How to Train a Custom LLM Embedding Model
- Nilesh Barla
- 12 min read
- 2 years ago
I am a founder at Perceptron AI. Our areas of focus are productivity, medicine, and materials science. I like spending time on training, tuning, and embedding LM. | Deep Learning Engineer

Introduction
Large language models (LLMs) such as GPT-3.5 and others like Gemini, Claude, and Mistral have paved in our regular everyday lives augmenting our productivity and enhancing our cognitive abilities. These models empower us to enhance creativity, reasoning, and understanding across various domains, enabling tasks such as summarizing text, analyzing documents, generating code, and crafting contextually relevant responses. But how do they do it?
Well, the ability of LLMs to produce high-level output lies in their embeddings. Embeddings are capable of condensing a huge volume of textual data that encapsulates both semantic and syntactic meanings. Their ability to store rich representations of textual information allows LLM to produce high-level contextual outputs.
Here is a general workflow of how embeddings are utilized:
- The input query is tokenized and are fed into the embedding model.
- The embedding model then maps the given input to its nearest corresponding embeddings. These corresponding embeddings contain in-context information.
- The in-context information is then fed into the LLM enhancing the contextual understanding allowing it to generate relevant information.
Whether you are considering building an LLM from scratch or fine-tuning a pre-trained LLM, you need to train or fine-tune an embedding model. As obvious as it is, training an embedding model will require a lot of data, computing power, and time as well. Additionally, you might as well have to fine-tune it to make it much more attuned to your desired task.
Whereas, when you are “only” fine-tuning the embedding model you will save a lot of time and computational resources. It allows us to adjust task-specific parameters and enables us to preserve pre-trained knowledge while improving performance on targeted tasks and reducing overfitting. Its flexibility also allows for easy adaptation to diverse applications, making it cost-effective and suitable for scenarios with evolving datasets or requirements. Essentially, fine-tuning balances efficiency, performance, and adaptability in model development and deployment.
In this article, we will learn:
- The concept of embeddings and its significance.
- Fine-tuning as a strategy to improve embedding models.
- A detailed study of the fine-tuning process with open-source model from Huggingface and LLama-Index using PyTorch. We will be using GIST-large-Embedding-v0 from Aivin Solatorio that we will fine-tune on synthetic data generated by LLM called “zephyr-7b-beta” which is a fine-tuned version of the Mistral-7B-v0.1.
So, let’s get started!
Overview of Embeddings
Embeddings are a numerical representation of words that capture the semantic and syntactic meanings. In natural language processing (NLP), embedding plays an important role in many tasks such as sentiment analysis, classification, text generation, machine translation, etc. Embeddings are represented in a high-dimensional vectors, a long sequence of continuous values, often called an embedding space.
These vectors capture semantic meaning and encode similar words closer to each other in the embedding space. In much simpler words they act like a dictionary or a lookup table for storing information.
For instance, words like “tea”, “coffee” and “cookie” will be represented close together compared to “tea” and “car”. This approach of representing textual knowledge leads to capturing better semantic and syntactic meanings.
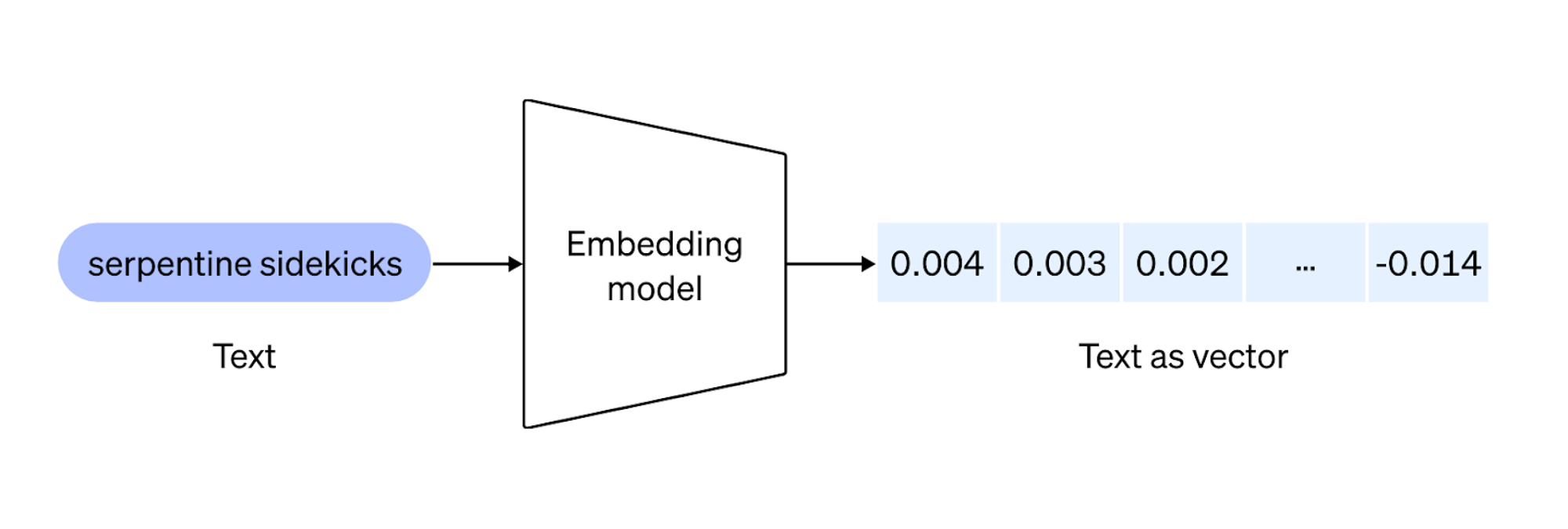
Embeddings are higher dimensional vectors that can capture complex relationships and offer richer representations of the data. But they generally require large dataset for training which leads to more computing resources. Additionally, it increases the risk of overfitting.
As such there are different types of embeddings, some of which are:
- Document embeddings are used to capture semantic and contextual patterns within a document. It often uses approaches like averaging word embeddings and models like Doc2Vec.
- Word embeddings are low-dimensional but dense vectors that project words in a continuous vector space. It is useful in capturing semantic and syntactic relationships.
- Conceptual embeddings are vector representations of concepts or entities in a semantic space, capturing their relationships and attributes, often learned from large-scale knowledge graphs or ontologies.
- Contextual embeddings are dynamic word representations generated by models like BERT and GPT, which consider the surrounding context of each word in a sentence to produce embeddings that are sensitive to the context in which the word appears.
Understanding Embedding Models
Embedding models are generally neural network algorithms that generate embeddings when an input is provided. Here are the general steps that will help you to understand how embedding models work:
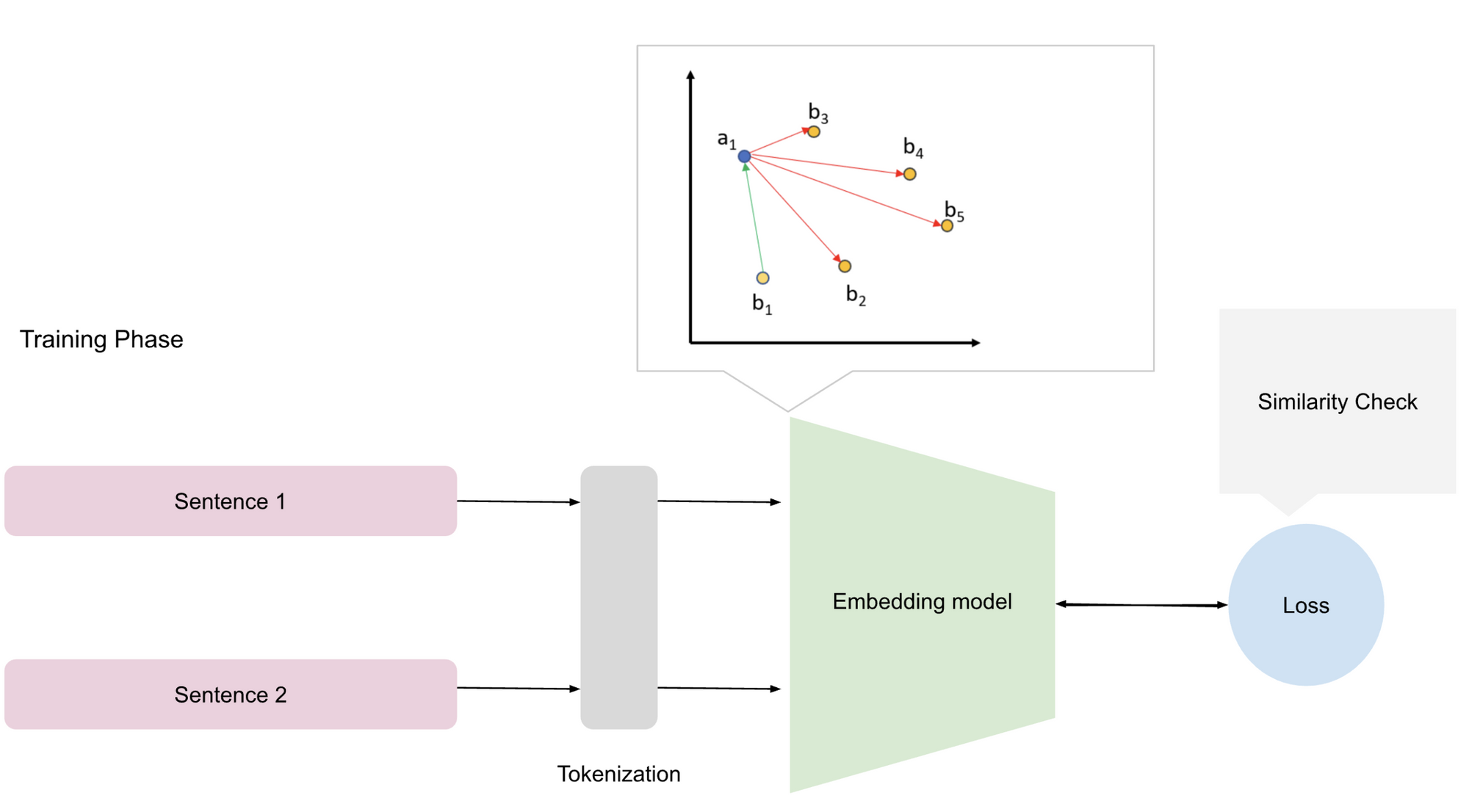
- Tokenization divides the input data into smaller units, such as words or subwords, to facilitate processing and create vocabulary i.e., mapping the tokens to unique integer indices for the model to refer to during training and inference.
- Embedding Initialization initializes a matrix where each row corresponds to the embedding vector for a token in the vocabulary.
- Training or fine-tuning phase involves adjusting the parameters of the model to minimize the distance between similar words and maximize the distance between dissimilar words. Here semantic relationships are learned as the model observes how words co-occur in sentences, enabling it to encode meaningful associations between tokens.
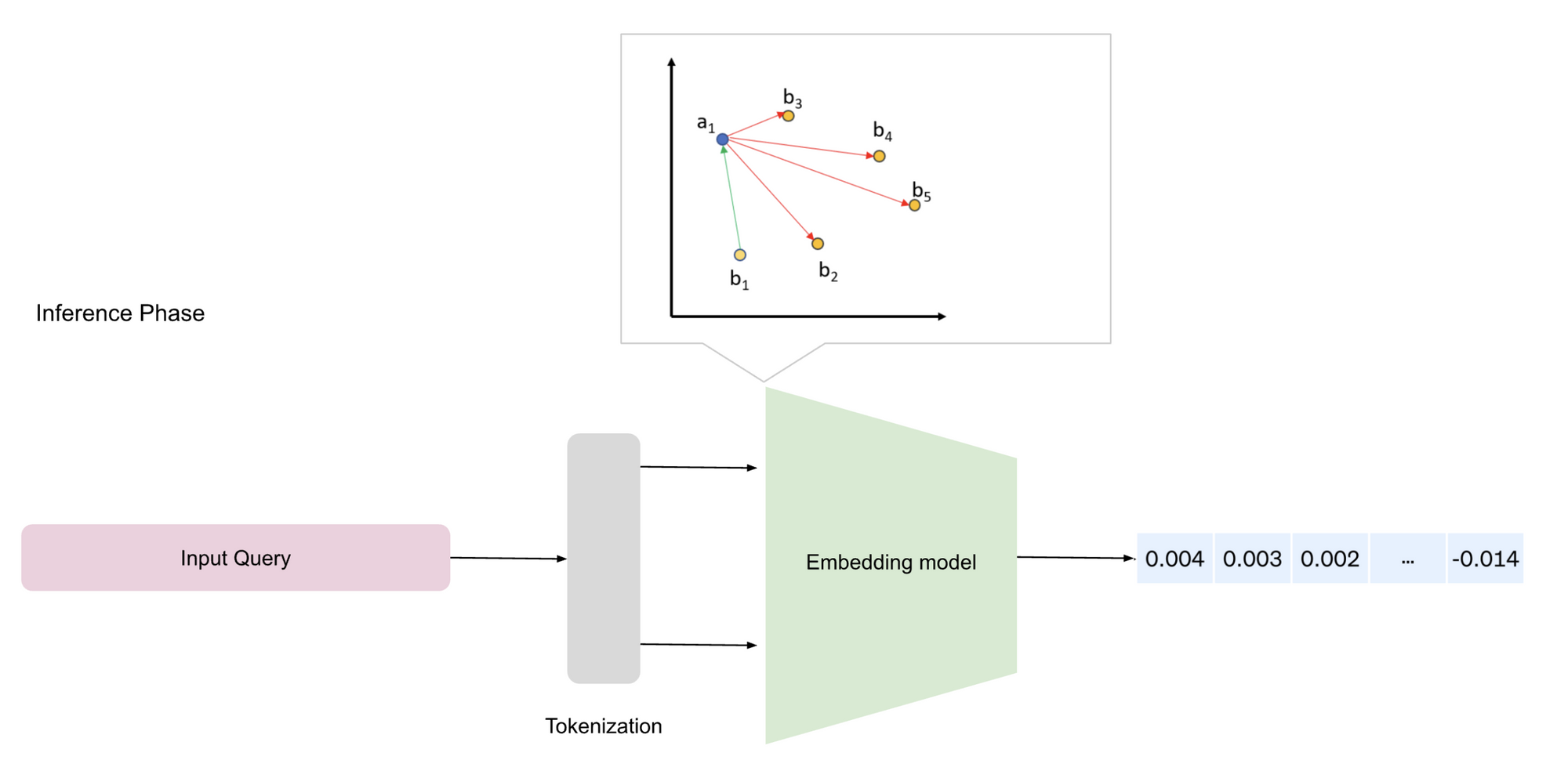
During the inference phase, the input received by the model retrieves the learned embedding vectors corresponding to input tokens, providing numerical representations that capture semantic information for downstream tasks.
The utility of embeddings in various NLP tasks
Embeddings can be used for various tasks such as:
- Text classification: It involves classifying textual data based on their context.
- Sentiment analysis: It is used to analyze sentiments such as emotional tone within a given text.
- Text summarization: It processes the given text and condenses it into a more concise text. Additionally, text summarization aims to retain maximum information from the given text while facilitating efficient comprehension.
- Text generation: It involves predicting contextual text to be indistinguishable from human-written text.
- Machine translation: It refers to translating text from one language to another.
- Question-answering: It involves generating relevant answers to user queries based on input text.
- Information retrieval: It involves retrieving relevant documents or information from a large collection based on user queries.

Improving Embeddings
Pre-trained embedding models can offer well-trained embeddings which are trained on a large corpus. While these models can provide great generalization across various domains they might not be so good for domain-specific tasks. To address that we need to improve the embeddings to make them much more adaptable to the domain-specific tasks. To achieve that we will use a technique called fine-tuning.
Fine-tuning is a process to train a pre-trained model on a domain-specific data. This process adjust the parameters of the pre-trained model and enables them to gain specialization in specific area. Fine-tuning makes the model more accurate and reliable as well.
The Fine-tuning Process for Document Embeddings
Fine-tuning is one of the most used approaches to enhance the embeddings. In this section, we will learn how to fine-tune an embedding model for an LLM task. Specifically, we will be looking into how to fine-tune an embedding model for retrieving relevant data and queries.
We will have the following steps:
- Data preparation: Selecting a task specific document and downloading it.
- Generating synthetic data: Using an open-sourced LLM from HuggingFace framework to generate synthetic dataset.
- Fine-tuning an embedding model: Using the generated synthetic data we will train an embedding model.
All the codes for this section are available in this Google Colab notebook.
Dataset Preparation
Preparing the dataset is the first step for fine-tuning an embedding model. The dataset must be well must be well curated. In another sense, even if you download the data from any source you must engineer it well enough so that the model is able to process the data and yield valuable outputs.
Now, it is certain that most of the time this phase can be really tedious and time consuming and benchmarking an AI model on any random data is not well supported in practice as it might lead to biased results. So in this section we will explore a different approach based on synthetic data to engineer data for fine-tuning an embedding model.
Downloading the data
For the sake of this article we will download a paper from arxiv.org. The paper or the document will be in a PDF format.
!wget '<https://arxiv.org/pdf/2402.04177.pdf>' -O "Scaling_Laws_for_Downstream_Task_Performance_of_Large_Language_Models.pdf"
!wget '<https://arxiv.org/pdf/2403.06563.pdf>' -O "Unraveling_the_Mystery_of_Scaling_Laws.pdf"
Generating Synthetic Data
Generating synthetic data is an established practice in fine-tuning embedding models because synthetic data offers various advantages over real-world data. Synthetic data refers to data generated via models or simulated environments — in our case it will be an LLM. It provides a faster and cheaper alternative to human annotated data It often exhibits higher quality and diversity, leading to improved model performance and generalization when used for fine-tuning. Additionally, synthetic data helps sidestep privacy and copyright concerns associated with real data, making it a valuable resource for training and enhancing models.
The first step to generating synthetic data is to create training nodes on the downloaded PDF file. Training nodes are essentially text chunks that represent segments of source documents. The process involves dividing each document's text into sentences, where each sentence is treated as a node. These nodes contain metadata that captures the neighbouring sentences, with references to preceding and succeeding sentences.
def load_corpus(files):
reader = SimpleDirectoryReader(input_files=files)
docs = reader.load_data()
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(docs, show_progress=True)
print(f"Parsed {len(nodes)} nodes")
return nodes
train_nodes = load_corpus(TRAIN_FILES)
Once the training nodes are created we will use an LLM to generate question and answer pair. The training nodes will be leveraged for contextual understanding. In this example, we will be using two pdf files to generate synthetic data — one for training and the other one for validation. The training dataset contains 23 samples while the validation dataset contains 18 samples
Also, the LLM that we will be using is “zephyr-7b-beta” which is a fine-tuned version of the Mistral-7B-v0.1 LLM. The reason we will be using zephyr-7b-beta as LLM of choice because:
- It is open-sourced and freely available for experimentation and learning.
It is a fine-tuned version of Mistral-7B and also contains 7 billion parameters similar to Mistral-7B. And it has a good performance benchmark on text generation capabilities.
from llama_index.finetuning import generate_qa_embedding_pairs
def huggingface_llm(model_name="HuggingFaceH4/zephyr-7b-beta",
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
context_window=3900,
max_new_tokens=256,
quantization_config = quantization_conf
):
llm = HuggingFaceLLM(
model_name=model_name,
tokenizer_name=tokenizer_name,
query_wrapper_prompt=PromptTemplate("<|system|>\\n</s>\\n<|user|>\\n{query_str}</s>\\n<|assistant|>\\n"),
context_window=context_window,
max_new_tokens=max_new_tokens,
model_kwargs={"quantization_config": quantization_config},
# tokenizer_kwargs={},
generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},
messages_to_prompt=messages_to_prompt,
device_map="auto",
)
return llm
llm = huggingface_llm()
train_dataset = generate_qa_embedding_pairs(train_nodes, llm)
Now that the dataset is ready we can go to the next phase – fine-tuning.
Fine-tuning
Fine-tuning requires us to have a pre-trained embedding model. Now, there are a lot of pre-trained models available from the Huggingface open-source library. You can choose any model and fine-tune it. You can this link as a reference point to start fine-tuning.
For this example we will be using avsolatorio/GIST-large-Embedding-v0 from Aivin Solatorio. The model is trained on top of BAAI/bge-base-en-v1.5. The BAAI general embedding series includes the bge-base-en-v1.5 model, an English inference model fine-tuned with a more reasonable similarity distribution. Additionally, the GIST Large Embedding v0 model is fine-tuned on top of the BAAI/bge-large-en-v1.5 model leveraging the MEDI dataset. The model augmented with mined triplets from the MTEB Classification training datasets. This augmentation enables direct encoding of queries for retrieval tasks without crafting instructions. You can read the full paper here.
Also, you can choose any embedding models from this link.
from llama_index.finetuning import EmbeddingAdapterFinetuneEngine
from llama_index.core.embeddings import resolve_embed_model
def embedding_model(model="local:**avsolatorio/GIST-large-Embedding-v0**",
model_output_path="model_output_test",
bias=True,
no_of_epochs=4,
verbose=True,
optimizer=torch.optim.AdamW,
optimizer_params={"lr": 0.01}
):
embed_model = resolve_embed_model(model)
ft_pipeline = EmbeddingAdapterFinetuneEngine(
train_dataset,
embed_model,
model_output_path=model_output_path,
bias=bias,
epochs=no_of_epochs,
verbose=verbose,
optimizer_class=optimizer,
optimizer_params=optimizer_params
)
return ft_pipeline
ft_pipeline = embedding_model()
The code above defines a function embedding_model that sets up the fine-tuning process for an embedding model using EmbeddingAdapterFinetuneEngine. It is essentially an abstraction that takes parameters like the model to use, output path for the trained model, training epochs, optimizer settings, etc. The EmbeddingAdapterFinetuneEngine also enables a streamlined finetuning process which you can start by running the following the command:
ft_pipeline.finetune()
You can see the results below:

Evaluation
Now, that our model is fine-tuned on our desired dataset we can now evaluate our model on validation dataset. But before we must create the validation dataset. For that we will follow the same procedure as the training dataset.
val_nodes = load_corpus(VAL_FILES)
val_dataset = generate_qa_embedding_pairs(val_nodes, llm)
Once the dataset is created we can benchmark it with different embedding models such OpenAI embedding model,Mistral7b, et cetera.
#openai embedding model
ada = OpenAIEmbedding()
ada_val_results = evaluate(val_dataset, ada)
#pre-train GIST-large-Embedding-v0
gist_embed_model = "local:avsolatorio/GIST-large-Embedding-v0"
gist_val_results = evaluate(train_dataset, gist_embed_model)
#fine-tuned GIST-large-Embedding-v0
ft_gist_embed_model = finetune_engine.get_finetuned_model()
ft_gist_val_results = evaluate(train_dataset, ft_gist_embed_model)
To evaluate our fine-tuned model we will use the hit rate metric.
So, what is a hit rate metric?
The hit rate metric is a measure used to evaluate the performance of the model in retrieving relevant documents. It calculates the percentage of correct hits. Essentially a hit occurs when the retrieved documents contain the ground-truth context. This metric is crucial for assessing the effectiveness of the fine-tuned embedding model.
The hit rate metric helps to determine how well the model performs in retrieving documents that match the query, indicating its relevance and retrieval accuracy.
Results
Let’s see combined results of all the models.
| Model | Hit Rate | |
|---|---|---|
| 0 | ft_gist | 0.799873 |
| 1 | pre_trained_gist | 0.787342 |
| 2 | openai embed | 0.870886 |
As you can see that our fine-tuned model’s (ft_gist) hit rate it quite impressive even though it is trained on less data for epochs. Essentially, our fine-tuned model is now able to outperform the pre-trained model (pre_trained_gist) in retrieving relevant documents that match the query.
Our fine-tuned model outperforms the pre-trained model by approximately 1%. Although it is a small increase in the performance but it still establishes the idea and motivation behind fine-tuning i.e., fine-tuning reshapes or realigns the model’s parameter to the task specific data. It is worth mentioning that if the model is trained with more data with more epochs then the performance is likely to increase significantly.
This is the whole idea of fine-tuning in general. If you want a model that it aligned to your requirement and dataset, then you just need to grab a capable pre-trained model that can do so and fine-tune it.
Finding a capable pre-trained model is also a key for effective fine-tuning. A pre-trained model trained on a large corpus of dataset can definitely give you good results but enhancing it via fine-tuning on task-specific dataset will give better results.
Conclusion
To sum up, in this article we explored what embeddings are and what significance it carries in LLMs. We learned how embeddings can be used for various NLP tasks such as classification, text generation, machine translation, etc. Lastly how we can fine-tune a pre-trained language embedding model.
In a nutshell, embeddings are numerical representations that store semantic and syntactic information as vectors. These vectors can be high-dimensional, low-dimensional, dense, or sparse depending upon the application or task at hand. Embeddings can be obtained from different approaches such as PCA, SVD, BPE, etc. All of these approaches have a common goal i.e., to bring and group similar data points together in an embedding space.
Additionally, the embedding models can be fine-tuned to enhance the performance for a specific task. In this article, we saw how we can fine-tune a Transformer-based pre-trained model on the synthetic dataset generated using “zephyr-7b-beta” which is a fine-tuned version of the Mistral-7B-v0.1 LLM. Additionally, we evaluated the model’s performance based on the hit rate metrics on a new and unseen dataset.
Further reading
- Improving Text Embeddings with Large Language Models
- A Survey on Contextual Embeddings
- An intuitive introduction to text embeddings
- The Ultimate Guide to Word Embeddings
- Train and Fine-Tune Sentence Transformers Models
- Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation
- Next-Gen Sentence Embeddings with Multiple Negatives Ranking Loss
- Distilled AI
- How to Generate and Use Synthetic Data for Finetuning
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- Finetuning an Adapter on Top of any Black-Box Embedding Model
- https://github.com/run-llama/llama_index/issues/9277#issuecomment-1837545398




{kind=link}