Best 8 Data Version Control Tools for Machine Learning 2024
- Zoumana Keita
- 9 min read
- 3 years ago
Zoumana is Data Scientist. He loves to build solutions that are beneficial to society. He also likes to share his knowledge about AI technologies with the community through YouTube, Medium & LinkedIn.

A complete overview revealing a diverse range of strengths and weaknesses for each data versioning tool.
Introduction
With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
To help data practitioners, this blog will cover eight of the top data versioning tools in the market. It will provide a clear explanation of each tool, including their benefits and drawbacks of each of them.
Why do we need to version our data?
Keeping track of the different versions of data can be challenging as trying to juggle multiple balls at a time. Without proper coordination, balance, and precision, things can quickly fall apart. The following points illustrates some of the main reasons why data versioning is crucial to the success of any data science and machine learning project:
Storage space
One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well. So, not having enough space makes it hard to store them, which ultimately leads to failure.
Data auditing and compliance
Almost each company face data protection regulations such as GDPR, forcing them to store certain information in order to demonstrate compliance and history of data sources. In this scenario, data versioning can help companies in both internal and external audits process.
Storage and reproducibility of experiments
Developing machine learning models goes beyond running codes, but about training data and the right parameters. Updating the models is an iterative process, and it requires tracking all the changes previously made. This tracking becomes crucial even in a more complex environment involving multiple users. Using data versioning can make it possible to have the snapshot of the training data and experimentation results to make the implementation easier at each iteration.
The above challenges can be tackled by using the following eight data version control tools.
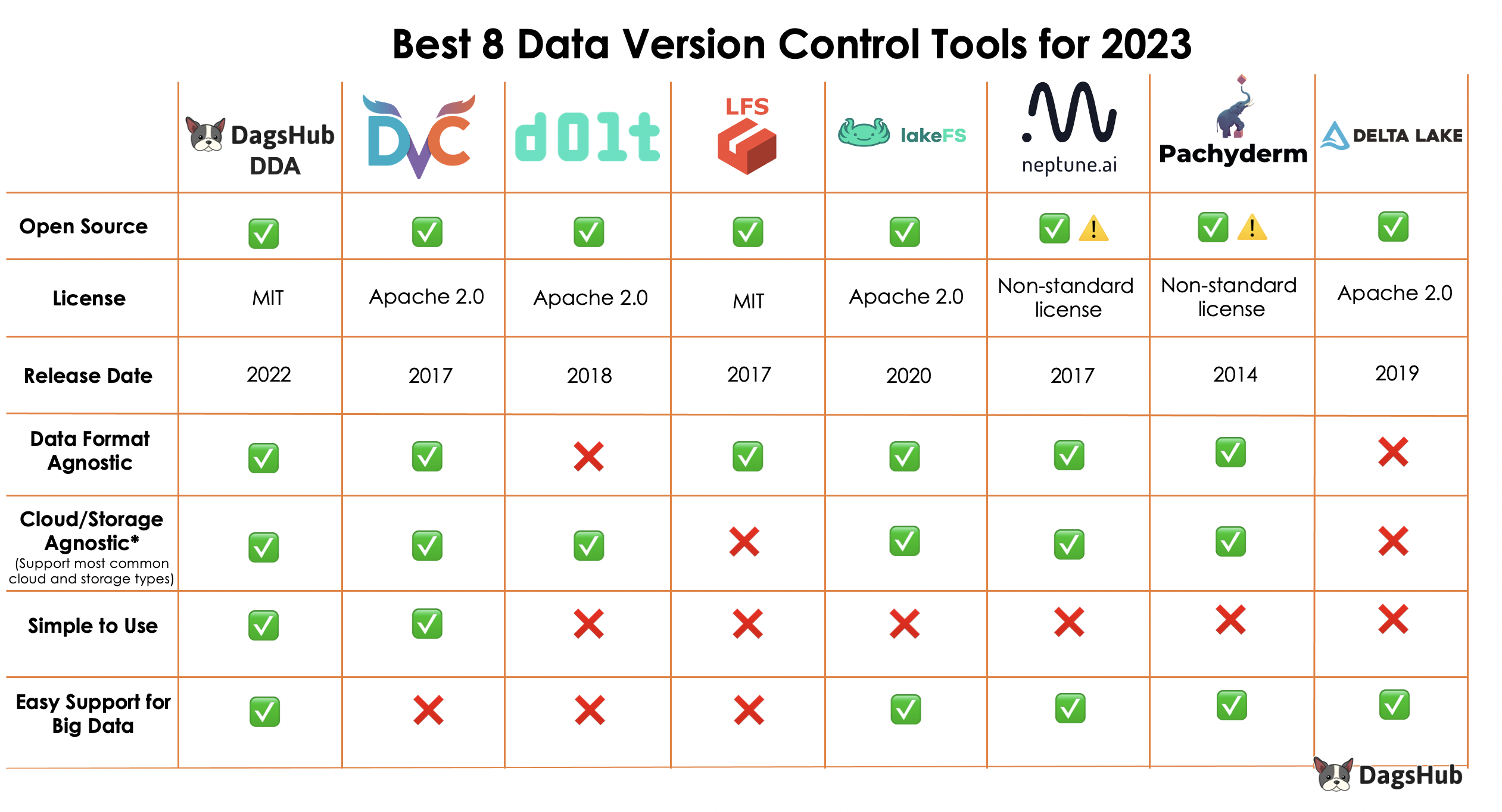
Best data version control tools for 2024
Now that you have a clear understanding of the expectations of the blog, let’s explore each one of them, starting with DagsHub.
DagsHub
DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more.

Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time. This can prevent lengthy data downloads to the local disks before initiating their mode training.
Strengths
- With DDA, there is no need to pull all the training data to a local disk, which can help save time and memory storage.
- It gives the same organization and reproducibility provided by DVC, with the ease of use and flexibility of a data API, without requiring any changes to your project.
- DDA makes it possible to upload data and version it using DVC without the need to pull all the data. DagsHub calculates the new hashes, and commit the new DVC-tracked and modified Git-tracked files on the users’ behalf.
Weakness
- It does not work with connected GitHub repositories to DagsHub.
- It does not support the ‘dvc repro’ command to reproduce its data pipeline.
DVC
Released in 2017, Data Version Control (DVC for short) is an open-source tool created by iterative.
DVC can be used for versioning data and models, to track experiments and compare any data, code, parameters models and graphical plots of performance.
Strengths
- Open source, and compatible with all major cloud platforms and storage types.
- DVC can efficiently handle large files and machine learning models.
- Built as an extension to Git, which is a standard tool used by many developers for source code versioning.
Weakness
- It fails when dealing with very large datasets, because of the computation of the hashes that takes a considerable amount of time.
- Collaboration with others requires multiple configurations such as setting up remote storage, defining roles, and providing access to each contributor, which can be frustrating and time-consuming.
- Adding new data to the storage requires pulling the existing data, then calculating the new hash before pushing back the whole data.
- DVC lacks crucial relational database features, making it an unsuitable choice for those familiar with relational databases.

Dolt
Created in 2019, Dolt is an open-source tool for managing SQL databases that uses version control similar to Git. It versions tables instead of files and has a SQL query interface for those tables.
This enhancement in the user experience is achieved by enabling simultaneous changes to both data and structure through version control.
Strengths
- It can be integrated into the users’ existing infrastructure like any other SQL database, and guarantees the ACID property.
- Most developers are familiar with Git for source code versioning. So, Dolt’s integration with Git makes it easier to learn.
Weakness
- Dolt purely relies on the ACID property, meaning that it is only useful when dealing with relational databases.
- It does not provide high performance for computing very large amounts of data (petabyte-scale data).
- Since it is only designed for relational databases, it does not support unstructured data such as images, audio, and free-form text.
Git LFS
Git Large File Storage (Git LFS) is an open-source project developed by Atlassian to extend Git’s capability to manage large binary files like audio samples, movies, and big datasets while retaining Git's lightweight design and efficiency.
With Git LFS, large files are stored in the cloud, and they are referenced via pointers in local copies of the remote server.

Strengths
- It stores any type of file regardless of the format, which makes it flexible and versatile for versioning large files on Git.
- Developers can easily move large files to Git LFS without making any changes to their existing workflow.
Weakness
- Git LFS requires a unique remote Git server, making it a one-way door. This is a disadvantage for users who in some cases would like to revert back to using vanilla Git.
- It is not intuitive for new users due to its complexity.
- Git LFS requires a LFS server to work. Such a server is not provided by every Git hosting service and in some cases will require either setting it up or switching to a different Git provider.
LakeFS
Most big data storage solutions such as Azure, Google cloud storage, and Amazon S3 have good performance, cost-effective, and have good connectivity with other tooling. However, these tools have functional gaps for more advanced data workflows.
Lake File System (LakeFS for short) is an open-source version control tool, launched in 2020, to bridge the gap between version control and those big data solutions (data lakes).
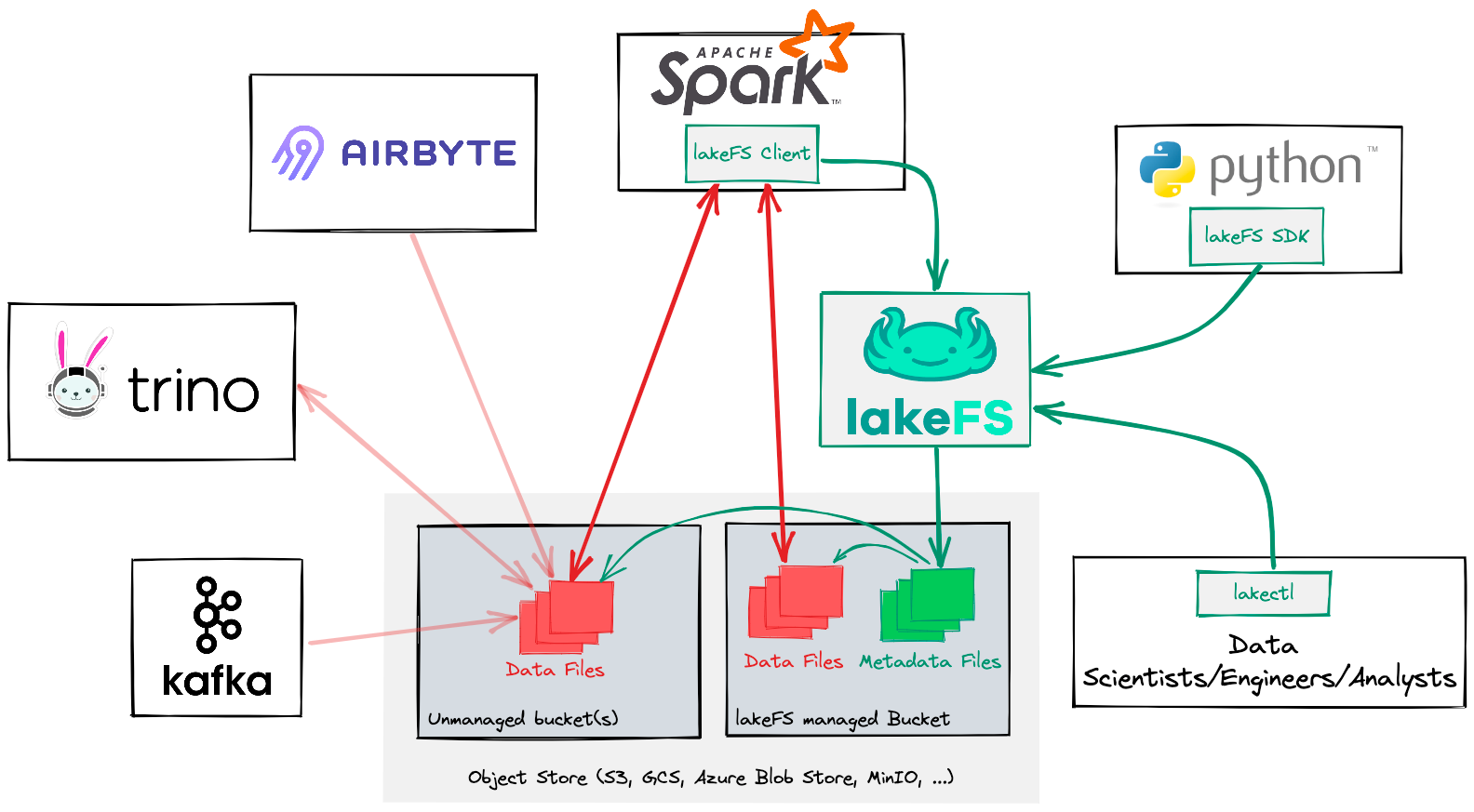
Strengths
- It works with all data formats without requiring any changes from the user side.
- It is a multi-user data management system with a secure environment for data ingestion and experimentation for all complexity levels of machine learning pipelines.
- It provides both UI and CLI interfaces and is also compatible with all major cloud platforms and storage types.
Weakness
- LakeFS heavily based on the use of object storage, and doesn’t provide much value for other use cases.
- LakeFS is only used for data versioning which is a one of the many parts of the whole data science lifecycle. This means that the integration of external tools is required when dealing with other steps of the data science or machine learning pipeline.
Neptune
Neptune is a platform for tracking and registering ML experiments and models. It can be considered as a consolidated tool for Machine Learning engineers to store in a single location the models artifacts, metrics, hyper-parameters and any metadata from their MLOps process.
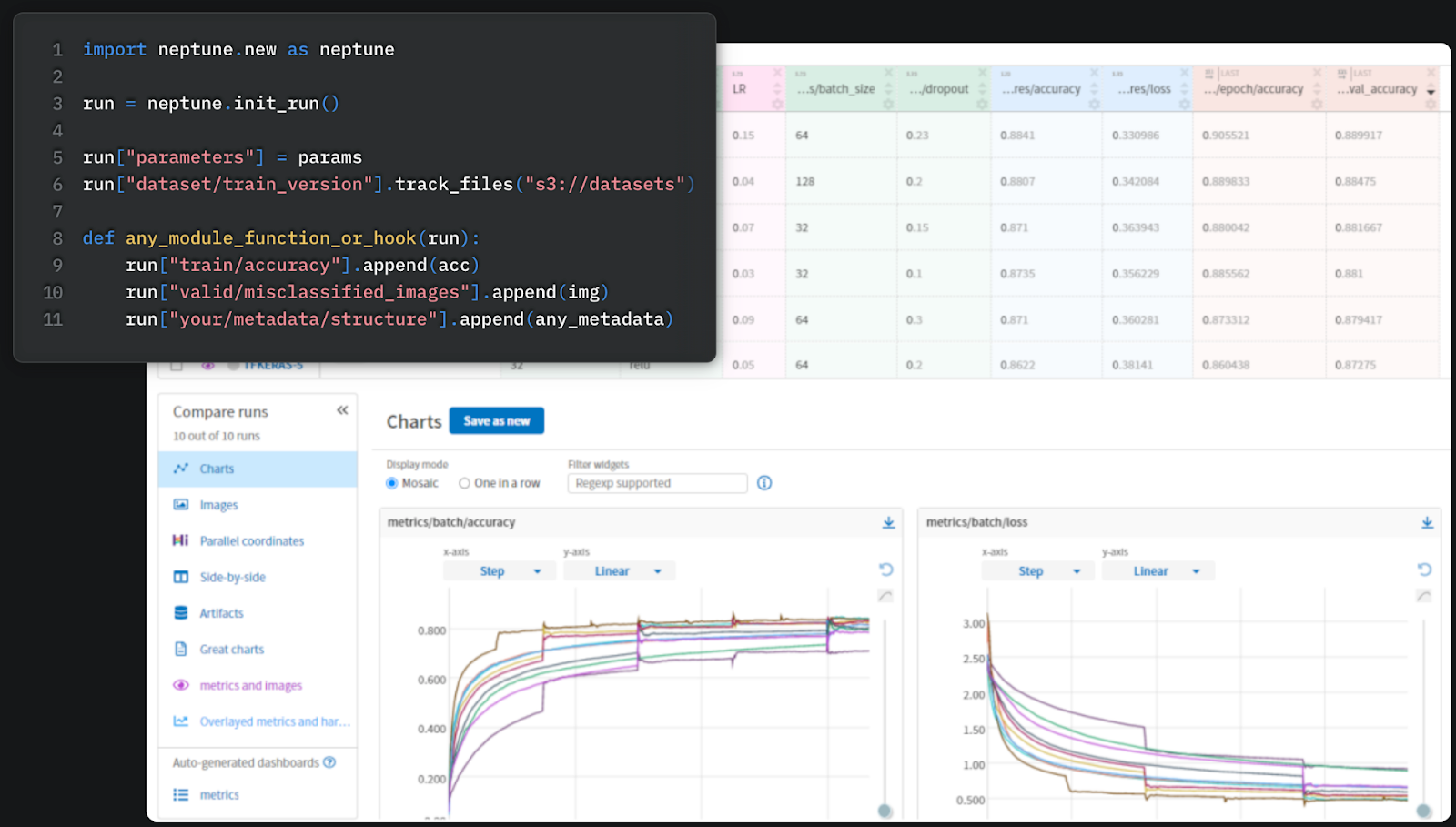
Strengths
- Intuitive collaborative interface including the capability for tracking, comparing and organizing experiments.
- Integrates with more than 25 MLOps libraries.
- Provide users with both on-premise and hosted versions.
Weakness
- Not completely open-source. Also, a single subscription likely suffices for personal use, however, it is subject to monthly usage restrictions.
- The user is responsible for manually maintaining the synchronization between the offline and online versions.
Pachyderm
Pachyderm is considered to be the data layer that powers the machine learning lifecycle by bringing petabyte-scale data versioning and lineage tracking as well as fully auto-scaling and data-driven pipelines.
Strengths
- Full supports both structured and unstructured data and any complex domain-specific data types.
- It provides both community and enterprise editions.
- Container-based, and optimized for deployment on major cloud providers and also on-premise.
- It has a built-in mechanism for tracking data versions and preserving data integrity over time.
Weakness
- The community edition has a limited number of 16 pipelines.
- Incorporating Pachyderm into existing infrastructure can be challenging due to the large number of technology components it includes. This can also make the learning process challenging.
Delta Lake
Delta Lake, by Databricks, is an open-source data lake storage layer that runs on top of existing data lake file systems such as Hadoop Distributed File System (HDFS) and Amazon S3. It provides ACID transactions, scalable metadata management, and schema enforcement to data lakes. Delta Lake supports batch and streaming data processing and allows multiple concurrent readers and writers.
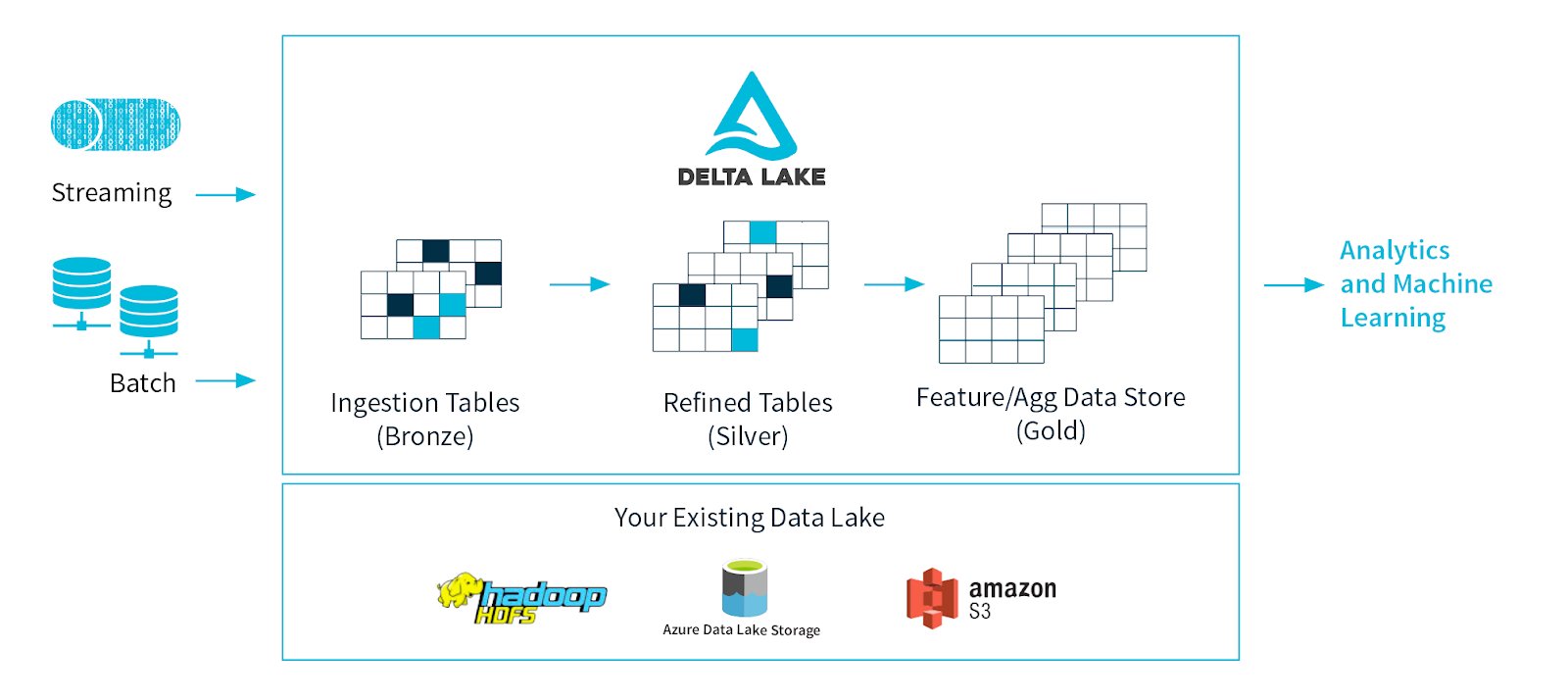
Strengths
- Delta Lake provides transactional guarantees for data lake operations, which ensures that data operations are atomic, consistent, isolated, and durable (ACID). This makes Delta Lake more reliable and robust for data lake applications, especially for those that require high data integrity.
- It also provides schema enforcement, which ensures that all data in the data lake is well-structured and follows a predefined schema. This helps to prevent data inconsistencies, errors, and issues arising from malformed data.
- The compatibility with Apache Spark APIs facilitates its integration with existing big data processing workflows.
- Automation of the tracking and management of different data versions, which reduces the risk of information loss or any inconsistencies in the data over time.
Weakness
- While Delta Lake provides a lot of powerful features, it also introduces additional complexity to the data lake architecture.
- It has a limited data format (Parquet), which is not suitable for other popular data formats such as CSV, Avro, JSON, etc.
- Learning Delta Lake is not straightforward and requires a better understanding of distributed systems and big data architecture to efficiently manage large datasets.
Conclusion
We covered the best 8 data version management tools, revealing a diverse range of strengths and weaknesses for each one. While some tools are more intuitive and excel in speed and simplicity, others offer more advanced features and greater scalability.
When making a choice, I recommend carefully considering the specific requirements of your project and to evaluate the benefits and drawbacks of each option. The right choice will depend not only on the unique needs and constraints of your organization but also on your objectives.
FAQs
Why is version control so helpful when collaborating with people?
Because it offers a centralized and organized platform for employee collaboration, as well as support for remote repository backups.
What is an example of a tool used for version control?
An example is Direct Data Access by DagsHub. It allows Data Scientists and Machine Learning engineers to avoid the lengthy data download to the disk before initiating their mode training, and this can be a better solution to tackling the storage issue.
What is a version control tool for machine learning?
It is the process of tracking and managing changes in the data science workflow, from data collection, and data exploration, to training and maintaining the machine learning models in the production environment.



