Best 8 Experiment Tracking Tools for Machine Learning 2024
- Eryk Lewinson
- 12 min read
- 3 years ago
Book Author, Tech Writer | Senior Data Scientist

Building machine learning models is a highly iterative process. After building a simple MVP for our project, we will most likely carry out a series of experiments in which we try out different models (along with their hyperparameters), create or add various features, or utilize data preprocessing techniques. All with the goal of achieving better performance.
As the number of experiments increases, it becomes challenging to keep track of them. At this point, a piece of paper or an Excel sheet might not be sufficient. Moreover, additional complexity arises when we potentially need to reproduce the best-performing experiment before putting it into production. This is where ML experiment tracking comes into play!
What is ML Experiment Tracking?
ML experiment tracking is the process of recording, organizing, and analyzing the results of ML experiments. It helps data scientists keep track of their experiments, reproduce their results, and collaborate with others effectively. Experiment tracking tools enable us to log experiment metadata, such as hyperparameters, dataset/code versions, and model performance metrics. Furthermore, we can easily visualize experiment results and compare their performance. By doing so, we can identify the most effective combinations of hyperparameters and other experimental settings, leading to better-performing models.
How to Choose the ML Experiment Tracking Tool that Fits Your Needs?
Running experiments without proper tools can easily result in a disorganized and unmanageable workflow, even for simple projects. As a data scientist, it is essential to choose the right experiment tracking tool that best fits your needs and workflow. With numerous options available, the task of selecting the ideal tool can be daunting.
In this article, we will delve into some of the most popular experiment tracking tools available and compare their features to help you make an informed decision. By the end of this article, you will have a clear understanding of each tool's strengths and limitations, allowing you to choose the best one for your specific needs.
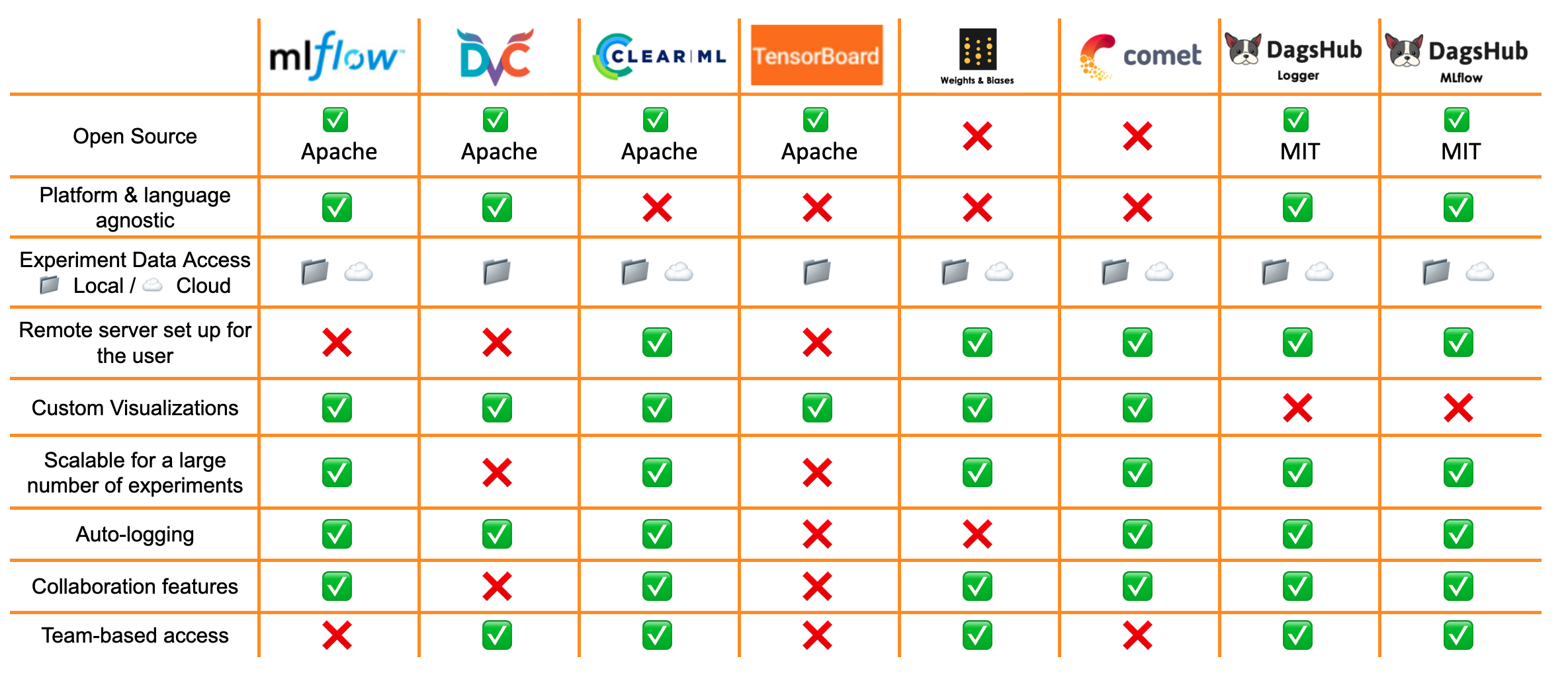
A comprehensive comparison of experiment tracking tools
MLflow

MLflow is an open-source platform designed to manage the end-to-end machine learning lifecycle. It offers a suite of tools for experiment tracking, storing, and versioning ML models in a centralized registry, packaging code into reproducible runs, and deploying models to various serving environments and platforms.
Main characteristics
- MLflow is a highly customizable open-source project.
- MLflow is language- and framework-agnostic, and it offers convenient integration with the most popular machine learning and deep learning frameworks. It also has APIs for R and Java, and it supports REST APIs.
- MLflow offers automatic logging for the most popular machine learning and deep learning libraries. By using it, we do not have to use explicit log statements to keep track of metrics, parameters, and models.
- It is effortless to integrate MLflow into an existing codebase with just a few lines of code.
- MLflow has a very large and active community and is widely adopted in the industry.
- MLflow can log results both locally and to a remote server, enabling a team of data scientists to share a single dashboard.
- In the case of storing large files, MLflow can be configured to store them on S3 or another cloud storage provider.
- MLflow's web UI allows for the viewing and comparison of results from numerous experiments carried out by different users.
- Additional notes about experiments can be stored in MLflow.
- MLflow offers not only experiment tracking but also end-to-end ML lifecycle management.
Keep in mind
- MLflow is only available as an open-source solution. As such, using MLflow in a company setting requires maintaining servers and infrastructure to support the tool, which might be challenging for smaller organizations.
- In terms of security, MLflow does not have robust security features out-of-the-box. Therefore, it might require additional configuration and setup to ensure the secure handling of sensitive data and managing access control. As such, it might not be that easy to share experiment results with others.
- While MLflow supports collaboration, it does not have the same level of collaboration features as some other platforms.
DagsHub

DagsHub is a web-based platform that provides a suite of tools for managing and collaborating on machine learning projects. It is designed to help data scientists and machine learning engineers track, version, and share their code, together with the corresponding data and experiments.
Main characteristics
- DagsHub enables effortless tracking and management of machine learning experiments, including hyperparameters, metrics, and code versions.
- With collaborative coding tools, DagsHub provides a central location for data science teams to visualize, compare, and review their experiments, eliminating the need to set up any infrastructure.
- DagsHub detects and supports DVC's
metricsandparamsfile formats, and it also sets up a DVC remote where we can version our data. - It is possible to use DagsHub with your own data storage or use a virtual private cloud/on-prem solution.
DagsHub offers two distinct ways to track experiments: via MLflow and Git.
DagsHub MLflow
- By using DagsHub’s MLflow implementation, the remote setup is done for us, eliminating the need to store experiment data locally or host the server ourselves.
- The implementation already comes with team-based access and security protocols.
- It additionally covers features such as live logging, experiment database, artifact storage, model registry, and deployment.
DagsHub Logger
- The Git implementation relies on simple, transparent, and open file formats. Thanks to the DagsHub logger, it is incredibly easy to adapt to any language or framework and export the tracked metrics and parameters with a simple Git push.
- The Git integration means that experiments are automatically reproducible and linked to their code, data, pipelines, and models.
- Auto-logging capabilities of the DagsHub logger cover three frameworks: PyTorch Lightning, Keras, and fast.ai v2.
- Currently, there is no support for live logging using the logger approach.
Keep in mind
- It is not possible to create advanced or custom visualizations at this time.
- DagsHub is free to use for open-source and personal projects. For organizations, DagsHub is a commercial platform and certain features require a paid subscription.
DVC

DVC (Data Version Control) is an open-source MLOps tool for data versioning and experiment tracking. It is often described as a Git-like system used for versioning your data and models. Essentially, DVC enables us to track data with Git without storing the data in the Git repository. Furthermore, it provides pipeline management functionalities, which help with experiment reproducibility.
Main characteristics
- DVC is an open-source, language-agnostic tool that is free to use.
- DVC uses Git-like commands for version control, making it easy for developers who are already familiar with Git.
- Tracked metrics are stored in plain text files and versioned with Git.
- DVC handles everything for us in a clean way that doesn't clutter the repository, so we don't need to create dedicated Git branches for each experiment.
- DVC is platform-agnostic and can work with a wide range of storage providers, making it easy to manage data across different platforms.
- DVC can track changes to code, data, and artifacts, making it easy to reproduce any executed experiment, even if one of the components changes.
- DVC is easy to use and doesn't require special infrastructure or external services. We can track experiments (and other components) locally or using a cloud remote.
- With DVC, we don't need to rebuild previous models or data modeling techniques to achieve the same past state of results.
- With DVC, we can also track output images of each experiment, such as confusion matrices or feature importance plots.
- We can work with DVC-tracked experiments from the command line or leverage Iterative Studio (previously called DVC Studio), a web application that we can access online or host on-prem. Alternatively, DVC offers a VS Code extension that facilitates experiment management, comparison, and evaluation, all within the IDE.
- We can easily log machine learning parameters, metrics, and other metadata in simple file formats using a companion library called DVCLive. It also provides auto-logging for the most popular machine learning and deep learning libraries.
Keep in mind
- In some cases, you might encounter scalability issues when working with very large datasets or a large number of experiments.
- Storage is organized in a content-addressable, and all operations are executed using a Git repo. Without working with it before, it might come off as unexpected and while there are a lot of benefits for this, it might be that some teams cannot integrate that approach with their tools.
- While DVCLive supports auto-logging for the majority of frameworks, it does not support
scikit-learn.

ClearML

ClearML is an open-source platform for managing machine learning (ML) experiments. It allows users to easily track, monitor, and reproduce their ML experiments, visualize their results as well as collaborate with team members.
Main characteristics
- ClearML provides easy experiment tracking and management, allowing users to keep track of experiments, metrics, hyperparameters, metadata, and more.
- ClearML supports automatic logging. It also logs any metrics reported to leading visualization libraries such as TensorBoard and Matplotlib. Additionally, ClearML captures and logs everything written to standard output, from debug messages to errors and library warning messages. Lastly, it automatically tracks information such as usage of GPU, CPU, Memory, and Network.
- ClearML is compatible with leading machine learning and deep learning libraries.
- ClearML can be deployed either on-premises or in the cloud. We can interact with the platform using either a web interface or a Python API.
- We can work with ClearML experiments in offline mode, in which all information is saved in a local folder.
- ClearML allows multiple users to collaborate on the same project, enabling easy sharing of experiments and data.
- ClearML provides users with various visualizations, making it easy to interpret and analyze experiment data. Additionally, its customizable UI enables users to sort models by different metrics.
- ClearML is easy to integrate into existing workflows.
- ClearML has built-in hyperparameter optimization capabilities.
Keep in mind
- While ClearML offers a free tier, more advanced features (for example, hyperparameter optimization or role-based access control) require a paid subscription.
- ClearML has a smaller user base compared to other similar platforms, which can make finding support or resources more difficult.
- Due to the large number of modifications that need to be run for auto-logging (ClearML replaces some built-in functions of other frameworks), the system may be comparatively fragile.
- Setting up and configuring ClearML can be challenging, especially for users who are new to the platform. For example, installing the open-source version on your servers is relatively complicated compared to MLflow.
TensorBoard

TensorBoard is an open-source, web-based visualization tool for machine learning experiments that makes it easier to understand, debug, and optimize TensorFlow models. It provides a suite of visualizations for monitoring training progress, evaluating model performance, and visualizing data flow graphs.
Main characteristics
- TensorBoard is often the first choice for TensorFlow users as it enables us to track our machine learning experiments and visualize various aspects such as metrics (e.g. loss and accuracy) or model graphs. Additionally, we can use it to compare experiments.
- TensorBoard is not limited to tracking experiments based on TensorFlow alone.
- TensorBoard includes the What-If Tool (WIT), which is an easy-to-use interface for explainability and understanding of black-box ML models.
- The strong and large community of users provides excellent support for TensorBoard.
- In addition to the open-source, locally-hosted version, TensorBoard.dev is available as a free service on a managed server, which allows us to host, track, and share our ML experiments with anyone.
- TensorBoard also provides well-developed features for working with images.
Keep in mind
- Some users may find TensorBoard complex to use, with a steep learning curve.
- TensorBoard may not scale well with a large number of experiments, causing slowdowns when viewing and tracking large-scale experimentation.
- TensorBoard's capability for experiment comparison is limited.
- TensorBoard is primarily designed for single-user and local machine usage, rather than team usage.
- It lacks user management features. While sharing is available using TensorBoard.dev, there is no way to manage the privacy of data shared.
- TensorBoard does not store data or code versions, making it unable to provide full reproducibility.
Weights and Biases

Weights & Biases (W&B, or WandB) is an MLOps platform that enables experiment tracking, versioning of your data/models, as well as team collaboration on ML projects.
Main characteristics
- W&B logs various experiment metadata (such as hyperparameters, metrics, artifacts, etc.) and allows users to compare experiments and analyze performance using interactive visualizations.
- W&B makes it easy to reproduce experiments by tracking all dependencies and providing a consistent environment for each experiment.
- W&B offers a highly customizable UI that allows teams to visualize and organize their workflows, including any custom metrics and visualizations.
- W&B offers a selection of functionalities supporting collaborative work in teams.
- W&B supports all major ML/DL frameworks, cloud platforms, and workflow orchestration tools (such as Airflow).
- W&B supports deployment to a wide range of platforms, including cloud services and containerized environments.
- W&B offers built-in hyperparameter optimization functionalities through integration with leading libraries.
- It is easy to integrate W&B tracking into existing codebases.
- It is possible to set up a self-hosted instance of W&B in case of working with sensitive data that cannot be shared externally.
- It allows for easy debugging of audio, video, and image objects.
Keep in mind
- W&B is a commercial platform and might require a paid subscription for certain features.
- Limited integrations with some lesser-known ML frameworks.
- Collaboration features require a paid tier.
- The pricing plan is based on usage time (referred to as tracked hours), which may be counter-intuitive for users.
Comet

Comet (formerly CometML) is a cloud-based platform for managing and tracking machine learning experiments. Additionally, it can be used to version training data, keep track of our models in a model registry, and monitor the performance of models in production.
Main characteristics
- Comet allows us to log and track experiments, providing an easy way to visualize and compare results over time. It also offers real-time metrics and charts for the experiments being run.
- Comet offers several features that foster collaboration with a team. For example, it allows us to share projects, comment and tag other team members. Additionally, it comes with user management features.
- Comet has an integrated suite of tools for optimizing the hyperparameters of our models.
- It easily integrates with the most popular machine learning and deep learning frameworks. Additionally, it supports languages other than Python, such as Javascript, Java, R, or even REST APIs.
- Comet supports autologging for quite a big selection of the most popular machine learning and deep learning libraries.
- Comet’s platform can be used on their cloud environment, a virtual private cloud (VPC), or on-premises.
- Comet's UI is highly customizable, allowing us to easily build reports and dashboards. We can create custom visualizations for our experiments or use some of the community-provided templates.
- Comet supports not only scripts but also notebooks.
- With Comet, we can debug model errors, environment-specific errors, etc.
- Has dedicated modules for vision, audio, text, and tabular data that allow us to easily identify any issues with the dataset.
Keep in mind
- Comet is a commercial platform and might require a paid subscription for certain features.
Other tools
Even though we have already covered 7 different experiment tracking tools/frameworks, that definitely does not exhaust all the available options. For the sake of brevity, we will only mention some other alternatives, which you can research on your own.
Other experiment tracking (and not only) tools available:
- Neptune
- Sacred
- Guild.ai
- Polyaxon
- Valohai
- Kubeflow
- Verta AI
- Amazon Sagemaker Studio
- Pachyderm
Wrapping up
Due to choice overload, choosing the right ML experiment tracking tool for your project or your entire team can be a daunting task. When making this decision, you have to consider many factors such as:
- Open-source vs. commercial
- Whether the tool comes with a web UI or is console-based
- Integrations with ML/DL frameworks, cloud platforms, and programming languages
- What exactly is tracked and how easy it is to add custom things to log
- Storage - cloud-based storage or local storage
- Visualization features
- Stability and scalability
- Whether the tool facilitates collaboration between team members
- Whether the tool requires setting up a remote server by the user
- Security and team-based access
- Whether the tool offers additional features related to the ML lifecycle, for example, deployment
With this article, we have tried to explore the above for some of the most popular experiment tracking tools. Hopefully, it will help you make a decision for your next project!



