatically see all the new data, models, and experiment results which were generated and committed by Jenkins, directly in your browser, without needing to clone the project to your machine.
Using the command line
Since these are all open source formats, and everything is stored in the Git history, you can also just clone and pull everything locally to look at it:
git pull origin {feature/experiment branch}
# 1: Fetches Jenkins commit, i.e metadata (metrics and dvc.lock file).
dvc pull -r origin
# 2: Now you fetch the data/models from DVC storage.
Now you have the latest metrics, data, and models on your machine courtesy of Jenkins. You can review them and/or develop further on.
Ignoring Experiments:
Sometimes we want to ignore the current execution of the experiment. This could be because of a few reasons like, our experiment branch is not up-to-date with the master branch, i.e we have to rebase our experiment branch with latest changes in master before it can be merged. Or, there was a code/data bug, which we realized after the execution of the experiment from Jenkins. In either case, we want to discard the existing experiment run in our branch. Then re-run the experiment, once we have ensured we have the latest(from master) and greatest (bug fixed) code.
This is analogous to rebuilding the artifact in any normal software delivery project with latest and bug free code. All we need to do in such a case is ignore the experiment save commit from Jenkins and force-push our latest changes.
git push origin {feature/experiment branch} --force
Caution: Force push, rebase will rewrite our git history. These are powerful double edged swords :). We should use it only when we know what we are doing.
Enhancing the Pull Request Review Process:
Data Science projects are more dynamic than Software Delivery projects. The main reason for that is, in a DS project you have all the factors that influence a Software Development Project, plus a set of factors that are unique to the data world. To name a few:
- Quality and volume of Data
- Data cleaning/processing steps
- Model complexity and explainability
- Technical and Business Metrics
When we consider each experiment to be a potential new feature to our product, we can incorporate experiment review during our PR review process.
In my opinion, there are two types of Pull request review processes.
Black Box Review:
Reviewing only code changes, and making sure all tests are passing. In Machine Learning, this is not enough because these changes can have more subtle meaning than ”good" or "bad”.
Transparent Review:
We should be able to compare the effect and implications of the changes we made by comparing experiments. Hence in the Pull Request review process, we should compare experiments, to increase transparency.
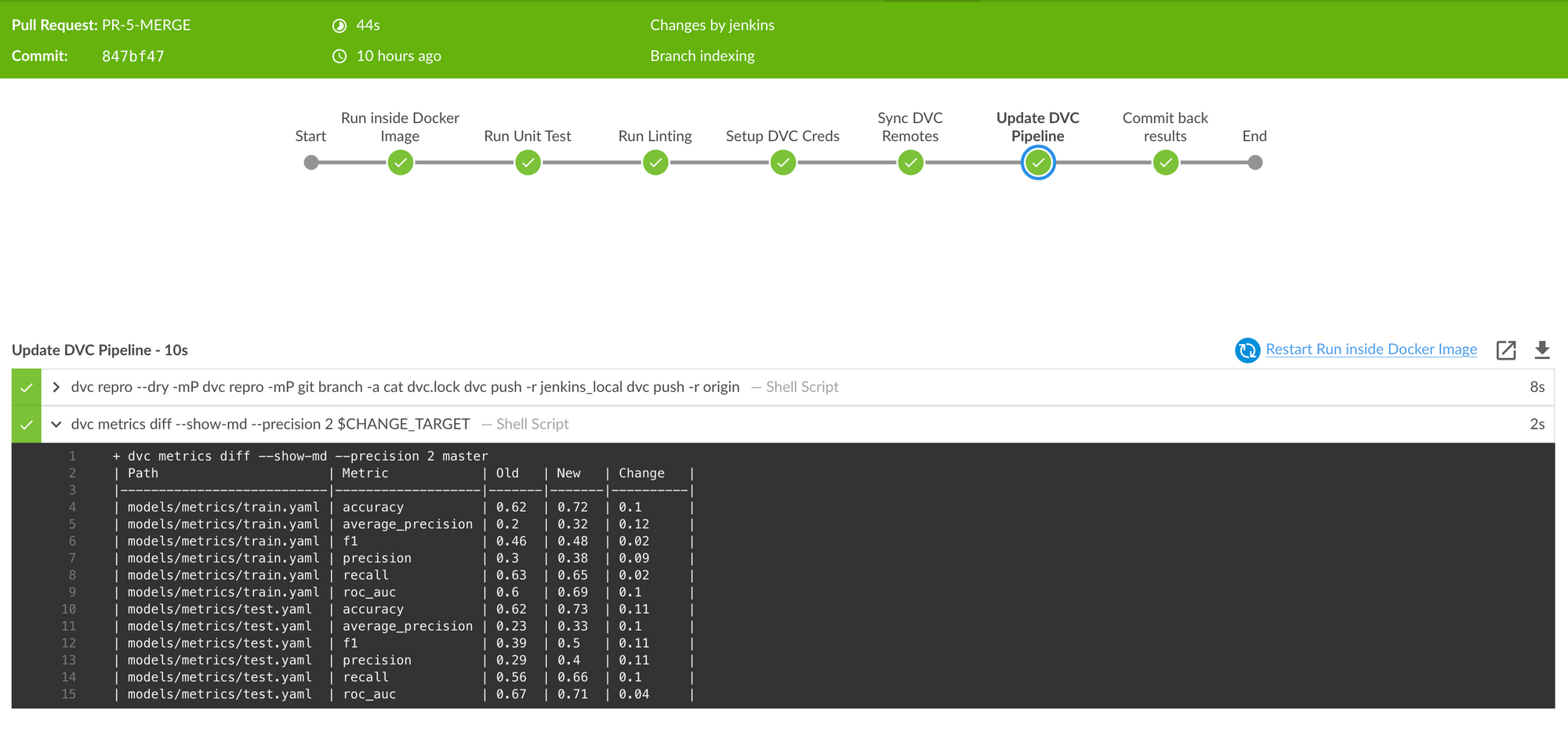
Experiment Comparison can involve comparing changes in metrics, hyper-parameters, data distribution, data cleaning and/or model algorithms/architecture. To begin with, we can compare metrics and take it forward from there.
We can compare metrics tracked at the end of the experiment with dvc metrics diff command. This is done as part of the Update DVC Pipeline stage defined in our pipeline. With DAGsHub it will automatically detect all the experiments which were run as part of the Pull Request and makes it easier for us to compare them with experiments in the main branch. To learn more, check out Data Science Pull Requests from DAGshub.
Take Aways:
- Jenkins is the most widely used open source automation tool
- DVC is great for versioning data/model, define experiment pipelines, experiment tracking, etc
- As shown here, we can also run ML experiment as part of our CI/CD pipelines. Doing so ensures standardization of the experiment execution environment and the process. This will ensure everyone is measuring the same thing on the same machine in the same way.
- Integrating this as part of your Pull Request, allows you to achieve more transparency in your review process, especially when used with Data Science Pull Requests.
- Automation can seem like overhead, but it provides productivity multipliers which add up to huge benefits, especially as we gradually improve automation and don't regress
Shout out to CML developed by DVC, which has influenced this implementation using Jenkins. And I am ever grateful to the DAGsHub team for supporting me in getting this out and spreading this idea.



