The Ultimate Guide to Data Preparation for Machine Learning
- Sundeep Teki
- 10 min read
- 2 years ago
Dr Sundeep Teki is an established AI Leader, Consultant and Coach with 16+ years of diverse international experience across leading organizations at Big Tech | AI Leader

1. What is Data Preparation for Machine Learning?
Machine learning models learn patterns from data and leverage the learning, captured in the model weights, to make predictions on new, unseen data. Data, is therefore, essential to the quality and performance of machine learning models. This makes data preparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization.
There is more to data preparation for machine learning beyond just collecting and feeding larger volumes of data to the machine learning models. Sometimes, “more is less”, and incorporating additional datasets can limit the accuracy of models by introducing spurious correlations. If the data is inaccurate, incomplete, inconsistent, or biased, the machine learning model’s predictions will be flawed, which may lead to incorrect conclusions or business decisions and adverse impact on the customer experience. This realization has fuelled the recent adoption of data-centric AI strategy over model-centric approaches to obtain greater model accuracy and business outcomes.
Improved data preparation techniques focused on efficient data labeling, management, augmentation and curation while keeping the model relatively fixed in its architecture has led to significantly better model outcomes. For instance, work by Nvidia has demonstrated that a computer vision model for classifying handwritten Roman-MNIST numbers improved its accuracy by 5% with the use of an optimized data preparation pipeline that enhanced the quality of the training dataset.
In this blog, I will describe how to prepare data for machine learning in depth. Here are the different data preparation techniques we will look at:
- Stage 1: Data Collection
- Stage 2: Data Annotation
- Stage 3: Data Preprocessing
- Stage 4: Feature Engineering

Figure 1: Importance of Data Preparation for Machine Learning as explained by engineers at Google (source)
2. Why do you need Data Preparation for Machine Learning?
While data preparation for machine learning may not be the most “glamorous” aspect of a data scientist’s job, it is the one that has the greatest impact on the quality of model performance and consequently the business impact of the machine learning product or service. Typically, flashy new algorithms or state-of-the-art models capture both public imagination and the interest of data scientists, but messy data can undermine even the most sophisticated model.

Figure 2. Data preparation for ML is a critical yet under-appreciated process
There are numerous examples of how poor quality data has had negative consequences for businesses. For instance, bad data is reported to cost the US $3 Trillion per year and poor quality data costs organizations an average of $12.9 million per year.
Machine learning models rely on the quality of the training dataset to teach them to make predictions on unseen data. If the training dataset is incomplete, inconsistent, biased, or inaccurate then this will also be reflected in the model performance and lead to results that are unreliable, misleading or potentially harmful.
The process of data preparation changes the raw data into a more structured and usable dataset that unlocks hidden patterns buried in the noise. Data preparation techniques remove irrelevant noise in the data to help you discover meaningful patterns and insights that are valuable for solving your problem at hand.
In recent times, we are witnessing the rise of large language or image models that are trained on tremendous amounts of data. For such use cases, automated data preparation becomes crucial to develop models quickly.
Data preparation also helps you identify any biases in the data which may potentially cause discriminatory or unfair outcomes to certain groups of users. Removing biases from the data is a cornerstone of ethical and responsible machine learning development, and creates a positive impact for everyone.
3. What are the different Data Preparation Steps?
Before starting to collect data, it is important to conceptualize a business problem that can be solved with machine learning. Only once you form a clear definition and understanding of the business problem, goals, and the necessity of machine learning should you move forward to the next stage of data preparation.
Data preparation involves multiple processes, such as setting up the overall data ecosystem, including a data lake and feature store, data acquisition and procurement as required, data annotation, data cleaning, data feature processing and data governance.
In large ML organizations, there is typically a dedicated team for all the above aspects of data preparation. For the particular business problem, the team needs to ensure that carefully cleaned, labeled, and curated datasets of high quality are made available to the machine learning scientists who will train models on the same datasets.
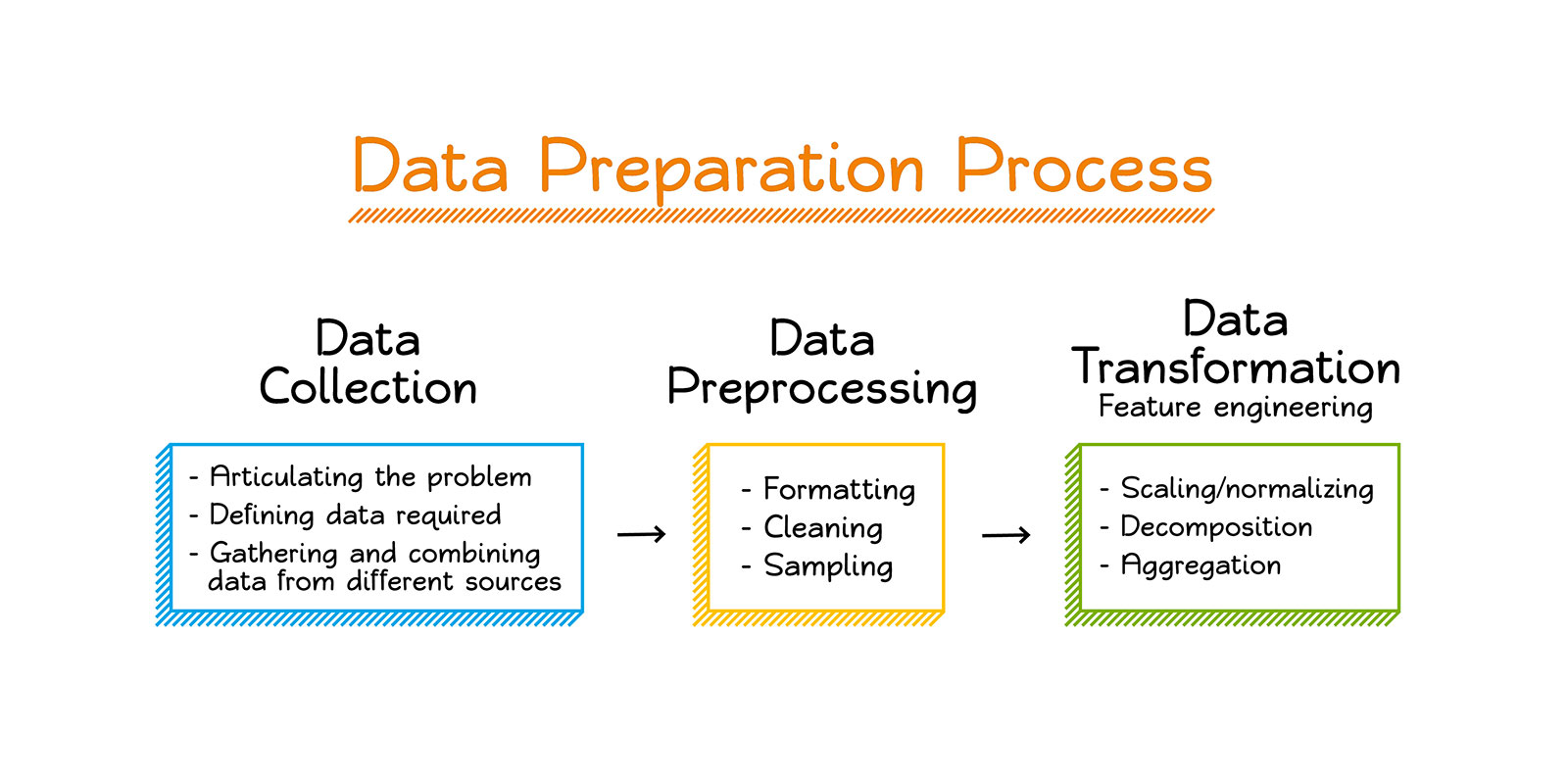
Figure 3. An overview of the data preparation process for machine learning datasets.
3.1 Data Collection
Data for machine learning can be either structured like tabular data, semi-structured like XML or JSON formats, or unstructured like text, images, audio and video recordings. Apart from the type of data, the domain of the business use case is also relevant for data collection. For instance, healthcare or financial data is subject to several regulations and it is not as easy to collect high quality data for these domains vs. data for other domains like marketing or e-commerce.
In addition to the type of data, the volume of data also dictates the data collection process. If the volume of data available in-house is not sufficient, you may have to purchase data from data brokers or generate synthetic data using machine learning. Synthetic data has several benefits over real data as it is a fast, flexible and cost-effective and a controllable way to generate as much data as you need. However, synthetic data is not without its limitations such as lack of realism in terms of capturing the complexity of real-world data as well as bias and privacy concerns. Therefore, the use of synthetic data must be carefully evaluated depending on the particular use case and data requirements.
External data can be acquired from academic or public data repositories such as Kaggle, Google Dataset Search, AWS Data Registry or collected via web scraping from relevant websites or social media accounts.

Figure 4. Building an accurate ML model requires clean, labeled and reliable data sets.
3.2 Data Annotation
Annotation of data, or providing labels is fundamental for machine learning models to learn patterns in the data. For unstructured data like images, text, audio, video, labeling is key to make the machine learning models understand what information to learn in the data. For instance, a computer vision model for an autonomous vehicle is trained with data in which other vehicles, pedestrians and traffic lights and signs are labeled with bounding boxes.
Data may be annotated either in-house or through external vendors. Labeling for use cases like identifying objects in images might be easier for annotators to perform. However, for complex use cases like speech recognition in noisy environments, annotators may struggle to provide high quality labels. This requires thorough training, practice, and feedback from domain experts.
In today’s era of large language models, there is also an increase in data reviewers who provide human feedback data and evaluate prompts to large language models and their outputs in terms of how safe and trustworthy the results are. Content moderation and fake news have become grave issues for societies at large, especially in the context of elections and use of hate speech or offensive speech, and data annotators have a very important role to play in mitigating their adverse impacts on users.
The cost of data annotation and your project timelines and budget should also be considered to decide whether to hire your own data annotators or use third-party vendors.
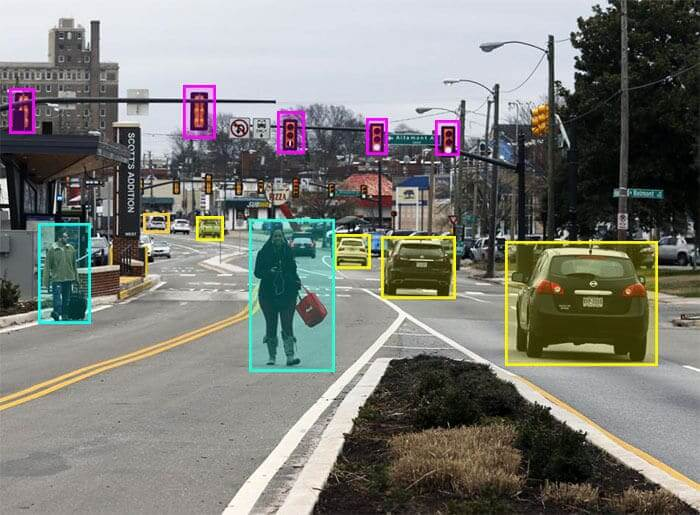
Figure 5. Example of data annotation of objects in an image.

3.3 Data Preprocessing
Data preprocessing involves several steps to clean, correct and transform data into usable features. There are many approaches for data preprocessing:
Handling missing data
Quite often, datasets come with missing values. These omissions might occur due to manual errors or even technical errors during the preparation of datasets. Common strategies to deal with missing data include imputation, interpolation and deletion.
Imputation involves replacing missing values with estimated values based on statistical properties of the underlying data. For instance, you can replace missing numeric values by their median or mode.
Handling outliers
Outliers are data points that are so different from the rest of the data that they may be either due to errors in measurement of data or data entry issues or may actually represent some extreme patterns in the data. You can identify outliers by visualizing the distribution of data and check for any data points that are significantly far from the mean. Depending on the use case, removing outliers is necessary to not mislead your machine learning model about such data patterns. For removing outliers, you can use statistical methods such as getting rid of any data points that are more than three standard deviations away from the average.
Handling irrelevant data
Datasets for machine learning problems often contain several columns or features. However, not all columns may be relevant to the problem at hand. For instance, the product ID code of a product on Amazon is not correlated to the user ratings and not predictive of the quality of the product. In such cases, you can safely remove such irrelevant features.
Handling incorrect data
Erroneous data is a common occurrence in machine learning datasets. The errors might be related to the values, data types, data format, null values etc. Identifying and cleaning such data points is helpful to remove noise from the data. Incorrect data may be addressed via data transformation or dropping the data points completely.
Handling imbalanced data
For machine learning problems focused on classification or categorization into different classes, it is important to have an equivalent amount of data from each class. However, real-world data is not uniformly distributed across classes and may have more data points from one class over the others. For example, in anomaly detection or fraud detection problems, the data points corresponding to the fraud or anomaly are typically ~1% of the entire dataset.
Imbalanced datasets can result in models that are biased towards the majority class and can be addressed via oversampling of the minority class or undersampling of the majority class. Other techniques such as synthetic data generation may also help you to balance the representation of all the classes in your training dataset.
3.4 Feature Engineering
Feature engineering is a critical data preparation step where you transform the preprocessed data into features that are relevant for the machine learning problem at hand. Crafting features is task-dependent and requires strong domain expertise.
Feature engineering can also be achieved through data transformation methods such as dimensionality reduction and logarithmic normalization. For instance, in audio signal processing or speech recognition models, it is common to take a log transformation of the input waveform data as our sound perception and hearing is logarithmic.
Feature engineering also involves feature selection that can be achieved through techniques such as L1-regularization. Selecting the optimal set of features that are correlated with the target variable increases your chances of having a more accurate and reliable model.
Popular examples of features include the TF-IDF (Term Frequency - Inverse Document Frequency) in natural language processing that combines the intuition that the frequency of a word in a document and its rarity across the entire corpus of documents has informational power.
4. Data Preparation Tips
In this section, I will share some practical tips about data preparation for machine learning.
Choose quality over quantity
It is a common misconception that more data leads to better models. However, this is not always true and a better axiom is that better quality data leads to better quality models, especially in the context of large neural network models.
Data preparation is an iterative process
Data preparation is not a one-time effort but a continuous process that does not stop once the model is deployed. In fact, after deployment models often become stale due to data drift, i.e. a change in the distribution of real-world data vs. the distribution of the data in the training set. This necessitates sampling fresh data from the real-world data distribution to augment the training dataset, for instance, using active learning to adapt the training data to the changing real-world data distribution.
Automate your data preparation pipelines
Once you’ve established a specific process of data preparation techniques that transform your raw data into the training dataset, it is recommended to automate as many of the steps as possible. Automation can be achieved through your own code or via third-party applications such as Dagshub, DVC and others. The use of tools that allow for greater automation of the overall machine learning workflows including data preparation can save you a tremendous amount of time and also make it easier to troubleshoot any issues.
Do not forget about data governance
In addition to implementing best practices and automated pipelines for data preparation steps, it is imperative to also invest in establishing a comprehensive data governance and data management strategy. Data governance is a set of processes that promote better management of business data, unlocking the true value of data by ensuring that it's more accessible, reliable, secure, and compliant. Concomitant with AI becoming more ubiquitous and impactful, there is an increase in regulations such as the European Union AI Act to protect citizens’ privacy, personal data and online safety.
Good implementation of a robust data governance strategy results in long-term benefits that aid data preparation for machine learning, such as:
- Better data analytics
- Better decision making
- Better Data consistency
- Error-free data
- Improved data quality
- Decreased operational or data management costs
- Increased access to data from all stakeholders
Resources
Armed with a clear understanding of the various steps for effective data preparation for machine learning, you are now ready to progress to implementation of these best practices. Here are a few curated resources and tutorials for you to get started:
- https://dagshub.com/blog/launching-data-engine-toolset-for-unstructured-datasets/
- https://developers.google.com/machine-learning/data-prep/process
- https://aws.amazon.com/getting-started/hands-on/machine-learning-tutorial-prepare-data-with-minimal-code/
- https://deepchecks.com/preparing-your-data-for-machine-learning-full-guide/
5. Conclusion
Accurate machine learning systems are built on the foundation of high quality data. Data preparation for machine learning involves several different steps including data collection, annotation, preprocessing, and feature engineering. Through these transformations, we progressively reduce or eliminate noise in the data and make it more readily usable for machine learning models to learn from and generate reliable predictions.
In today’s age of large models such as GPT-4, DALL-E 3 or Gemini, the importance of data-centric AI cannot be underestimated. We are witnessing the rise of smaller models, e.g. Mixtral that are trained on a lesser amount of data albeit data with higher quality and curation, outperform the larger models.
Automating the data preparation steps through pipelines, processes and tools definitely eases the task of data preparation, and provides greater transparency to build reproducible machine learning models.



