Top Challenges in Data Management for Machine Learning Projects
- Yono Mittlefehldt
- 5 min read
- 3 years ago

As the Machine Learning field has evolved and grown over the last decade, the industry has hit pain points along the way. A lot of these growing pains stem from taking a pure research idea and scaling it for production. One major challenge here is data management.
Data management may sound harmless on the surface but it’s a complicated, multifaceted problem.
Let’s draw a parallel to a different kind of data management, first.
Think about your computer in general. When you set up a computer from scratch, everything is clean and organized. That's because you haven’t added any data yet. Over the next few weeks (and maybe months if you’re really good), as you create documents and projects you’re able to keep an organized structure to your folders.
But then chaos creeps in — slowly at first. It might start with the thought, “I’ll just save this file to the desktop and move it later.” This is the first crack in your organizational system. Within a short period of time, your computer looks like this and you begin to question your life choices:
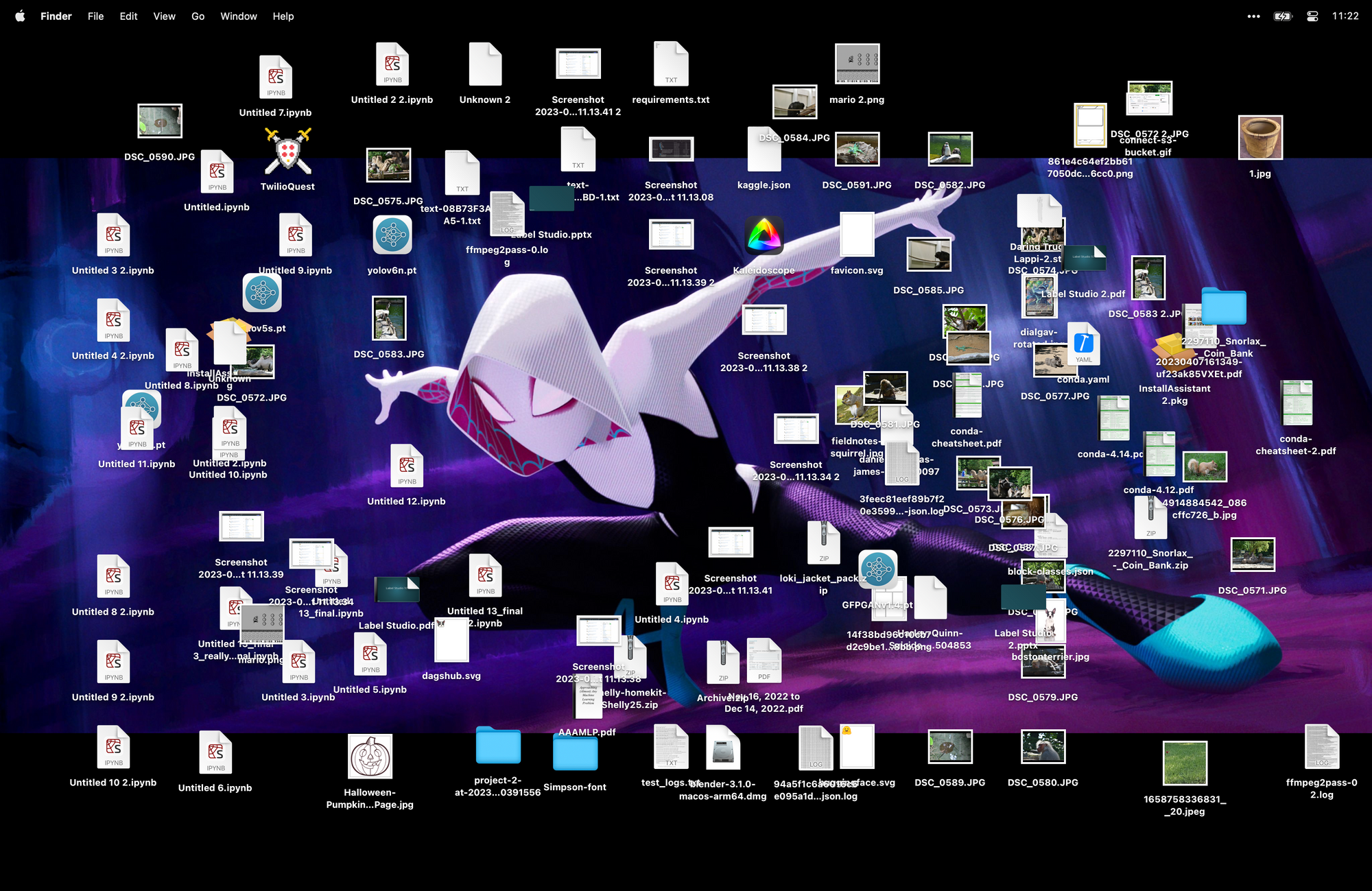
This very real mess is not unlike what happens with datasets used to train ML models.
Key Challenges in Data Management for Machine Learning
Instead of listing a bunch of challenges or problems in the field of data management for machine learning, let’s instead consider a fictional startup, RecyclingHub.
The founders of RecyclingHub are passionate about recycling. The two biggest problems in recycling are:
- It’s too expensive
- People are bad at sorting recycling
RecyclingHub addresses these issues using machine learning. By having models sort recycling, they hope to lower costs and encourage more people to recycle.
Many datasets
During the research phase, RecyclingHub builds a proof of concept to sort plastics. To do so, they use a single dataset for creating their prototype machine learning model. Managing a single dataset is fairly easy.
Having created a pretty decent model, they’re ready to scale their operation for production. However, once they move from the research phase to the production phase, they quickly discover a single dataset is not enough.
They need many datasets. More specifically, they need to use many subsets of their data.
First, they discover that accuracy degrades when they try to train a model to sort glass, metal, and paper in addition to plastics. They decide to create a specialized model for each material type and ensemble them in production. Each model requires its own dataset.
However, that’s not all. They soon discover that each model has its own edge cases, where they perform poorly. To fix this, they need to be able to slice datasets into subsets for specific tasks and edge cases. These new datasets are then carefully annotated and used to train fine-tuned models for the edge cases.
Furthermore, they need more datasets each time their data scientists test their hypotheses using experiments aimed to improve model accuracy.
With so many datasets, it’s difficult to ensure everything is using the correct and necessary data.
Datasets are dynamic
RecyclingHub also quickly discovers these datasets are too static. A static dataset is often a stale one.
They need to ensure their datasets are dynamic.
As new products come out, new packaging for those products is created — sometimes, very novel packaging. When this novel packaging makes its way to recycling centers, RecyclingHub’s systems struggle.
Since one of RecyclingHub’s main value propositions is to reduce costs, the misidentified recycling material is very bad. Each piece of incorrectly sorted recycling makes the customer’s entire operation more expensive. This makes RecyclingHub’s customers unhappy.
To counter this, RecyclingHub begins to continuously gather new data, annotations, and predictions. This new data allows them to improve their models as deficiencies are found and as new kinds of inputs (trash) are introduced.
RecyclingHub realizes the need to iterate on annotation, training, evaluation, and active learning in a moving environment.
Linking datasets to trained models
As RecyclingHub’s business grows, they create more and more machine learning models. Sometimes these are improvements to currently deployed models, sometimes experimental models, and sometimes customer-specific models. For instance, a recycling plant in Japan, which integrates RecyclingHub’s systems needs models that better understand the packaging found in Japanese recycling. Japanese packaging greatly differs from those found in the US.
To maintain all of these models, RecyclingHub needs to link datasets to trained models.
They already have many datasets. But knowing which dataset was used to train which model is paramount to their operations. Were the datasets not properly linked, the likelihood of errors during new training runs increases.
If this happens, both customers in Japan and the US would suffer deteriorated accuracy in their recycling centers, costing them more money.
Metadata and annotations
At one point, one of RecyclingHub’s customers contacts their customer support. They feel the quality of RecyclingHub’s sorting system has been slightly worse for the last two months. They corroborate this with financial data showing an increase in costs during this time frame.
RecyclingHub now has a rough date for when things went out of whack with their models. They see that they upgraded from version 5.0.23 to 5.0.24 around that time.
Unfortunately, their internal system doesn’t track their metadata and annotation changes. They know what their current data and metadata look like, but not what it looked like two months ago. This means that while they can revert the customer’s model, they’ve lost at least two months of development time.
Keeping good metadata records can be the difference between being able to rigorously debug model issues and just making best-guess estimates.
Ideally, metadata isn’t just associated with data, but changes to it are also tracked. Knowing how their data was labeled a month ago, compared to now would allow them to find potential issues or improvements to their data pipeline.
RecyclingHub Woes
Part of RecyclingHub’s problems stems from the fact that their current data management solution isn’t a cohesive one. They create their solution piecemeal as they run into problems. They do not have the resources or time to write their own custom system and they cannot find a data warehouse solution that fits their workflow.
Current data warehouse solutions often:
- much worse with unstructured data
- don’t address all of these data management problems
- are very far from a typical data scientist’s technical comfort zone, or
- client libraries and backend ecosystems require lots of glue code and cognitive load for data scientists to start using them
As such, RecyclingHub is kind of stuck in a holding pattern, hoping for an easy-to-use, cohesive solution to reveal itself.
Data management for machine learning is a hard problem masquerading as a much simpler one. This is one area we can all learn a lot from each other.
Are you running into these issues at your company or for your projects? We’re planning on exploring this topic in several blog posts going forward and are very interested to hear about your experiences.
Are you using DagsHub to help with any of these problems? Is there anything DagsHub could do to make it easier to deal with these problems?
The RecyclingHub founders are super interested in your answers too!
Join our Discord Community and let us know. We’d love to hear your thoughts.



