How to Evaluate Generative Image Models
- Jesús López Baeza-Rojano
- 9 min read
- 2 years ago
Senior Machine Learning Engineer @ Busuu | Senior Machine Learning Engineer

Exploring the Impact of Generative Image AI Across Industries
Aren't you impressed at how easy it is to generate stunning artificial images nowadays? It’s truly incredible! However, evaluating the quality of these produced images from the latest generative models isn’t as straightforward as you might think. Assessing their performance is a detailed process that varies based on the specific use case being evaluated. Nowadays, it has become faster and more approachable, thanks to the advancements in this field.
The journey of artificial image creation has seen amazing progress, thanks to the power of Generative Artificial Intelligence (Generative AI). This evolution found applications across several industries. For instance, in fashion, Adidas leverages Generative AI to produce unique and personalized shoe designs via its customization platform. This enables customers to select color schemes and patterns for their clothing and footwear. In the gaming sector, Epic Games, the creators of Fortnite, employ generative models to craft lifelike landscapes, sculpting mountains, forests, and oceans, ensuring every pixel whispers adventure. Furthermore, in advertising, Coca-Cola, an iconic brand, orchestrates these models to compose personalized ad visuals, with each pixel tailored to match consumer preferences, thus creating bespoke campaigns. The result? A symphony of sales and brand loyalty.
If you want to know how these companies evaluate Generative Image Models, you are in the right place!

Painting with Algorithms: Understanding the Magic behind Generative Image Models
First of all, let’s understand what these image-generation models are. These are like the artists behind the canvas. Their mission is to create something out of nothing. Specifically, Generative Image Models (GIMs) specialize in crafting realistic and coherent images from scratch. These models use complex algorithms and deep learning techniques to learn patterns and features hidden within the training data.
Several techniques have been developed to achieve this goal, and here are some of the principal ones:
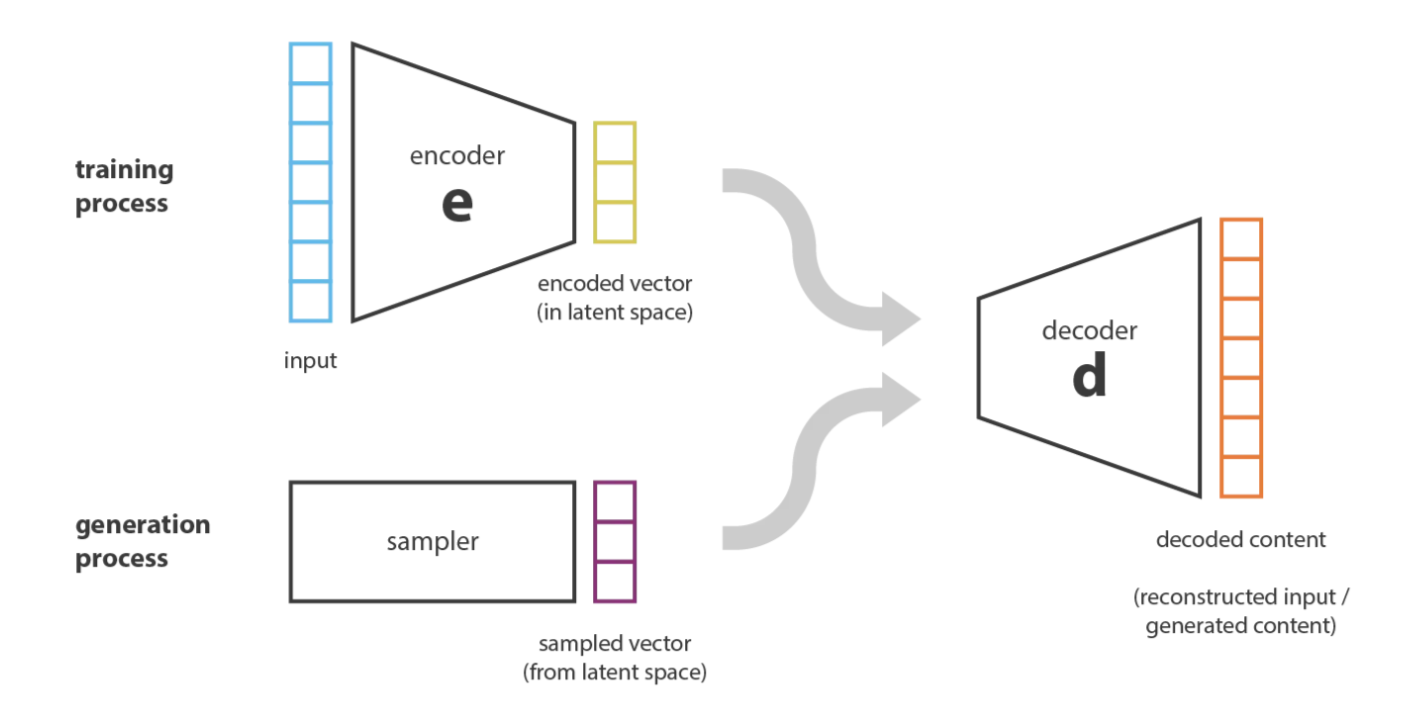
- Variational Autoencoders (VAEs): This technique is split into two phases. First, these models learn and encode input data into a latent space, often a mixture of Gaussian distributions. Then the decoder converts the latent space back to the original input, generating high-quality images by maximizing likelihood.
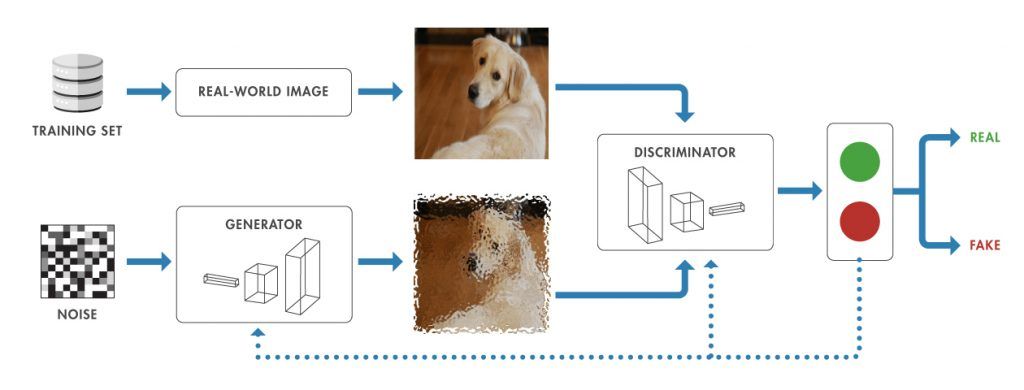
- Generative Adversarial Networks (GANs): They consist of two neural networks. The generator learns to create realistic images from random noise. Meanwhile, the discriminator evaluates real images against the generated ones. The training process goes back and forth until the discriminator can no longer distinguish real from generated images.
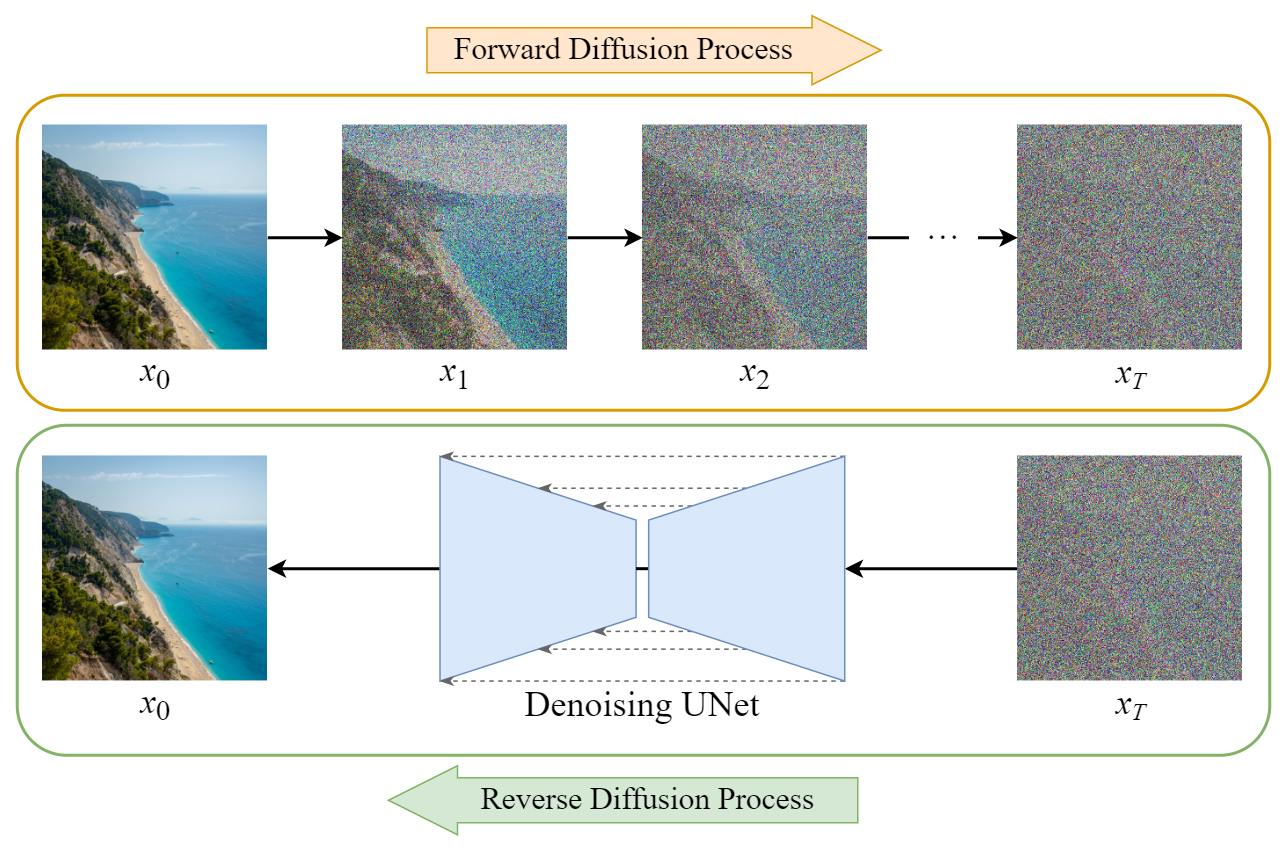
- Diffusion Probabilistic Models (DPM): They belong to the class of latent variable generative models in machine learning. These models capture the underlying probability distribution of data by modeling a gradual denoising process. The process is split into two. The forward process starts adding noise to the original image. And the reverse process in which the model reduces the noise to regenerate the original image. This process makes the generation of completely new and high-quality realistic images possible.
In the expansive landscape of model implementations, these stand out as the current leading GIMs:
It is an independent research lab that explores these models. It contributes to advancing AI-based image generation and is known for the high quality of the realistic visuals it generates from text prompts.
Another AI system developed by OpenAI can produce realistic images based on text inputs. It gained popularity for its ability to generate diverse and imaginative visuals. Users can input textual descriptions, and DALL-E generates corresponding images.
It is another powerful model from Stability.AI for text-to-image generation. It leverages diffusion models and deep generative neural networks to create compelling visual outputs.
“GIMs are like curious artists, looking at the vast gallery of data, learning its hidden patterns, and then painting new masterpieces from scratch. They’re the alchemists of pixels, conjuring images that never existed before—a symphony of creativity conducted by neural networks.”

Beyond the Norm: Comparing Evaluation Metrics for Classical and GIMs
The differences between these kinds of models have become a focal point of exploration and innovation. The traditional approach to model evaluation has been based on quantitative metrics and performance benchmarks. However, the arrival of generative models for image creation introduces a standard shift that involves a different evaluation approach to assess these new methodologies.
Traditional Models:
These models work with data based on programmed rules, creating simulations. However, they may not fully capture the real-world complexity.
- They follow strict rules. E.g. Specifying if a certain image corresponds to a Class A or a Class B, not anything in between.
- These models have a single job. They classify dogs or predict stock prices, but they are not able to generate an image from scratch or compose a song.
- Therefore, their metrics are quantitative, focused on accuracy, precision, recall, F1 score, Mean Squared Error or MSE, etc. Depending on the specific task.
GIMs:
They are trained to create new data, rather than making predictions about specific datasets.
- They learn from existing data and replicate these patterns into a new image sample.
- Evaluation involves assessing the quality and diversity of generated samples, which may require specialized metrics like Inception Score, Fréchet Inception Distance or FID, or perceptual similarity metrics.
In summary, while traditional models excel in specific tasks, GIMs require a more holistic evaluation approach, considering both statistical properties and visual fidelity.

Methods for Evaluating GIMs
The challenge of evaluating these powerful models is to decipher the essence of these creations. Let's dive into the interesting methodologies and metrics that form the core of this captivating evaluation experience:
Human Evaluation:
The human verdict adds a subjective touch to the evaluation. Despite its reliability, this kind of evaluation has some drawbacks to consider: It is expensive, time-consuming, and prone to bias. Therefore, it is usually considered as a supplementary method for evaluating these models.
Pixel-Based Metrics:
An alternative method for assessing generative models involves the comparison of generated images with real ones from the same domain, utilizing pixel-based metrics like mean squared error (MSE), peak signal-to-noise ratio or PSNR, or structural similarity index or SSIM. These metrics dig deep into a pixel level, taking into account that the closer the pixels, the higher the image quality. However, pixel-based metrics also have some limitations, including sensitivity to image transformations, ignoring high-level semantic features, and overlooking the aspects of diversity and innovation.
Feature-Based Metrics:
If we dive deep beyond pixels, there are neural networks, such as convolutional neural networks (CNNs) or GANs. And these kinds of networks are responsible for finding high-level features, like shapes, textures, colors, styles, etc. The metrics related to this method are Inception score (IS), Fréchet inception distance (FID), and perceptual path length or PPL. They compare the feature distributions of the generated and real images and determine how well this model preserves the quality and diversity of the original domain.
Task-based Metrics:
Evaluating generative models can also involve utilizing task-oriented metrics, and gauging how well the generated images serve downstream functions like classification, segmentation, captioning, or retrieval. These metrics offer insights into the practicality and suitability of the generative model for specific tasks and domains. Examples of task-based metrics include classification accuracy, segmentation accuracy, captioning BLEU score, or retrieval precision and recall. However, it's important to acknowledge that the effectiveness of task-based metrics hinges on the choice and performance of downstream models and may not encompass the broader aspects of image generation.
Novelty-Based Metrics:
These metrics gauge the novelty and diversity of generated images in comparison to existing ones within the same or different domains. Novelty-based metrics provide insights into the creativity and originality of the generative model. Examples of novelty-based metrics include nearest neighbor distance, coverage, or entropy. Nevertheless, it's important to note that while these metrics highlight creativity, they may not consider the realism and relevance of the created images and might favor unrealistic or irrelevant results.
Assessing GIMs involves using different metrics. Each metric plays a special role in the quest for computer-generated creativity.

Pixels to Applications: Real-world Use Cases and Evaluation Metrics
Let’s dive into some real use cases of GIMs and the evaluation metrics associated with each.
Image-to-Image Translation:
- Use Case: These models can convert images from one domain to another (e.g., night-to-day translation, greyscale to color). E.g. Content generation in the gaming industry.
- Metrics: Task-specific metrics, such as PSNR (Peak Signal-to-Noise Ratio) or SSIM (Structural Similarity Index), to assess the quality of the converted images.
Anomaly Detection and Data Augmentation:
- Use Case: They are used for generating images with anomalies, such as identifying defects in manufacturing, for having a wide range of different image samples to train and evaluate the model. These models can also augment training data by creating supplementary image samples, improving model generalization. E.g. Aircraft anomalies.
- Metrics: In this case, a good evaluation metric is the human touch, because it is difficult to evaluate if a synthetic image presents an anomaly or if it is just a low-quality generated image sample. Also, metrics like precision, recall, and F1-score are relevant for anomaly detection tasks. These metrics balance the trade-off between identifying anomalies and minimizing false positives.
Medical Imaging and Diagnosis:
- Use Case: GIMs help in creating synthetic medical images for training deep learning models. They can also improve the quality of poor medical images. E.g. Lung cancer x-rays.
- Metrics: MSE (Mean Squared Error), PSNR (Peak Signal-to-Noise Ratio), or SSIM (Structural Similarity Index) are possible metrics for assessing the quality of the generated images.
Image Synthesis and Style Transfer:
- Use Case: GIMs can create realistic images from scratch or modify existing images changing their style and content. Image synthesis and style transfer allow artists and designers to generate artistic elegance. E.g. Generate digital assets like NFTs.
- Metrics: The most used metrics include the Fréchet Inception Distance (FID) and the Inception Score (IS). They evaluate image diversity and quality. FID assesses the similarity between feature distributions of real and created images, while IS measures the quality of created images based on a pre-trained classifier.
The Art of Innovation: Challenges and Future Directions in Evaluating GIMs
Evaluating GIMs presents several challenges due to the unique nature of these models. Let’s delve into these challenges and explore potential future directions:
- High Dimensionality: Images are not simple, they are complex high-dimensional objects. Just a photo with 1 megapixel resolution has approximately 3 million pixel values. Evaluating the diversity and quality of synthetic images becomes difficult due to this dimensionality.
- Lack of Human-Perceptual Metrics: Due to its high dimensionality, there are a lot of details that are not perceived by the human eye. Therefore, human evaluation is a good supplementary method but not the only one to rely on to assess metrics.
- Mode Collapse: Some models suffer from this problem, where they generate limited variations of a few models instead of exploring the whole data distribution. Dealing with mode collapse is very important for improving diversity in generated samples.
- Representation vs. Replication: These models try to capture the essence of the data they learn from, rather than just copying it exactly. Finding the right balance is hard because very complex models like GIMs might just memorize examples, and too simple models might miss important details.
Evolution of GIMs evaluation:
- Hybrid Techniques: Future GIMs might combine different techniques, such as the strengths of GANs and transformers, joining the power of adversarial training and attention mechanisms. These models could generate even more diverse and high-quality images. Therefore, we might see a combination of evaluation methods with more accurate results.
- Refined Metrics: There will be new metrics that adjust better to each of these future GIMs.
- Uncertain Future: It’s been a journey of exploration, creativity, ethical considerations, and research, but we are sure that something even more powerful will come.
Concluding the Evaluation Journey for GIMs
We delved into the heart of the GIMs evaluation. Our journey began with a summary of the evolution of creating artificial images, illustrating how GenAI has significantly boosted the importance of image generation in various industries. Next, we provided an overview of what GIMs are, including different techniques and current top models.
Then we have seen what are the main differences between the traditional model and GIM evaluation. Besides, we mentioned different methods to evaluate these models and, the pros and cons they have. Real-world use cases were also discussed, shedding light on how these models are assessed in practical scenarios.
And, last but not least, we dived into the principal challenges of evaluating these models, and how they could evolve in the future. Truly fascinating, isn’t it?
Although we know these models are powerful and can create high-quality, diverse, and realistic images, it became evident that evaluating such models is not a straightforward task for various reasons. This is where researchers and the community involved in the utilization and development of these models play an important role. As we anticipate the developments in the GIM Evaluation realm, stay tuned for an exciting journey into the future of this cutting-edge field!



