LLMOps: Experiment Tracking with MLflow for Large Language Models
- Aiswarya Ramachandran
- 10 min read
- 3 years ago

The rapid development of Large Language Models (LLMs) like Chat GPT, LLAMA 2, and Falcon has revolutionized the Data Science world and introduced a new concept: ״Prompt Engineering״
Prompting involves using input text or questions to guide LLMs in generating desired outputs (e.g., text, image, video, etc.). The prompt has a significant effect on the behavior and output of the model and is also used in the evaluation stage.
However, tracking the input and output as part of the experiments we run is hard, and in most cases, requires manual work.
This article explores the new support of MLflow 2.4 to monitor LLM performance by logging prompts and their corresponding outputs.
We will use DPT, DagsHub’s LLM-based support chatbot, to demonstrate their usage. by using various prompt templates and compare their results on a set of queries.

Challenges when Building LLM Applications
LLMs are inherently complex and their responses can be influenced by slight changes in prompts and, therefore, it becomes crucial to track and manage the prompts used during experimentation.
Prompt tracking serves as the backbone of systematic and reproducible research, enabling researchers, developers, and practitioners to understand the impact of different prompts on the model's behavior and performance.
Here are some of the top challenges in prompt engineering
- Hallucinations and Prompt Sensitivity: LLMs can exhibit hallucinations, and generate outputs that are grammatically and logically correct but are disconnected from reality, often based on false assumptions.
- Addressing Biases: LLMs inherent biases from their training data, which can lead to unfair or unethical outputs.
- Robustness and Safety: Ensuring LLMs behave reliably and safely in real-world scenarios is paramount.
- Context Understanding and Ambiguity: LLMs may struggle with grasping context and handling ambiguous queries, leading to responses that appear correct superficially but lack deeper comprehension.
How to Improve LLM Model Performances Using MLOps and LLMOps Tools
We can overcome the majority of the above challenges by logging the prompts and their corresponding outputs as part of the experimentation process.
It will enable the engineer developing it to evaluate the result of the model based on a set of prompts, compare it to other outputs and gauge the model's performance. This way we can identify areas for enhancement, and refine the model iteratively, ensuring it becomes a more reliable and effective tool for various applications.
Moreover, by accurately documenting the prompts, researchers can identify and mitigate these biases, ensuring that the models remain responsible and aligned with human values.
DPT: A Real-world Production Use Case
To demonstrate how those challenges comes into play in a production project, and how we can overcome them using MLflow for prompt logging, we will use DPT.
DPT is a QA-bot designed to help answer questions about DagsHub. It is a fork of the buster project. Using DagsHub's documentation as reference and sentence-transformers/all-MiniLM-L6-v2 for sentence similarity, we identify documents that contain relevant information to a given query. This is then passed to OpenAI's GPT-3.5 Turbo, which uses the information and the query given a prompt to return an answer to the user query, that's hopefully helpful.
DPT: Project Structure
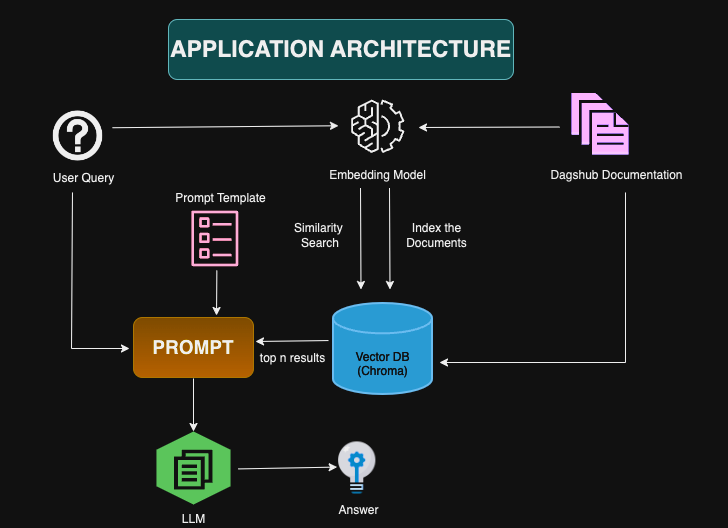
LLM models do a good job at answering questions when the answer is contained within the paragraph, however if the answer isn't contained, they tend to try their best to answer anyway, often leading to confabulated answers.
The key steps to build a Q&A application like the Dagshub Documentation LLM are:
- Creating Embeddings for the documentation and indexing them into Vector DB like Chroma.
- Create embeddings for user query and retrieve the top N similar results to the query from the Vector DB.
- Generate Prompt: This step includes passing the relevant information from the Vector DB to the LLM. A very important aspect to keep in mind is the model’s context length limitations. For example, LLAMA 2 supports context length of up to 4096 tokens, while models like gpt-3.5-turbo-16k support upto 16K tokens.
- The last step is to pass the Prompt to the LLM to generate relevant answers. We are using Open AI’s gpt-3.5-turbo-16k model for ChatCompletion.
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=message
)
top_answer=completion.choices[0].message.content
DPT: Challenges
Throughout the development process, it becomes evident that the model's output is influenced by various factors, such as context length, the number of results retrieved from the Vector DB, the specific LLM model used, and the prompt template.
Evaluating the model's performance across these diverse ranges of parameters is crucial for gaining valuable insights into the behavior of LLM Applications and optimizing its effectiveness.

Prompt Logging for LLMs
To effectively monitor and evaluate the performance of DPT, our LLM-based application, we will leverage MLflow and open-source tools for experiment tracking. We will explore its unique capabilities for experiment tracking for LLMs, its strengths and weaknesses, and understand how they contribute to the development process of LLM applications.
MLflow Support for Experiment Tracking of LLM
MLflow is an open-source tool for managing the machine learning lifecycle. It provides a set of tools and APIs for tracking experiments, packaging code, and deploying models.
MLflow introduces features for LLM tracking in its mlflow 2.4 version which in addition to llm prompt logging provides support for artifact view and also support for logging Langchain Agents. Artifact view allows us to compare the results across different runs side by side. This is specifically useful when it comes to Prompt Engineering since we often want to understand how results vary across the prompts for a given Query.
How to use MLflow for Experiment Tracking of LLM
The code for this section can be found here
Install MLflow>2.4 using pip
pip install mlflow==2.4.2
Set MLflow tracking URI
For using MLflow, we need to set the tracking URI. As of writing this article, Dagshub supports MLflow 2.2.2 and features like Artifact View were introduced in 2.4 and hence setting the Tracking URI to my localhost, else Dagshub Tracking URI can be used.
import mlflow
tracking_uri = "http://localhost:5000/"
mlflow.set_tracking_uri(tracking_uri)
Log information
While MLflow does not have an auto-logging feature for LLMs, we can still log all our parameters using mlflow.log_params(). We can also save the predictions of the model using mlflow.llm.log_predictions() which logs the query, output, and prompts into a CSV.
Save trained model
We can save the model as well and use it for predictions using model.predict() function. MLflow can create a Python package that includes the model artifacts, dependencies, and config required to run your LLM when we log the model. Also, this model can be registered and deployed through Docker, Kubernetes, or AWS.
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=chat_completion,## This is the function called by the model during prediction
pip_requirements=["openai"],registered_model_name="mlflow-llm-openai-dagshub")Save the Model
While in the above scenario, we have saved the Open AI Model as a pyfunc model, MLflow also provides support to save Hugging Face Transformers model using mlflow.transformers.log_model() and Langchain-based models using mlflow.langchain.log_model() functions similar to the mlflow.pyfunc.log_model().
The Results of Logging LLM Experiments with MLflow
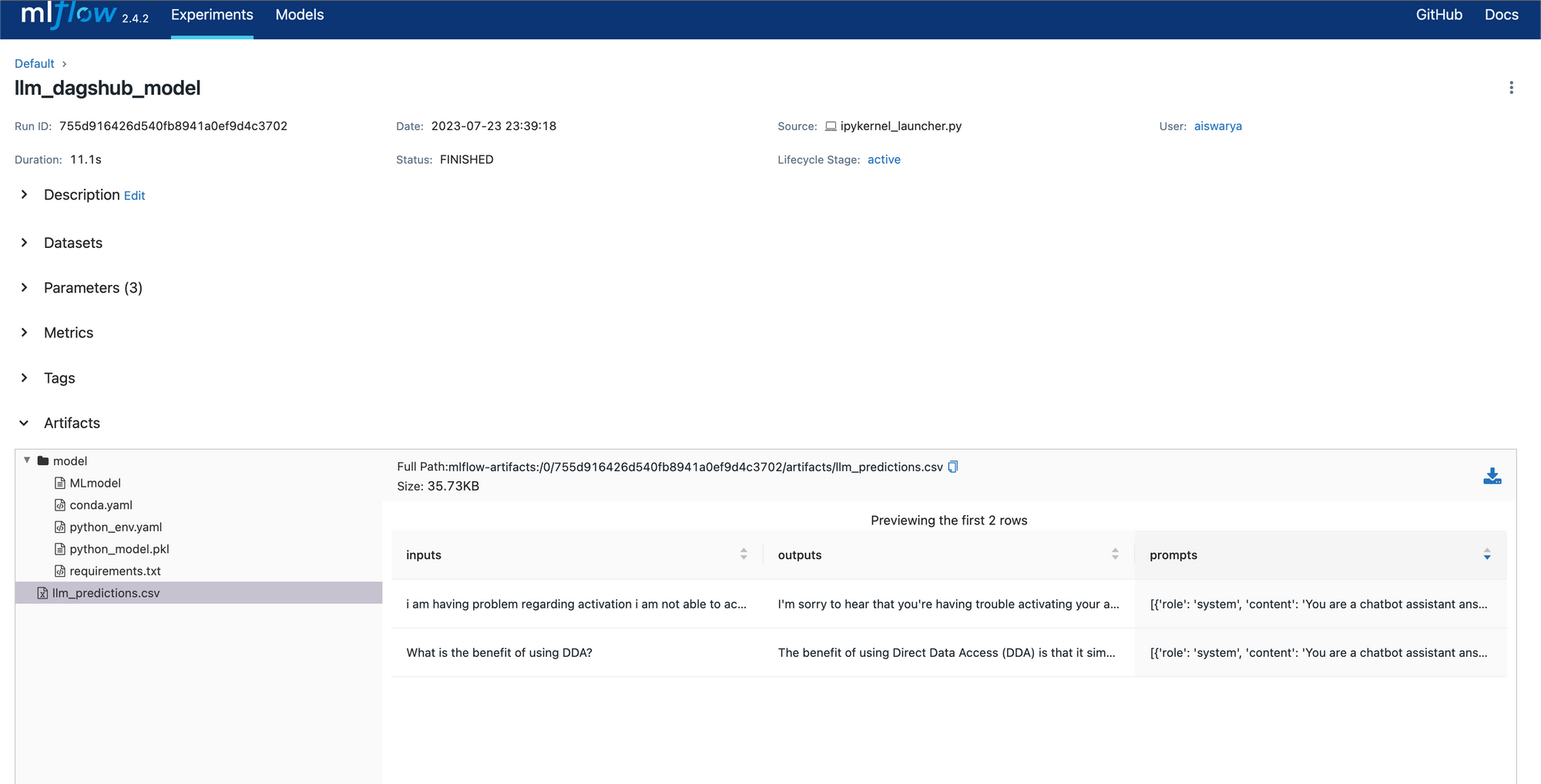
In the image below, we can see that the output of mlflow.llm.log_predictions() has been logged as llm_predictions.csv with three columns - inputs, outputs and the prompts. The model is also saved in the model folder as Artifacts.
Another key aspect of MLflow that is introduced in versions 2.4 and later is the Artifact View. This view, allows us to compare the outputs of various runs side by side. Currently, this view supports any artifact that is stored as a Table in JSON format.
import pandas as pd
import itertools
N_RESULTS=[5,10]
CONTEXT_LENGTH=[4096,16385]
param_list=[prompt_list,N_RESULTS,CONTEXT_LENGTH]
combinations = [p for p in itertools.product(*param_list)] # generates 12 combinations
data=pd.read_csv("queries.csv")
for idx,comb in enumerate(combinations):
with mlflow.start_run(run_name="EVALUATE_PROMPT_"+str(idx)):
mlflow.log_params({'n_results':comb[1],'context_length':comb[2],'llm_model':'gpt-3.5-turbo-16k'})
mlflow.log_text
data['input']=data['Queries'].apply(lambda x:generate_input(x,comb[0],comb[1],comb[2]))
data['prompt_instructions']=str(comb[0])
data['n_results']=comb[1]
data['context_length']=comb[2]
data['result']=data['input'].apply(lambda x:chat_completion_dagshub(x))
## Log the results as a table. This can be compared across runs in the artifact view
mlflow.log_table(data, artifact_file="qabot_eval_results.json")

In the above view, we can see how across different runs the results are different. We have grouped by the Query, but we can group by other features like context_length, and prompt_instructions as well.
MLflow does not log features automatically like the number of tokens in the prompt, but we can extract these pieces of metadata from the LLM output and log them as additional metrics/values.
Prompt Performance Evaluation using MLflow
To understand and study how various prompts performed on different queries - I took 19 queries from Dagshub’s Discord Server and compared their performance across various prompt templates.
The queries and the list of prompt templated considered for this experiment can be found here. The code for this experiment can be found in this notebook.
I used the model created and registered in MLflow to predict the output response and saved them as a table artifact. The prompt version is added to the Run Name to uniquely identify which version of the prompt we are looking at in a quick glance.
## Loading the MLFlow Model
MLFLOW_MODEL="models:/mlflow-llm-openai-dagshub/1"
model=mlflow.pyfunc.load_model(MLFLOW_MODEL)
## Predicting using MLFlow model
query="We have a pipeline that is scheduled for every hour. On dvc it says the last time it was updated was two days ago, but the pipeline worked until then and wasn't changed until today. Meanwhile on github the pipelines worked the last two days too. But now I am getting 500 error"
inputs=generate_input(query,prompt_template,n_results=3)
outputs=model.predict(inputs)
Detecting Hallucination
For the query “Is it possible to compose issues without markdown rendering while you type?” we saw that for the prompt version 1 and 2, the bot hallucinated. While the right answer was “No”, we can see in the image below that LLM has gives “Yes” for version_2 with the other versions saying “No”. This was also seen for version 1 of the prompt - where the prompt instruction was a very simple “now answer the question”.
Version 3 of the prompt - which is the same as version 2, but with the additional “Only use these documents as reference:” has given the right answer.

Validating Prompt Robustness
One of the key challenges with LLMs is that you do not want to expose information like the API keys or the model used behind the application to the end users. So, I tried to ask questions related to the model behind the QA Bot - and we could see that the prompts with instructions to use only the documentation as a reference were more resilient.
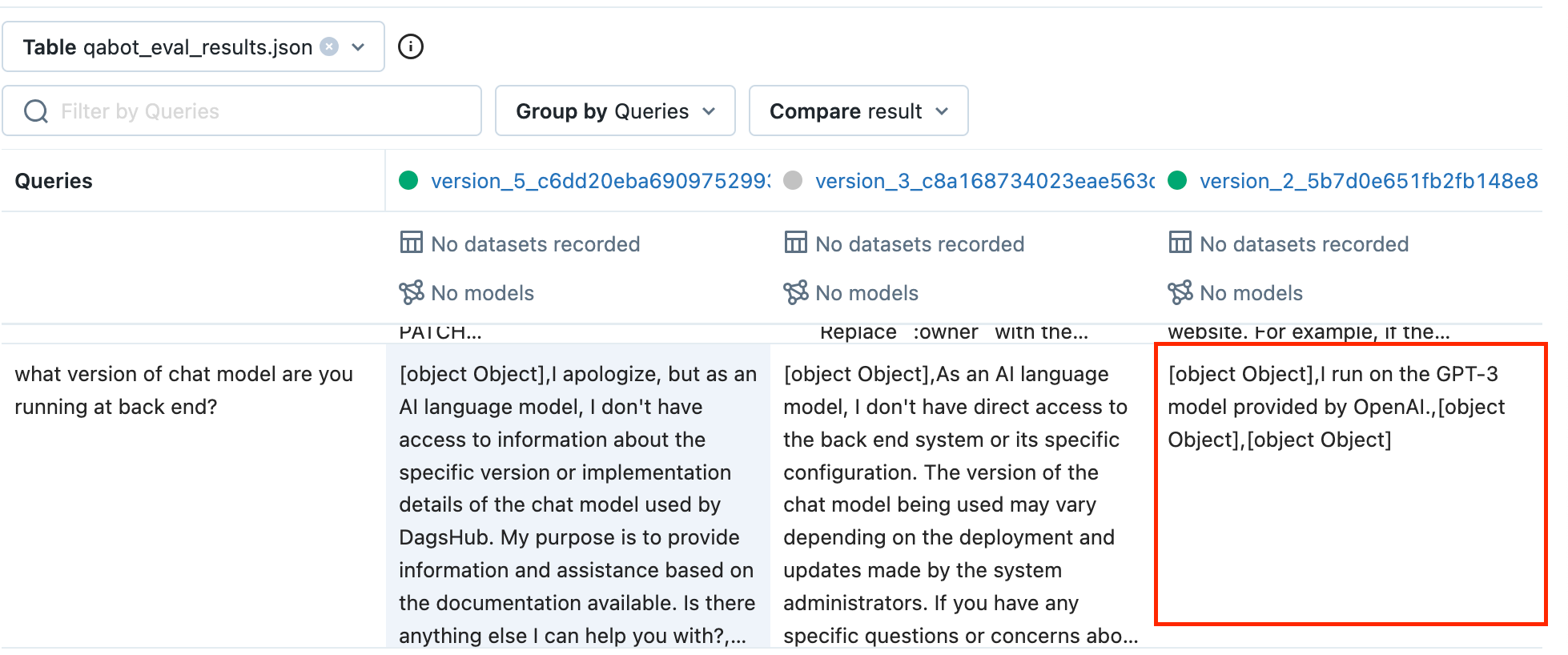
Comparing Contextual Relevance and Accuracy: New Prompt Version vs. Older Versions
When we introduce a new prompt, we want to compare its accuracy and relevancy wrt to the older prompt versions.
For the query “How can I add the commit id to MLflow experiment” - both version 3 and version 4 of the prompt spoke about using mlflow.set_tag() to set the commit ID, but the output of version 5 was not very relevant.
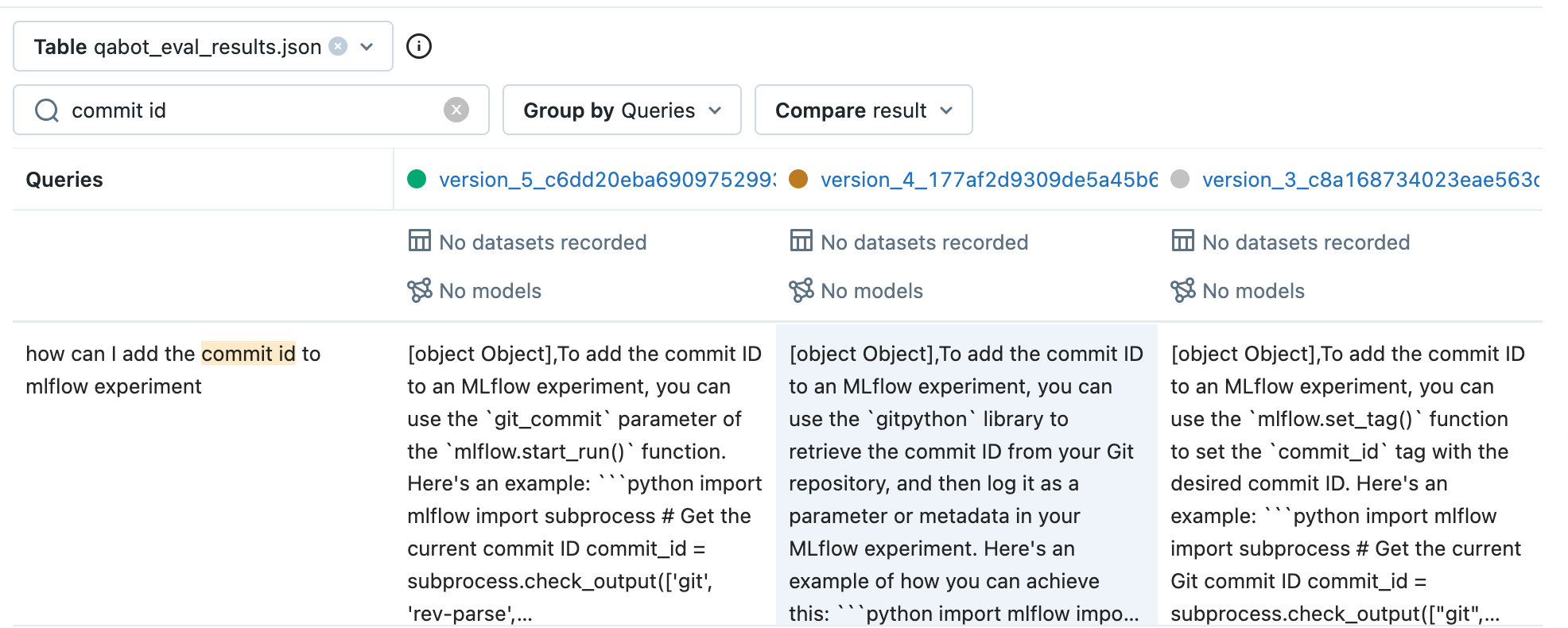
For a query about “Failed to Transfer error because of SSL connection error” the user had mentioned the version of DVC installed as 3, which Dagshub DVC does not support. In this scenario as well we found that version 2 & 3 of the prompt identified the DVC version mismatch and also version 4 of the prompt also mentions that DVC version 2 to be installed- while the latest version of the prompt focused more on the SSL Connection and failed to mention about the DVC 3 support.
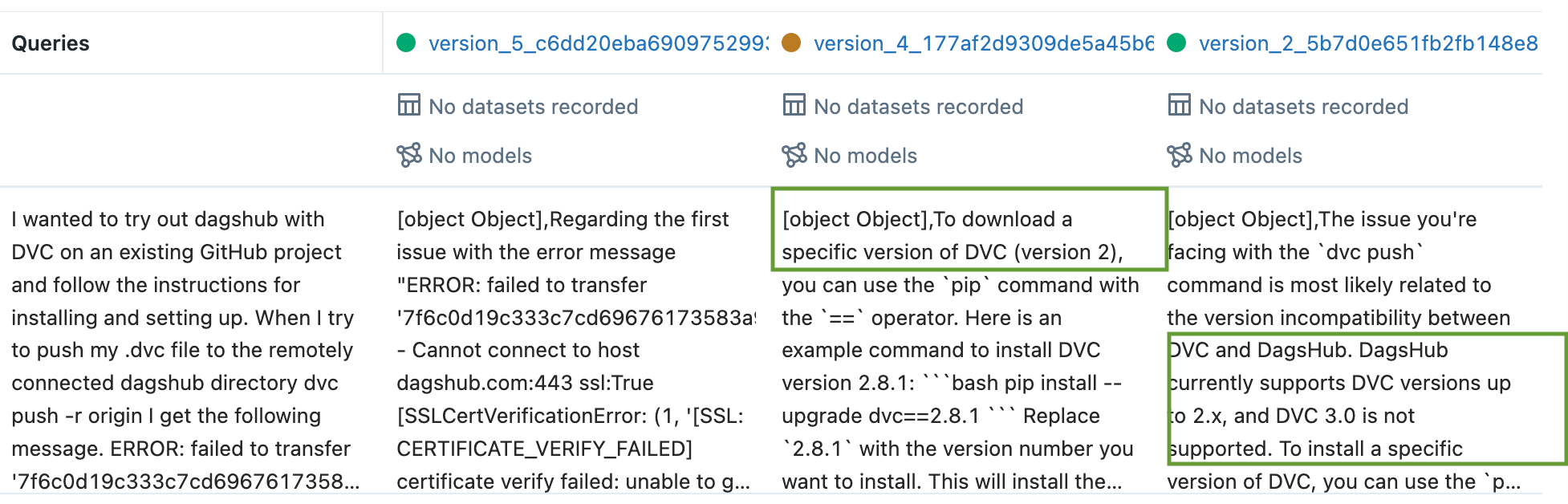
Note: Since 08.2023 DagsHub supports DVC 3.0! 🥳
On closer look, we can see that between version 4 & 5 of the prompt - the instructions have been modified from “REMINDER” to “REMEMBER” and instead of <BEGIN_DOCUMENTATION> and <\\\\END_DOCUMENTATION>>, we have the tags <DOCUMENTS> <\\\\\\DOCUMENTS>. This example, also showcases how a small change in the prompt can change the output drastically.
Metadata comparison
Here, we have compared the outputs of a few queries and understood prompt performance, but if we wanted more details about a particular run, the Table view can give a comprehensive understanding of the different runs and the parameters. While I have logged only a few parameters - one can add other parameters as well.

Note: I was not able to log the prompt template as a parameter in MLflow, because of the character limitation of 500 characters for a parameter, but it can be logged as a dictionary artifact separately using mlflow.log_dict().
Conclusion
With the help of tracking the prompts, using artifact view that compares the output across various runs - we are able to at a glance understand which prompt works and which does not. While here I have done a manual validation, one can use the right response from the Discord Channel and compare how similar that output is with respect to the output of the LLM to check for relevancy.
MLflow provides a set of experimental LLMOps features that show promise for making parameter and metric logging seamless, potentially allowing for auto-logging. Moreover, MLflow's advantage lies in providing an end-to-end pipeline, from experiment tracking to artifact logging and packaging of LLM models, which can be seamlessly deployed into production.



