Launching FDS: Ease Of Use And Automation for Git & DVC
- Guy Smoilovsky
- 6 min read
- 5 years ago
Co-Founder & CTO @ DAGsHub

DAGsHub is proud to release a new open source command line tool, FDS, which aims to help users do Fast Data Science by streamlining day-to-day work with Git and DVC.
FDS is a command line wrapper around Git and DVC, meant to minimize the chances of human error, automate repetitive tasks, and provide a smoother landing for new users.
Why is it called fds?
Just take a look at your keyboard - it's so silky smoove to type fds!
This is important for a command line tool that exists to improve ease of use and delight users.
In fact, due to popular demand, you can also type sdf instead of fds for an even more epic experience! 🤩

Apologies to Dvorak users - maybe someday we'll release a tool called oeu, if we can come up with an appropriate meaning for the acronym.
Perhaps "Outstandingly Efficient Understanding"?
Quickstart
https://github.com/dagshub/fds
$ pip3 install fastds
$ fds -h
usage: fds [-h] [-v] {init,status,add,commit} ...
One command for all your git and dvc needs
positional arguments:
{init,status,add,commit,push,save}
command (refer commands section in documentation)
init initialize a git and dvc repository
status get status of your git and dvc repository
add add files/folders to git and dvc repository
commit commits added changes to git and dvc repository
push push commits to remote git and dvc repository
save saves all project files to a new version and pushes
them to your remote
optional arguments:
-h, --help show this help message and exit
-v, --verbose set log level to DEBUG
Motivation
As we were developing Open Source Data Science projects - such as SavtaDepth, a monocular depth estimation project - we often found ourselves doing one or more of the following:
- Running
git commit, thengit status, seeing everything is up to date, then happily runninggit push- only to remember a second later that we forgot to check thedvc status- we pushed an incorrect version to a public repo.
D'oh! - After we got burned by forgetting to commit changes to DVC tracked files enough times, we got more careful to always run
git statustogether withdvc status- to make sure everything is as expected. However, this quickly became tedious. We would often run the same combination of commands:git status ; dvc status ; dvc commit -f ; git add . ; git commit
and we wanted to automate it. - Doing
git add .out of habit, only to find a second later that we forgot to firstdvc add huge_data_dir/
This is a pain for two reasons: One is that this causes Git to inefficiently copy this huge file to its object store (something which DVC elegantly avoids). The second is that canceling this mistake involves first telling git to forget about the data dir usinggit rm -r --cached huge_data_dir/, and only then can youdvc addit.
Furthermore, we got a recurring question from many data scientists and ML engineers, who weren't previously familiar with DVC - why do I now have to learn another tool, and remember how to synchronize them all the time? Why do I have to constantly be vigilant about which file I add where, and check the status of both tools constantly? Why can't git or DVC just know that large files go into DVC, and abstract away that technical detail for me?
In general, these were strong indications that there is grunt work to be automated here - using software to do the boring, repeatable stuff and freeing up data scientists for more interesting work.
So, we set about creating FDS with these goals in mind:
- Automate common tasks when working with git, DVC, and potentially other tools which work well together later on.
- Provide a more interactive and opinionated UI and UX. Git and DVC are low level utilities which need to work well in scripts and support all possible use cases - this means interacting with them feels like interacting with a command line API, rather than a wizard or app. FDS orients itself to be used by humans, for convenience rather than total flexibility. This also means that FDS can afford to introduce workflows and features faster than DVC (and definitely faster than Git), since it is doesn't have to be stable infrastructure.
- Provide a smoother landing for new users by making things easy by default and explaining what's going on.
We took inspiration from gitless - "a Git-compatible version control system, that is easy to learn and use" - a project which works on top of Git and attempts to make it more intuitive. Check it out!
Let's see a few examples of FDS!
The full list of supported commands can be seen by looking at the Github readme, or by running fds -h
fds status
=
dvc status
+
git status
fds status lets us quickly check the full status of the repo - both DVC and git at the same time, to make sure we don't forget anything.
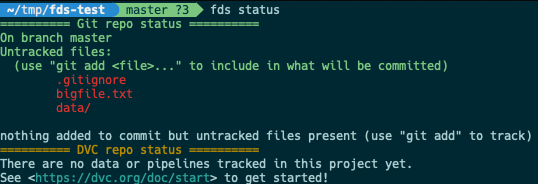
Here, we can see that we have a small, normal text file - .gitignore, plus a bigfile.txt and data folder which we would want to add to DVC and not to git. fds add makes that easy!
fds add
=
dvc add
+
git add
wizard 🧙♂️
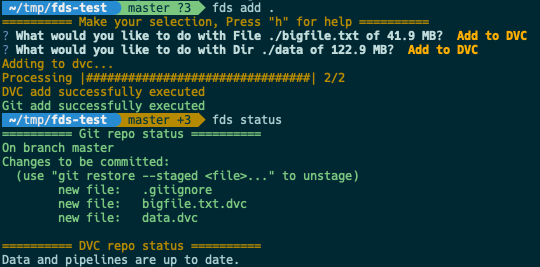
You're probably used to the convenience of using git add . to just track everything. Unfortunately, you have to be careful doing this when working with large files - one wrong move, and you might fry your hard drive by accidentally telling git to track a huge dataset!
We wanted to retain the convenience of just typing one command which means "just track all changes, I'll do a git commit in one second", which will be smart enough to avoid the pitfalls of large data files.
fds add does exactly that, while interactively asking the user how to handle files. You can add to DVC, or git, recursively step into large folders, skip or ignore files, etc.
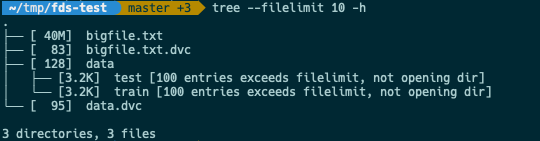
Here's the file tree of the repo I used above, with file sizes included. Note how bigfile.txt and data/ were automatically added to DVC and not git:
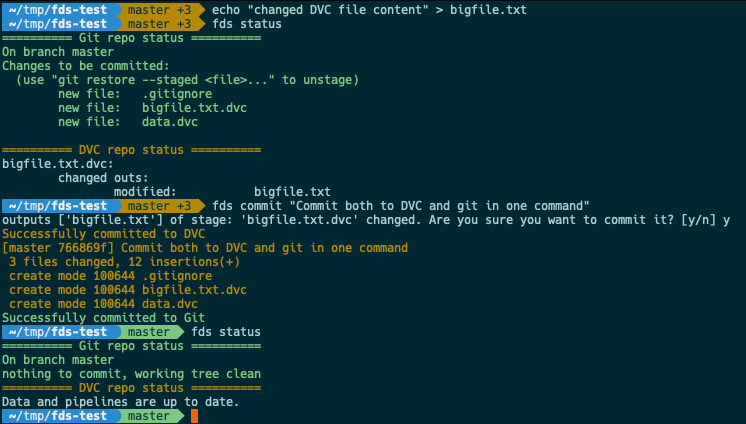
fds commit
=
dvc commit
+
git commit
Finally, to close the loop of a real workflow, what happens when I change existing DVC tracked files? Without FDS, you'd have to remember to separately run dvc repro or dvc commit, then git add tracked_file.dvc, and only then git commit.
fds commit does all that for you - commits changes to DVC first, then adds the .dvc files with the updated hashes to git, then immediately commits these changes (plus any other staged changes) to a new git commit. Voila!
What's next?
FDS is just now getting started, but we feel that it's already helpful with commands like init, status, add, commit
Going forward, we'll want to improve the UX further, support common workflows out of the box, and add more commands like:
fds push(done!)fds pullfds clonefds generate- generate projects from templates- ... and more!
Get Involved
We would love for you to try out FDS yourself, and to give us feedback. It would really help us to prioritize future features, so please vote on or create issues!
If you'd like to take a more active part, we have some good first issues that you can start with. We'll be happy to provide guidance on the best way to do so.
And of course, we're always happy to have you on the DAGsHub discord, where you can ask questions or give feedback on FDS:

Happy (and Fast) hacking!