Introducing the Machine Learning Reproducibility Scale
- Dean Pleban
- 7 min read
- 5 years ago
Co-Founder & CEO of DAGsHub. Building the home for data science collaboration. Interested in machine learning, physics and philosophy. Join https://DAGsHub.com | DagsHub Co-Founder & CEO

Quantifying machine learning reproducibility and presenting a unified ranking system for project reproducibility
The reproducibility of machine learning projects is a recurring topic, brought up in many different contexts – both in academia and industry.
There are a lot of opinions, mainly focused on tooling, which is great but can lead to a focus on features instead of solving concrete machine learning problems. Meanwhile, it seems there hasn’t been a lot of work done on providing a way to quantify a given project’s reproducibility, which means a lot of these discussions remain abstract, and perhaps less useful to practitioners looking for a way to gauge their work and decide how to improve it on the reproducibility front.
Many times, evaluating how easy it will be to reproduce a given project is a big challenge. This discourages people from building on top of existing work, causing re-invention of wheels, and contributes to distrust in open source data science projects.
But it doesn’t have to be that way. In this post, I’ll try to provide a concrete 5-star ranking system, as well as a report that can be added to machine learning projects that can help others make sense of how easy it should be to reproduce a project they are interested in.
Two different types of machine learning reproducibility
Generally speaking, reproducibility is a term that comes from the scientific domain, where it is defined as:
For the findings of a study to be reproducible means that results obtained by an experiment or an observational study or in a statistical analysis of a data set should be achieved again with a high degree of reliability when the study is replicated (repeated).
In our case, we can split this into two separate types of reproducibility:
- Technical Reproducibility
- Scientific Reproducibility
Here technical reproducibility means that by running the contents of the project, we achieve the same output, whereas scientific reproducibility means that the claims of the experiment are also verified by the output of the run.
We should distinguish between these because scientific reproducibility might be more qualitative in some cases, for example, GAN projects, where it’s hard to do a quantitative comparison of results, and many papers rely on “eyeballing” the quality of outputs.
Technical reproducibility, on the other hand, is purely quantitative. In the GAN example, technical reproducibility means that generating the run will result in a model with the same weights. This can be definitively evaluated by comparing weights.
This highlights another difference – technical reproducibility will usually entail logging or hard-coding the random seed to get the same results. Scientific reproducibility is somewhat the opposite – if you can’t get the same scientific result with a different random seed, it's not scientifically reproducible.
This post will focus on technical reproducibility only.
The five-star system
The five-star system sets clear criteria for the reproducibility of an ML project. It consists of the following components:
- Code
- Configuration
- Data (+Artifacts)
- Environment
- Evaluation
I think this order also corresponds to the difficulty of achieving each stage, though obviously, that is open for debate.
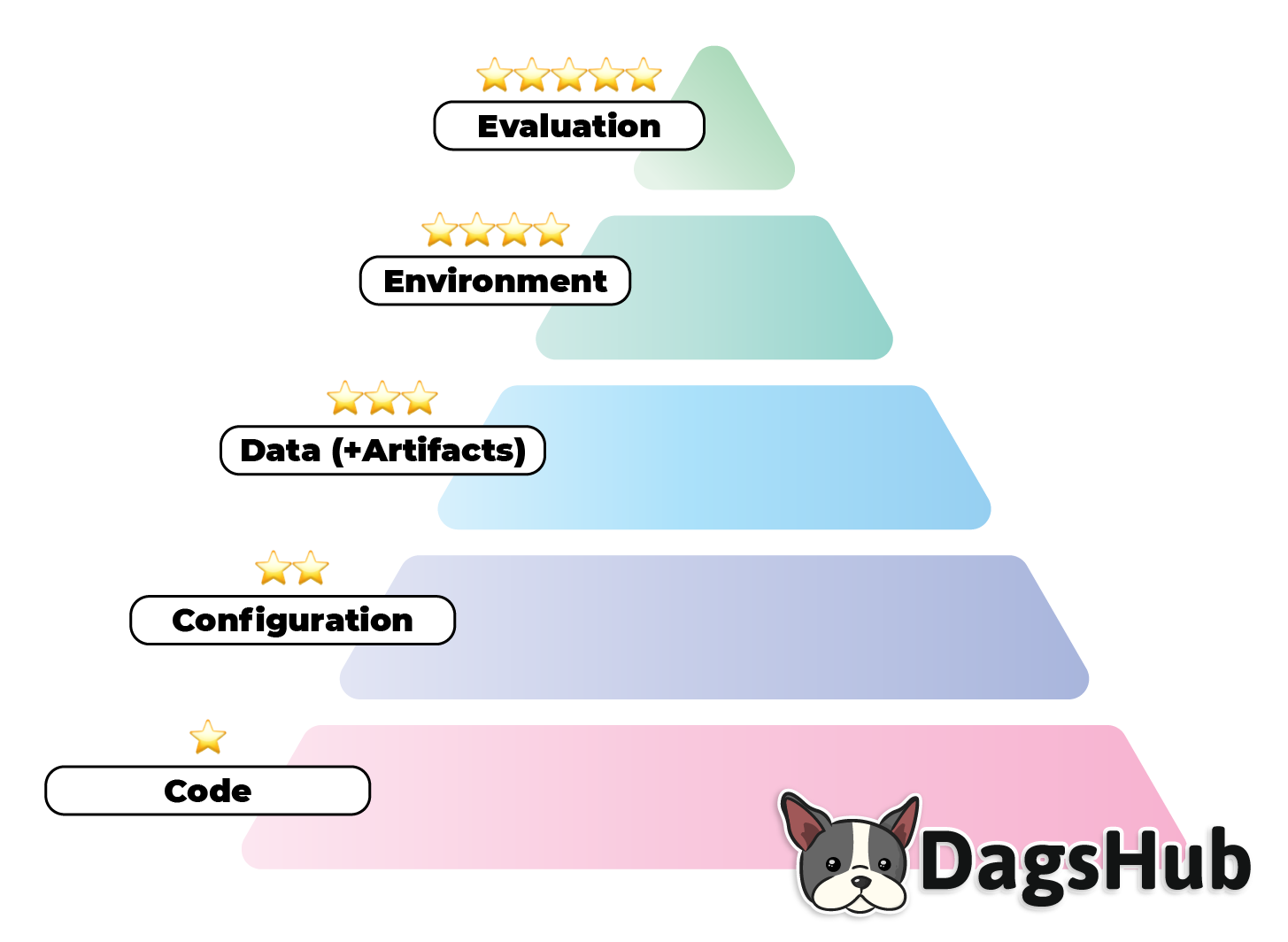
Let’s dive into each stage.
⭐️ Code
Meaning: Your code can receive an input, run end-to-end, and produce the expected output. The input here will usually be a dataset, but might sometimes be something else, like a model in an interpretability project. The output is usually a model or some “insight” in the form of a chart or metric.
Concrete criteria:
- Your code runs without errors when receiving correct input
- You have an example input on which the code can run – e.g. if your project is an object detection project, you have some dataset that is either saved or downloaded and on which the model will run without errors.
- For the input above, running the code multiple times will yield the same output.
Tools that can help:
- Git
In practice, many (but not all) projects that release their code comply with this stage. They have an example dataset, and code which runs on the dataset and returns a file with metrics that showcase that the model has learned what it should have.
⭐️⭐️ Configuration
Meaning: You have a clearly defined configuration file, that is committed alongside your code, and defines the configurable parameters for the given run. The code uses this configuration file to set the parameters within the run, and they are not written in an ad-hoc way.
Concrete criteria:
- You have one or more configuration files (these can be
YAML,JSON, or something else) that encompasses all configurable parameters for the experiment. Important clarification: this doesn’t mean that e.g. all model parameters must appear in this file, but that any parameter that you specifically configure must appear here so that it’s both easy to see which parameters were experimented with, and to modify them to build on the existing project). - The code uses the configuration file to extract the parameters and input them into their respective functions. This means that if you have a parameter called
epochswith a value of 5, which holds the number of epochs to train a model. If the value is changed to 6, the model should now train for another epoch. This doesn’t necessarily need to be Python code, it can be addressed by creating a Makefile that passes the configuration parameters as command-line arguments to the code. - Multiple runs with the same configuration yield the same result. This expands on stage one since it means that the project is reproducible for any set of configuration parameters, not just the selected one used in the published version.
2. All non-deterministic functions have a seed that is set within the configuration file (i.e. random seeds must appear in the configuration file).
Tools that can help:
- Hydra
- Git
- Experiment tracking tools (e.g. MLflow)
This step is already not always found as part of a typical project. In many cases, the configurations are tracked outside the project’s published location, which means it’s hard to directly connect the configuration/s used with the, and that configurations that weren’t successful in producing the final results can’t be evaluated and might remain hidden permanently.
⭐️⭐️⭐️ Data (+ Artifacts)
Meaning: The data you rely on is managed alongside your code. It can be easily modified to test the model with other datasets. If your project has significant resource requirements and can be split into discrete steps (e.g. data processing, training, etc.) then the artifacts of each stage are also tracked to enable testing of each stage’s reproducibility separately.
Concrete criteria:
- Your dataset is managed alongside your code. In some cases, this means that it is downloaded beforehand, or it might be streamed, but it should exist in the context of the project, in such a way that you can easily retrieve it to run an experiment end-to-end.
- Dataset structure and requirements are documented. This means that the data interface is clear, in such a way that building other datasets to run the experiment should be a straightforward process.
- Data is easily modifiable. This means you can replace the dataset used in the paper with other datasets that comply with criterion 2., and successfully run the model.
- For resource-intensive projects – The project pipeline is split and intermediate artifacts are tracked and managed alongside code. This means that if you have a preprocessing step and a training step, a collaborator can run only one of the two and receive testable outputs.
For tabular data which is append-only, but where historical data never changes, it might be enough to save the query and time filter that produced the subset of data used for training. A good example of this is central logging or clickstream data. But before you write this step off, remember that many times data that seems like it will never be modified is eventually modified.
Tools that can help:
- DVC
- LakeFS
- Dud
- Dolt – For tabular data only
- TerminusDB – For tabular data only
⭐️⭐️⭐️⭐️ Environment
Meaning: Your environment is tracked and documented in such a way that the specific software versions used can be downloaded, and the specific hardware can be set up to achieve the same settings in which the original experiment was run. The environment of an experiment means all software and hardware versions used when an experiment was run. Examples of this are PIP packages, your Python version, the operating system you use, and which GPU you ran the experiment on.
Concrete criteria:
- You have a list of all packages used. In the case of Python, packages can be documented in a
requirements.txtfile. - You have an example environment in which the project runs without errors. The easiest way to accomplish this is with a Docker image, which will also hold things like the specific OS and Python version constant. Note that in some cases, especially in deep learning, Docker might not be enough, and you need to describe the specific hardware and driver versions used (in the case of GPUs for example), since Docker is not an actual VM.
- If your project relies on specific hardware, it should be presented with documentation of setup. This one is pretty straightforward.
Tools that can help:
- Docker
pip freezeconda env export- Python-dotenv
⭐️⭐️⭐️⭐️⭐️ Evaluation
Meaning: You can experiment with the run results easily. This is especially relevant if the output of the project is operational, i.e. a model that predicts/generates outputs. This can range from a simple API to a full-blown UI, but it should be able to work with the reproduced output in such a way that will enable a qualitative comparison between run results.
Concrete criteria:
- You can easily use the project output model to predict/generate results from custom user input.
- You can easily qualitatively compare the performance of outputs from different project runs over different data or configuration settings.
Tools that can help:
- Streamlit
- Gradio
The ML reproducibility report
The ML reproducibility report is a markdown file that can be added to projects (saved as REPRODUCIBILITY.md) to provide concise documentation on the state of the project’s reproducibility. You can copy it from here or download it from this link.

# Machine Learning Reproducibility Report
This document helps provide a concise representation of the project's reproducibility ranking.
## 1. Code
* [ ] Runnable code for the project exists in the following project: https://dagshub.com/{user}/{project_name}/
* [ ] The example input is located in this link: {link_to_input} (this must be a proper link, ideally tracked as part of the project). Note: using this input in a project run should achieve the stated results without errors.
## 2. Configuration
* [ ] The following files include all relevant configuration parameters for the project:
- {params_1}.yml
- {params_2}.yml
- ...
Note: make sure that changing the parameters in these files will modify the project's actual run parameters.
## 3. Data (+ Artifacts)
* [ ] All project data and artifacts can be found here: {link_to_project_data}.
* [ ] The structure/schema of input data is the following: {Add data structure/schema here}.
* [ ] If running the project is resource intensive – the project consists of the following steps:
1. Data preprocessing:
- Code: {link to code for data processing step}
- Outputs: {link to output 1}, {link to output 2}
2. Model training:
- Code: ...
- Outputs: ...
3. ...
## 4. Environment
* [ ] Software package documentation: {link to `reuiqrements.txt` or equivalent file}
* [ ] Example environment: {link to docker hub or other container registry with the environment docker image}
* [ ] If the project uses specific hardware – the hardware needed to run the project properly:
- 2 V100 GPUs
- At least 32GB RAM
- ...
## 5. Evaluation
* [ ] To evaluate the model go to: {link to hosted Streamlit app or Google Colab notebook that enables users to perform predictions on arbitrary inputs}
* [ ] Evaluation app code:
- {link to file with Streamlit app code}
- In order to run this locally: {link to instructions on running the streamlit app}Summary
This post is an attempt at providing concrete, actionable steps that any project owner can take to significantly increase the reproducibility of their project. The report we provide enables others to quickly verify the reproducibility status of a project so that projects could be filtered according to their reproducibility score. Would love to hear your feedback on the structure, and thoughts on the process itself



