Version Control for Machine Learning
- Nikitha Narendra
- 7 min read
- 3 years ago

Version control is like a time-traveling tool for your work. It keeps track of every change, allowing you to go back to any version, check what's different, and even undo changes if needed.
In the field of software engineering, version control is a widely adopted practice for managing changes, maintaining traceability, and enabling smooth collaborations.
Machine learning (ML) has emerged as a powerful tool for extracting insights from complex data. However, the development of ML models can be an iterative process, involving numerous changes to code, hyperparameters, and data. To ensure reproducibility and traceability, it is crucial to employ version control systems (VCS) that effectively track these changes throughout the ML lifecycle.
Why Version Control is Essential in ML
Version control is an indispensable practice in machine learning (ML) for several crucial reasons:
- Reproducibility: ML projects are often iterative and involve numerous experiments with different data, models, and hyperparameters. Version control ensures that every stage of the development process is documented and can be easily revisited, enabling the reproduction of successful experiments and the identification of problematic changes.
- Collaboration: ML projects often involve multiple data scientists working together on different aspects of the model. Version control facilitates collaboration by allowing team members to track changes, share code and data, and merge their work without conflicts. This promotes transparency and efficient teamwork.
- Debugging and Troubleshooting: ML projects are complex systems, and issues can arise during development or deployment. Version control allows data scientists to revert to previous versions of the code, data, or model to pinpoint the source of problems and debug them effectively.
- Experiment Tracking: Version control enables the tracking of experiments and their associated results. This allows data scientists to compare different approaches, analyze the impact of hyperparameter tuning, and make informed decisions about model development.
- Model Lineage: Version control provides a complete history of changes made to a model, including the data used, hyperparameters, and code modifications. This lineage is crucial for understanding the evolution of the model, identifying potential biases, and ensuring compliance with regulations.
- Deployment Management: Version control facilitates the deployment and management of ML models in production environments. By tracking changes to the model and associated artifacts, data scientists can ensure that the deployed model is the correct version and that any updates are rolled out smoothly.
What Needs to Be Versioned in ML
In machine learning (ML), several key artifacts need to be versioned to ensure reproducibility, collaboration, and effective development:
- Source Code: The source code, including Python scripts, Jupyter notebooks, and any other code used to train, evaluate, or deploy the ML model, should be versioned using a version control system like Git. This allows for tracking changes, reverting to previous versions, and collaborating with other developers.
- Data: The training and validation data used to develop the ML model should be versioned separately from the code. This ensures that the model is always trained and tested on the same data versions, promoting reproducibility. Versioning tools like DVC or DagsHub can be used for data management.
- Models: The trained model weights and architecture should be versioned. This allows for tracking model performance changes, reverting to previous versions if necessary, and deploying specific model versions to production environments.
- Hyperparameters and other Configuration parameters: The hyperparameters used to train the ML model should be recorded and versioned alongside the model weights. This allows for understanding the impact of hyperparameter tuning on model performance and comparing different training runs.
- Training and Deployment Environments: The configurations used for training and deploying the ML model, including dependencies, libraries, and operating system specifications, should be versioned. This ensures that the model is trained and deployed consistently across different environments.
- Experiment Tracking and Documentation: The details of each experiment, including hyperparameter settings, performance metrics, and any relevant notes, should be documented and linked to the corresponding model version. This provides context for understanding the model's development process and its performance.
Versioning these artifacts helps maintain a clear lineage of the ML project, enabling data scientists to reproduce results, identify potential issues, and collaborate effectively. It also facilitates the deployment and management of ML models in production environments. It can also assist in validating reproducibility via the reproducibility scale.
Types of ML Version Control Systems
Two primary types of VCS are commonly used in ML:
Centralized Version Control Systems (CVCS): These systems store the entire codebase in a central repository, providing a single source of truth. Examples include Subversion and Microsoft Team Foundation Server (TFS).
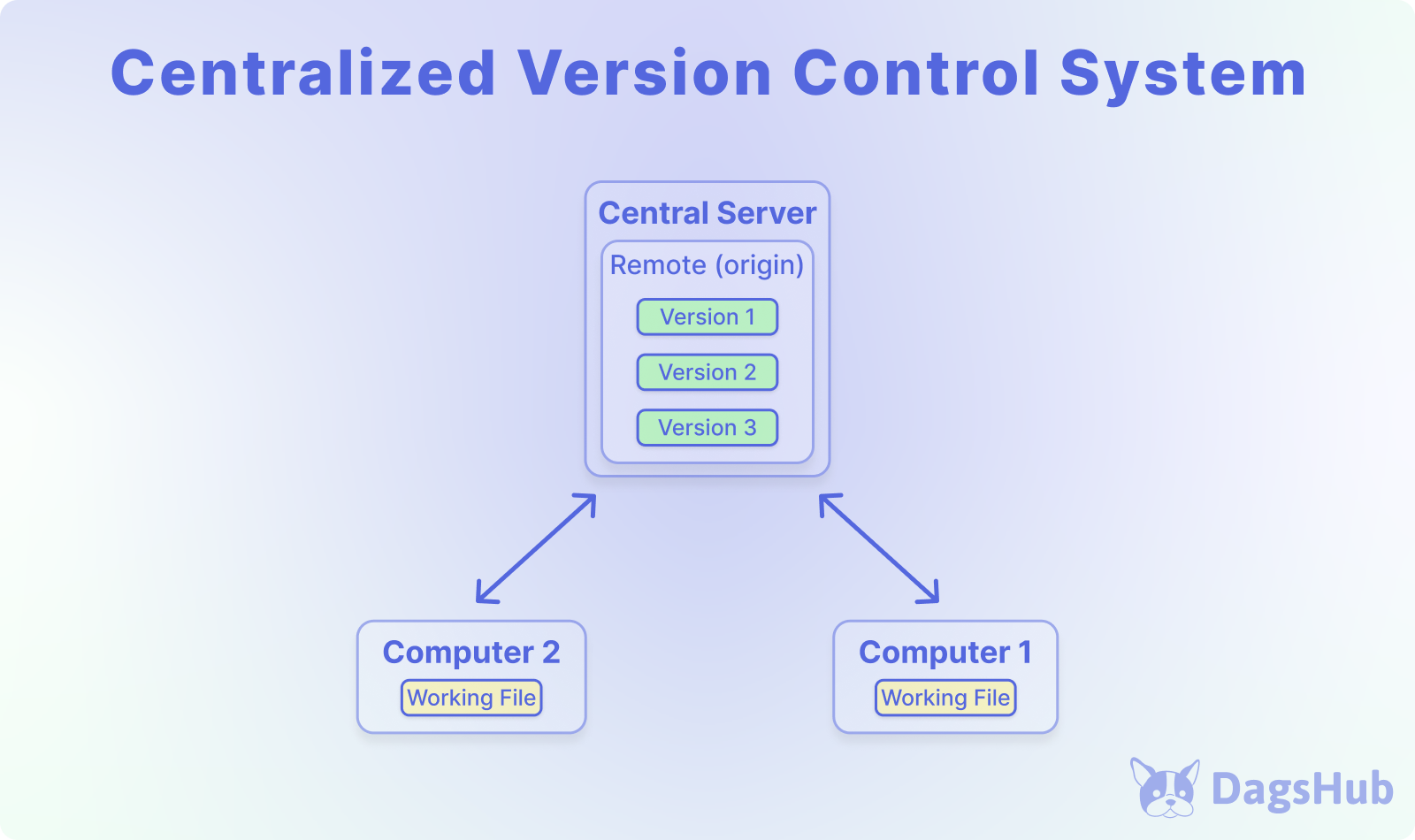
They facilitate reproducibility for data scientists, enabling them to revert to previous versions for debugging and troubleshooting. CVCSs also streamline collaboration, allowing team members to access the latest code and data modifications without disruptions.
They boast advantages such as centralized storage, controlled access, change tracking, merging, branching, backup, integration with other tools, and auditability.
However, they come with limitations like a single point of failure, performance bottlenecks, and merge conflicts. Notably, CVCSs may require special handling for large files, such as datasets and models.
Distributed Version Control Systems (DVCS): These systems maintain a complete copy of the codebase on each developer's machine, enabling offline work and conflict resolution. Examples include Git and Mercurial.
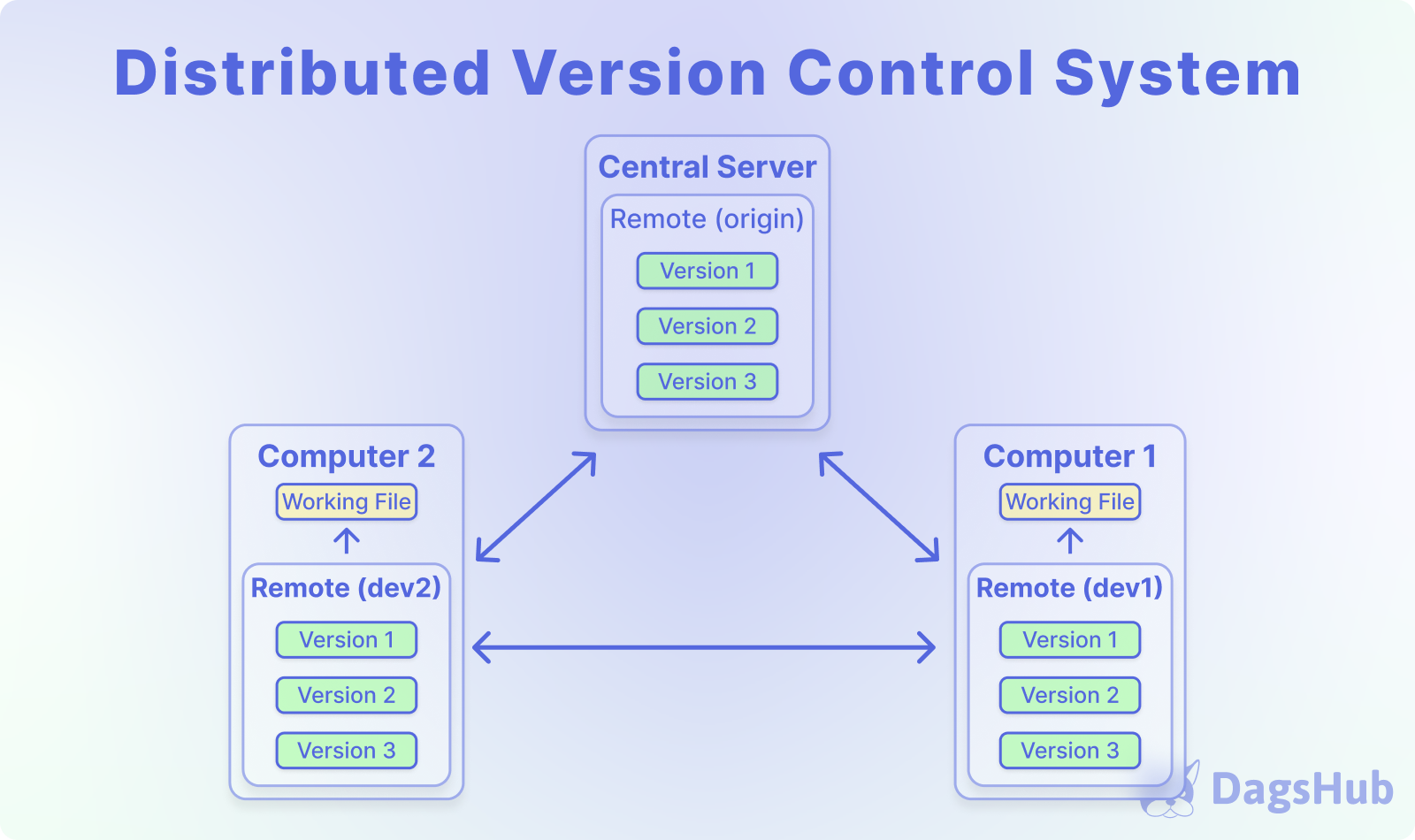
Distributed Systems with a hybrid approach that defines one remote as the central remote, provides all the benefits of a CVCS without the downsides. This is especially critical in collaborative work, where more than one person might work on the same codebase.
DVCSs, with their distributed nature and offline capabilities, benefit ML projects by enabling work in environments with limited connectivity. They eliminate CVCS's single point of failure, fostering rapid iteration, collaboration, and decentralized control.
For software projects, a DVCS with a central remote usually covers all the relevant needs. However for machine learning use cases, there are still a few things missing here. Most DVCS lack native support for large files, necessitating special handling for datasets and models.
Model and Data Versioning in Machine Learning Development
Let's review how versioning comes into play for components that are unique to the Machine Learning lifecycle.
1. Model Versioning
Considerations for model versioning include assigning unique versions, monitoring changes, and identifying optimal models. DagsHub streamlines this process by facilitating parallel testing and isolation, allowing a centralized comparison of performance for all logged model experiments.
2. Dataset & Data File Versioning
In the realm of data versioning, the correct approach depends on your specific use cases, and can be divided into 3 main strategies:
- Non-changing data – your data is static and never changes. This is extremely uncommon in real-world production use cases.
- Add-only data – your data is collected and grows over time, but existing data files don’t change themselves. In this use case metadata may change, for example the annotation of datapoints or predictions run on them by models may evolve over time. This is by far the most common case.
- Data file changes – your data files actually change as well, for example the pixels in an image file change over time.
For each use case, there is a different approach to data versioning:
- For non-changing data, a simple approach involves saving a link to the data location, ensuring easy access without the need for complex versioning.
- For add-only data, you can save the metadata in a table with a timestamp value (ideally manage changes to that metadata table as well), and then treat the timestamp as the version (give me the dataset before data X).
- For data file changes, you need to do 2 as well as actually manage file hashes since that’s the only way to know if file contents changed between versions.
Unlike hash-based methods, point-in-time versioning captures specific moments in the dataset's evolution, enabling users to reference and reproduce exact dataset states. Efficient rollback mechanisms allow reverting without recalculating hashes, providing valuable temporal granularity for managing large-scale datasets in machine learning and data science.
3. Managing Test and Corner Case Datasets:
You don’t only version data for training. For production use cases, you’ll have datasets for model evaluation, and for testing against specific corner cases where you need to verify the model’s performance. Since these datasets will grow and change over time, applying strategies from (2) is critical for being able to properly compare model versions and make sure your model doesn’t fail catastrophically in important cases.
ML Project Versioning with DagsHub
DagsHub provides a central solution for versioning all ML lifecycle components including data, models and code.
DagsHub offers solution for both scenario 2 and 3, with Data Engine offering a simple highly scalable point-in-time versioning, and DagsHub’s hosted DVC management system solves for cases in which data files change themselves. This approach covers all strategies for data & model versioning, providing a best of both worlds solution that is scalable and fully reproducible.
Here is how we do it:
- Extending Git:
DagsHub extends the capabilities of Git, the most popular Distributed VCS, to provide a holistic solution for ML project versioning. This integration ensures a centralized and organized repository where you can meticulously track changes made to your model code, hyperparameters, and training data. - Data Management with Data Engine and DVC:
DagsHub not only manages code but also addresses data management through our Data Engine component and our hosted DVC management system. This ensures that changes to your datasets are systematically recorded and versioned, enhancing the reproducibility and reliability of your ML projects. - Experiment Tracking with MLflow:
The platform integrates seamlessly with MLflow for comprehensive experiment tracking. By leveraging MLflow, DagsHub provides a systematic approach to recording parameters, metrics, and artifacts, allowing for a detailed understanding of the experimentation process. - Model Versioning with MLflow:
DagsHub enhances model versioning using MLflow, allowing you to version and track models efficiently. This encompasses not only the model code but also the associated hyperparameters and trained weights, ensuring a complete and traceable history of your models. - Model Registry with MLflow:
The inclusion of a model registry within MLflow further solidifies DagsHub's capabilities. This registry enables the systematic labeling of models that meet deployment specifications, streamlining the deployment process and providing a centralized hub for managing different versions of your models in production.
In summary, DagsHub provides full coverage for versioning the entire ML lifecycle.
To learn how to implement data and code versioning with DagsHub, check out this doc.
Conclusion
Version control is an indispensable tool for ensuring reproducibility, collaboration, and traceability in machine learning. By adopting appropriate VCS practices, ML practitioners can enhance the rigor, efficiency, and reliability of their research and development efforts.