Unraveling the Deep Learning Reproducibility Crisis
- Jinen Setpal
- 9 min read
- 4 years ago
Machine Learning Engineer @ DAGsHub. Research in Interpretable Model Optimization within CV/NLP.

What Descartes did was a good step. You have added much several ways, and especially in taking the colors of thin plates into philosophical consideration. If I have seen a little further it is by standing on the shoulders of Giants.” ~ Isaac Newton
We pride ourselves on our ability to build incrementally, adding steadily to the millions of petabytes of knowledge we’ve collectively been able to harness. Fantastic, isn’t it? Now imagine the giant is in fact a million little people in a trench coat held together by duct tape on a rickety fifty-foot ladder; Descartes & Newton in shambles.
Research Needs Democratization
Science, since time immemorial, has relied on the systemic replication of any presented result or finding. Reproducing experiments and their reported results remains a cornerstone of the validation of any scientific theory.
Following this understanding, the scientific community realized the severe Replication Crisis we’re facing in the fields of psychology and medicine: since experiments conducted within those fields involve a lot of subtle and uncontrollable factors, reproducing results from the past becomes nearly impossible, with the unfortunate consequence of putting many proposed hypotheses into question.
Computer Science, having created a sandbox of its own with powerful, logic-driven calculators, should be the first to develop immunity against the problem.
However, this might not be the case. Let’s take for example the Fall 2021 Reproducibility Challenge - an event designed to encourage reproducing recently published research from top conferences. Only 43/102 (~%42.16!) of the papers entered into the double-blind peer-review process were accepted – which means that more than half the papers, despite being written with reproduction as a priority, couldn’t actually be reproduced.
As with the scientific method, it’s imperative to explore the reasons why this prevails. A piece I believe may be crucial to this puzzle is research democratization – or lack thereof. Research in its reproducible state could exist but might be inaccessible to the scientific community at large. Here are a few reasons why —
Tšitiso ea Lipuo — The Language Barrier
One reason might be as simple as the language of science communication.
I used Google Translate to convert ‘The Language Barrier’ to a random language from its supported roster (in this instance: Sesotho). I got back ‘Tšitiso ea Lipuo’, which translates back into English as ‘Language Disruption’; translation, especially with limited data, is still far from perfect.
With the overwhelming majority of published research being exclusively in English, and Google Translate not being reliable enough to autonomously translate arbitrary articles, let’s explore how many people the standing research environment works to serve. Let’s start with some statistics on spoken English, from Wikipedia:
| Spoken | Count |
|---|---|
| Native | 360-400 million |
| Second Language | 750 million |
| Foreign Language | 600-700 million |
| Total | 2.05 billion |
For context: the world’s population stands at ~7.8 billion inhabitants – conservatively, this places only about 23.3% of the world population in a position to contribute to research today.
One of the most beautiful aspects of code-centric research is the fact that it only uses the English script – i.e. alphabets and numbers, with grammatical rules remaining strictly syntactical. It’s what allows projects like ChavaScript: a Hebrew version of JavaScript!
As a result, fluency in English would no longer be a requirement to understand a project. When research is centered around explaining decisions that may pique the reader’s interest, with source code translations themselves being near-perfect, the reader can fill in any gaps within translated explanations that Google may be unable to properly contextualize.
Writing papers, or playing Chinese Whispers?
Mark Rober, in his delightful video on powering a supercar, discusses the inefficiency of energy sources:
… instead of indirectly and inefficiently going through a bunch of different energy sources, and losing a bunch at every step along the way, it makes way more sense to just go directly to the source.”

Within a research context, the above quote highlights the challenge of a potentially lossy transfer of information. Academic papers, while being seemingly concentrated and visually pristine (\(\LaTeX\) my beloved), can be an inefficient medium. Here’s why:
- Domains of pure science – for instance, physics – fundamentally rely on research papers for documentation of relevant proofs, inventions, and discoveries.
- CS research almost always involves code. Similar to how scientific theory is written in tandem with mathematical proofs, it makes a lot of sense to develop documentation in tandem with the codebase – like open source projects!

Consequently, the research pipeline (at the very least, for the research labs I am a part of) generally involves developing the codebase in a git repository and taking down notes in a shared wiki or the like. The final paper, built from the wiki after adding all of the required boilerplate – lies susceptible to the information loss discussed earlier.
Ideas discussed and implemented throughout the entire duration of the project contain precious tidbits essential to a complete understanding of the research process. Many of these are found to be missing during reproductions – sometimes left almost implied within the text. Documenting the end results is a tiny piece of the picture, and building a discussion around the source of the research itself, highlighting sections, and expanding on their significance with the README.md as the designated point of entry has the potential to crucially document the process of getting those results – emulating the system developed for research, not in letter but in spirit. 🙂
𝚜𝚝𝚢𝚕𝚎 𝔤𝔲𝔦𝔡𝔢𝔩𝔦𝔫𝔢𝔰
Length restrictions for written content are relics I was sure I’d left behind back in high school. “Write 600 words on topic XYZ” – makes so little sense for anything, the least of which academic papers! Extending or shortening any text outside the optimal, desired length only works to convey the same set of information lossily, making it unnecessarily harder to understand the actual novel contribution.
Fortunately, it does seem like we are managing to make some progress in this department. Scouring through the top 15 conferences as listed by research.com, I managed to find minimum page counts for only 2 conferences. However, 13 of the 15 did still mandate maximum page counts. Both of the conferences accepting arbitrary-length papers did mention that submissions that deviate from the mean length of 7000-8000 words would be subject to additional scrutiny. This protects against authors intentionally obfuscating their contributions; in my opinion, a happy medium over the two hard limitations.
And then, there’s this blurb I discovered buried within the submission guidelines on one of those worldwide top 15 conferences:
(For accepted papers, up to two additional pages may be purchased at an additional cost per page; note that, at the time of submission, papers are required to adhere to the 6+1 format above.)”
I haven’t even gotten a chance to touch on journals exploiting monopolized markets, charging an arm and a leg to publish with them then turning around and charging more still for people to read it (Sci-Hub my precious). Arguments can be made regarding the utility provided by these journals, citing associated costs; but charging per page of information added without any additional scrutiny from a top-15 research conference certainly needs serious justification.
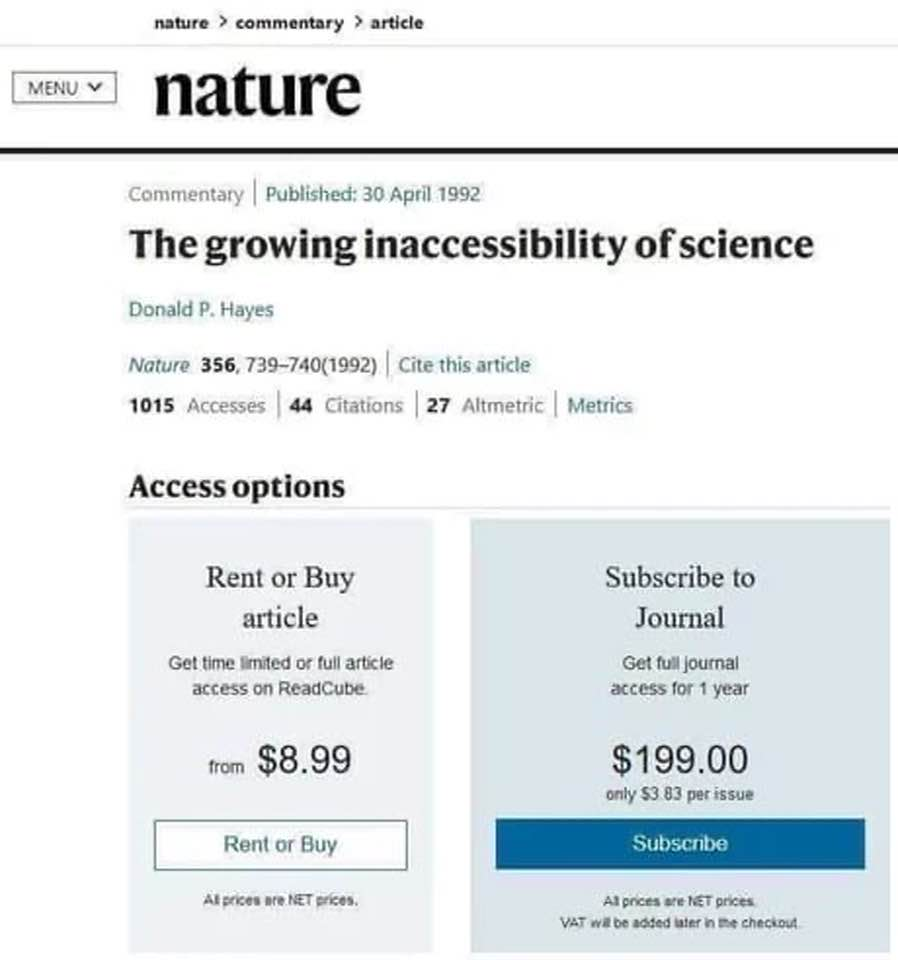

Papers Against Reproducibility
So far the reasons for the reproducibility crisis we’ve covered were somewhat technical. However, there are a few that relate to possibly misaligned incentives. Here are a few examples:
Besides claiming that 7 is a magic and lucky number, and not in fact the result of being the number immediately after the latest YOLO release, the recently launched YOLOv7 contains within its readme.md the following:
⚠️ Important note: YOLOv7 on Github not the latest version, many features are closed-source but you can get it from https://manaai.cn"
Going back to the ‘domain of pure science’ point from before; Dr. Albert Einstein could have simply told everyone \( E=mc^2 \), but without the 3-page manuscript explaining his incredible work, giving the opportunity for researchers to point out fallacies within the initial manuscript – it would’ve been an overall meaningless contribution to the understanding of the world around us. It simply makes no sense to publish closed-source research.
Then, there’s the spectacularly black-box approach taken by papers like Asm2Vec – they publish binary blobs instead of the source code. Intel’s Pin – a binary instrumentation tool – closed sourced its code, and fails to even maintain an active version history, only allowing the most recent versions for download with zero backward compatibility. Consequently, several older papers that list the Pin tool as a dependency cannot be used because the required version along with the source code is sitting on a private disconnected database (read: graveyard) awaiting the end of time.
This ties back to our original problem with the Replication Crisis – by preventing independent researchers from taking a look at parameters within the sandbox, it becomes the effective equivalent of an uncontrollable factor. Just like certain papers in the domains of psychology or medicine – the results can’t be reproduced. The only difference is, in this instance the uncertainty is added in artificially.
Science v Business
I’ll end with a personal story. When the second wave of COVID-19 hit India the hardest in Summer 2021, we faced a dire lack of hospital beds. People died because it wasn’t possible to get oxygen to them in time. Some hospitals did have available beds, however, there wasn’t a system in place that displayed a master list of available hospital beds, so at the very least - we could optimize the limited resources we did have. Several endeavors were launched across the country, with a huge number of lists being scraped off the internet, and then teams splitting up the numbers and making calls requesting the number of beds available. This list was then shared via groups, both internal and external, so anyone in need could refer to them in hopes of finding a bed.
Where am I going with this? Bear with me for just a bit longer.
I figured Google Duplex – the revolutionary system that can autonomously make phone calls – would be a perfect solution to this crisis. If we could configure it to make calls to hospitals at specified intervals each day, and use Google’s immense credibility to create a dashboard – it would allow for millions of hospitals to have valid, updated counts of their beds and just as importantly, everyone with internet access will have immediate access to that data.
Having reached out to the Duplex team, I was able to have a back-and-forth about such an integration – sharing the data I was able to accumulate – unfortunately, it never ended up materializing since I got no response after I shared the data I gathered.
What’s my takeaway from all this? Goodwill is largely televised into existence. Had the code for this been open sourced, it would have been possible to crowdsource funds to ensure the compute requirements of the networks were met, and many lives could have been saved.
Companies instead choose to have their cake and eat it too: using research conferences as a vector for advertisement, without providing the code or data necessary to validate a given approach. It’s turning the conference de-facto from a sandbox into a showcase.
However, unlike the binary blob examples like YOLOv7 or Asm2Vec, these recent ventures are possibly even worse - instead of providing a black-box binary that users may tinker around with, they operate entirely as-a-Service. You give them a balloon, they turn around, turn it back into the shape of a funny animal and hand it back to you. You may be impressed, but ultimately we aren’t learning much of anything.
Either publish the paper and code and treat it like research or build PR and use it as a project. Doing both is holding both ends of the stick and as a community, we shouldn’t accept it.
So: what now?
I’m not entirely sure what’s the optimal way to proceed from here. I think step 0 would be open-sourcing code, at worst with a time-based delay – similar to the patent system – that way, companies may capitalize on developing technologies while not completely handicapping the community at large.
As for nuances within papers designed to be reproduced, I’ll daisy chain onto a different blog: discussing the machine learning reproducibility scale - quantifying reproducibility is a great way to go; especially if metrics on reproducibility are highlighted at conferences - allowing researchers to litmus-test work before diving into them. For a more exhaustive understanding of the reproducibility crisis, there’s also an upcoming workshop by researchers at Princeton, that aims to tackle exactly that.
I also plan on conducting a meta-review on the Fall 2021 Reproducibility Challenge, to see if understanding the reasons behind reproductions attempts – both failed and successful – can be beneficial in more concretely pinpointing ways to improve information distribution within this awesome domain. The draft paper written by the workshop organizers at Princeton identified data leakage as the pervasive cause of reproducibility failures, and I’m curious to see if an independent investigation turns up a similar result. If this is something you think you’d be interested in, do stay tuned! 🙂
Acknowledgements
I'd like to thank (arranged alphabetically) Arjun Vikram, Dean Pleban, Nir Barazida & Yono Mittlefehldt for all their contructive reviews, feedback and input throughout the entire writing process; thank you for helping me express my ideas in the very best way possible!



