Hacktoberfest 22': Contributing 26 Open-Source ML Projects and Datasets
- Megan Sternecker
- 9 min read
- 4 years ago

October, and Digital Ocean, gave us a great opportunity to launch yet another DagsHub’s Hacktoberfest challenge - and boy, that was a wild ride! As always, the DagsHub community rose to the occasion contributing: 11 reproducible ML research papers, 10 3D datasets, and 5 new audio datasets! What is even more amazing to consider is that all of these contributions were done using open-source tools and are completely open-source on DagsHub!
We’d like to also extend a huge THANK YOU to Digital Ocean, Github, and Gitlab for organizing the event.
Feel inspired by one or more of these contributions? You can now stream all of the Hacktoberfest Datasets with DagsHub Direct Data Access! DDA lets you stream your data from, and upload it to any DagsHub project - as in the projects below! With just a few lines of code, their projects become yours!
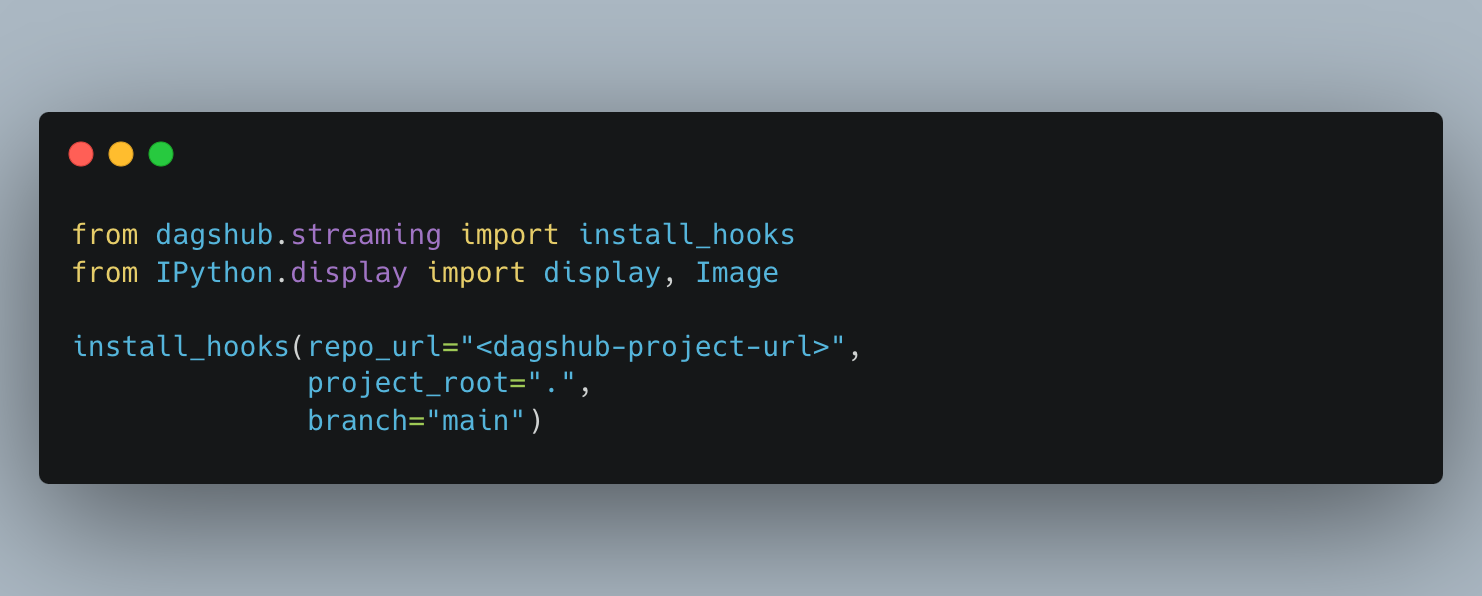
We have provided the links to each DagsHub repo under each submission, so you can easily copy the link into the install_hooks code! All you need to do is replace the <repo_url> with the repo url from the selected contribution.
Challenge 1: Papers with Code
In this challenge, participants will connect repos from GitHub to DagsHub that host reproduced papers from NeurIPS, ICML, ICLR, ACL, EMNLP, CVPR, and ECCV, and upload their datasets and model's weights to DagsHub Storage to make them accessible and reproducible for the community. You can find all the contributions and other reproduced papers here.
DeepFlux for Skeletons in the Wild
Computing object skeletons in real photos is difficult due to wide variations in object look and scale, as well as the complexities of dealing with background clutter. In the spirit of flux-based skeletonization algorithms, we break from this technique by training a CNN to predict a two-dimensional vector field that maps each scene point to a candidate skeleton pixel.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
Vehicle and License Plate Recognition with Novel Dataset for Toll Collection
Tolling efficiency is low and time consuming in manual toll collection systems, resulting in delayed traffic and large lines of cars. This, too, necessitates human effort and resources.Using the already existing cameras for surveillance, we automate the toll collection process by detecting vehicle type and license plate from camera images. We assemble a Novel Vehicle Type and License Plate Recognition Dataset called Diverse Vehicle and License Plates Dataset (DVLPD), which contains 10,000 photos. We describe a three-step automated toll collecting process: vehicle type recognition, license plate detection, and character recognition. We train many cutting-edge object detection models such as YOLO V2, YOLO V3, YOLO V4, and Faster RCNN.
- Contributed by: Arnav Raina
- DagsHub project
- Original paper
EGNet: Edge Guidance Network for Salient Object Detection
Fully convolutional neural networks (FCNs) have demonstrated their superiority in the job of detecting salient objects. However, the majority of existing FCNs-based approaches still have coarse object bounds. To tackle this challenge, the paper focuses on the complementarity between salient edge information and salient object information in this study. As a result, it offers an edge guidance network (EGNet) for salient object recognition that uses three phases to model these two types of complementing information in a single network.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
You Only Look Once: Unified, Real-Time Object Detection
YOLO is a novel way to object detection. Previous work on object detection repurposes classifiers to detect objects. We frame object detection instead as a regression issue to spatially separated bounding boxes and associated class probabilities. In a single assessment, a single neural network predicts bounding boxes and class probabilities directly from entire images. Because the entire detection pipeline is a single network, detection performance can be optimized end-to-end. Note: For ease of implementation, project is not implemented exactly the same as paper.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
One-shot Face Reenactment
Existing face reenactment approaches rely on a set of target faces for learning subject-specific attributes to enable realistic form (e.g., stance and expression) transfer. However, in the actual world, end-users frequently only have one target face at their disposal, rendering existing solutions inapplicable. This paper introduces a revolutionary one-shot face reenactment learning approach.
- Contributed by: Bharat Bansal
- DagsHub Project
- Original paper
A Light CNN for Deep Face Representation with Noisy Labels
To better suit vast amounts of training data, the volume of convolutional neural network (CNN) models proposed for face recognition has been steadily increasing. Labels are likely to be vague and erroneous when training data is collected from the internet. This paper describes a Light CNN architecture for learning a compact embedding from large-scale face data with massively noisy labels.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
View-GCN: View-based Graph Convolutional Network for 3D Shape Analysis
Through its projected 2D images, view-based technique for 3D form recognition images have reached cutting-edge 3D shape recognition results. The main difficulty with this technique is determining how to aggregate multi-view characteristics into a global shape descriptor. This research offers a unique view-based Graph Convolutional Neural Network, nicknamed view-GCN, for 3D shape recognition.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
Several recent studies have demonstrated how to train convolutional neural networks to generate remarkably realistic human head images. These efforts necessitate training on a big collection of photos of a single person in order to construct a personalized talking head model. This paper presents a system with such few-shot capability.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
This paper proposes a new generative model, Periodic Implicit Generative Adversarial Networks (-GAN or pi-GAN), for high-quality 3D-aware image generation. π-GAN leverages neural representations with periodic activation functions and volumetric\srendering to represent scenes as view-consistent radiance\sfields. The suggested method yields cutting-edge results for 3D-aware image generation with numerous real and synthetic datasets.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
Neural Rays for Occlusion-aware Image-based Rendering
The paper introduces a new neural representation for the innovative view synthesis challenge termed Neural Ray (NeuRay). A 3D point may be invisible to some input views due to occlusions. These generalization approaches will contain inconsistent picture features from invisible views on such a 3D point, which will conflict with the radiance field development. To address this issue, we use our NeuRay model to anticipate the visibility of 3D points to input views. Because of this visibility, the radiance field creation can concentrate on visible image features, considerably improving rendering quality.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
End-to-End Optimization of Scene Layout
The paper presents an end-to-end variational generative model based on scene graphs for scene layout generation. In contrast to unconditional scenario layout generation, we employ scene graphs as an abstract yet universal representation to guide the synthesis of varied scene layouts that satisfy the scene graph's relationships.
- Contributed by: Bharat Bansal
- DagsHub project
- Original paper
Challenge 2: 3D Datasets
Knowing that 3D modeling is a raising field in the ML ecosystem, we decided to help promote it and added 3D data catalog capabilities to DagsHub. From now, users are able to upload 3D Models or motion clips to DagsHub and see, move and diff it. With this feature, 3D modeling practitioners can find the dataset they need on DagsHub, explore and even stream them to any machine. You can see a vivid example of this (extremely cool) feature in our HUMAN4D project.
To enrich the datasets available for the community, we decide to launch the second challenge that focus on contribution of open-source 3D Datasets. You can find them all here!
3D Poses in the Wild Dataset
The 3D Poses in the Wild dataset is the first dataset containing precise 3D poses available for analysis in the wild. The first to integrate video footage captured by a moving phone camera is 3DPW. It has a number of motion sequences that are separated into the imageFiles and sequenceFiles folders. The RGB images for each sequence can be found in the folder imageFiles.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
FreiHAND Dataset
The FreiHAND dataset is used to test and train deep neural networks to estimate the position and shape of hands from single-color photos. 32560 unique training samples and 3960 unique evaluation samples are included in the most recent version.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
ModelNet40 Dataset
The ModelNet40 collection includes point clouds of created objects. The original ModelNet40 comprises of 12,311 CAD-generated meshes in 40 categories (including automobiles, plants, and lamps), of which 9,843 are used for training and the remaining 2,468 are saved for testing.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
ShapeNetSem Dataset
These files, which are made available to the academic community, contain ShapeNetSem, a subset of ShapeNet that has been extensively annotated with physical features. There are numerous model data points accessible. You will also discover a metadata.csv (comma-separated value format) file that provides the metadata related to each model in addition to the model data. You can re-download the most recent metadata from the ShapeNet server in addition to the existing CSV file by going to the following URL.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
Thingi10K Dataset
Thingi10K is a dataset of 3D-Printing Models. On thingiverse.com, there are 10,000 models of featured "things" that may be used to test 3D printing processes including structural analysis, form optimization, and solid geometry procedures.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
PanoContext Dataset
The PanoContext dataset contains 500 annotated cuboid layouts of indoor environments such as bedrooms and living rooms. The field-of-view of typical cameras is quite tiny, which is one of the primary reasons why contextual information isn't as valuable for object recognition as it should be. The images in this dataset were generated using 360◦ full-view panoramas.
- Contributed by: Arnav Raina
- DagsHub project
- Original dataset
BuildingNet Dataset
BuildingNet is a large-scale dataset of 3D building models with tagged exteriors. The dataset contains 513K annotated mesh primitives, which are organized into 292K semantic part components spread throughout 2K building models. The collection includes a variety of building types, including residences, churches, skyscrapers, town halls, libraries, and castles.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
SHREC19 Dataset
The entire collection is made up of hundreds of shape pairings made up of meshes that depict deformable human body forms. The poses and identities of shapes in these categories alter. The meshes display two sorts of variations: Density (from 5K to 50K vertices) (from 5K to 50K vertices). Distribution (uniform and non-uniform) (uniform and non-uniform).
- Contributed by: Sahil Danayak
- DagsHub project
- Original dataset
Replica Dataset
The Replica Dataset contains high-quality reconstructions of various interior settings. Each reconstruction contains clean, rich geometry, textures with high resolution and dynamic range, glass and mirror surface information, planar segmentation, and semantic class and instance segmentation.
- Contributed by: Samuelkb
- DagsHub project
- Original dataset
Challenge 3: Audio Datasets
Since last year’s audio dataset challenge was a smashing success, we’ve brought it back for Challenge 3! Last year, audio data catalog capabilities were added. This allows users to upload audio files to DagsHub and see its spectrogram, wave, and even listen to it! You can check it out in the Librispeech-ASR-corpus project and find other audio datasets here.
Urban Sound 8K Dataset
Urban Sound 8K is an audio dataset that contains 8732 labeled sound excerpts of urban sounds from 10 classes: air_conditioner, car_horn, children_playing, dog_bark, drilling, enginge_idling, gun_shot, jackhammer, siren, and street_music.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
FSDnoisy 18K
The FSDnoisy18k dataset is an open dataset containing 42.5 hours of audio across 20 sound event classes, including a small amount of manually-labeled data and a larger quantity of real-world noisy data. The audio content is taken from Freesound, and the dataset was curated using the Freesound Annotator. The 20 classes of FSDnoisy18k are drawn from the AudioSet Ontology and are selected based on data availability as well as on their suitability to allow the study of label noise to occur in a clip despite sometimes only one may be tagged. Another example is Wind and Rain.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
FSL4 Dataset
The FSL4 dataset contains ~4000 user-contributed loops uploaded to Freesound. Loops were selected by searching Freesound for sounds with the query terms loop and bpm, and then automatically parsing the returned sound filenames, tags and textual descriptions to identify tempo annotations made by users. The dataset contains a number of raw audio files in different formats (wav, aif, flac, mp3 and ogg), and a metadata.json file with metadata about the audio files.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
Warblrb10k Dataset
warblrb10k is a collection of 10,000 smartphone audio recordings from around the UK, crowdsourced by users of the bird recongition app, Warblr. The audio covers a wide distribution of UK locations and environments, and includes weather noise, traffic noise, human speech and even human bird imitations. This repository contains two sets of data, mainly for development followed by training purposes.
- Contributed by: Rutam Prita Mishra
- DagsHub project
- Original dataset
LEGOv2 Database
This spoken dialogue corpus contains interactions captured from the CMU Let's Go (LG) System by Carnegie Mellon University in 2006 and 2007. It is based on raw log-files from the LG system.
- Contributed by: Arnav Raina
- DagsHub project
- Original dataset
All good things must come to an end. But do they?
While the Hacktoberfest ‘22 challenge is over, the ML community continues to grow. Open-source tools and contributions are at the core of DagsHub. So, if you are still looking to work on contributions or open-source projects, we’d love to support you!
Please reach out on our Discord channel for more details.
See you for Hacktoberfest 2023 🍻



