An Introduction to Directed Acyclic Graphs (DAGs) for Data Scientists
- Dean Pleban
- 8 min read
- 5 years ago
Co-Founder & CEO of DAGsHub. Building the home for data science collaboration. Interested in machine learning, physics and philosophy. Join https://DAGsHub.com | DagsHub Co-Founder & CEO
TL;DR
I love DAGs. Directed Acyclic Graphs (DAGs) are incredibly useful for describing complex processes and structures and have a lot of practical uses in machine learning and data science.

If you're getting into the data science field, DAGs are one of the concepts you should be familiar with. If you're already a seasoned veteran, maybe you want to refresh your memory, or just enjoy re-learning old tips and tricks. In any case, this post is a great introduction to DAGs with data scientists in mind.
Since we named our platform DAGsHub, DAGs are obviously something we care deeply about. After all, they are incredibly useful in mapping real-world phenomena in many scenarios. Therefore, they can be a core part of building effective models in data science and machine learning.
There is no limit to the ways we can view and analyze data. And that means there is no limit to the insights we can gain from the right data points, plotted the right way. In this article, we're going to clear up what directed acyclic graphs are, why they're important, and we'll even provide you some examples of how they're used in the real world.
Welcome to DAGs 101! We're glad you're here. Now, let's get going.

What Is A Directed Acyclic Graph?
Before we get into DAGs, let's set a baseline with a broader definition of what a graph is. At this point, you may already know this, but it helps to define it for our intents and purposes and to level the playing field.
A graph is simply a visual representation of nodes, or data points, that have a relationship to one another. When this relationship is present between two nodes, it creates what's known as an edge.
Where a DAG differs from other graphs is that it is a representation of data points that can only flow in one direction. The best directed acyclic graph example we can think of is your family tree. Your grandma gave birth to your mom, who then gave birth to you. But that relationship can't go the other way. It's a biological impossibility.
This is what forms the "directed" property of directed acyclic graphs. What makes them acyclic is the fact that there is no other relationship present between the edges.
Meaning that since the relationship between the edges can only go in one direction, there is no "cyclic path" between data points. Hence, they are acyclic.
A great method for how to check if a directed graph is acyclic is to see if any of the data points can "circle back" to each other. If they can't, your graph is acyclic.
If it helps you, think of DAGs as a graphical representation of causal effects. Let's go back to our family tree example. Your grandmother is the cause of your mother being here. Your mother is the cause of you being here. See? The relationship between each member of your ancestry (if we view them as data points) can only flow in one direction.

DAG Properties
DAGs are a unique graphical representation of data. As such, they possess their own set of unique properties. That's why, when used in the right instances, DAGs are such useful tools.
Let's take a look at the properties of a DAG in more detail. That way you'll get a better idea of when using a DAG might come in handy.
Reachability
Reachability refers to the ability of two nodes on a graph to reach each other. Imagine this as if you start at a given node, can you "walk" to another node via existing edges. Simple enough, right? It hinges on defining the relationship between the data points in your graph.
When it comes to DAGs, reachability may be somewhat challenging to discover. The main difference between reachability in undirected vs directed graphs is symmetry.
In an undirected graph, reachability is symmetrical, meaning each edge is a "two way street". In other words node X can only reach node Y if node Y can reach node X.
In a directed graph, like a DAG, edges are "one-way streets", and reachability does not have to be symmetrical.
Reachability is also affected by the fact that DAGs are acyclic. In an acyclic graph, reachability can be defined by a partial order. A partial order is a lesser group of nodes within a set that can still define the overall relationship of the set.
Where this applies to DAGs is that partial orders are anti-symmetric. This means that node X can reach node Y, but node Y can't reach node X. Think back to the family tree. This basically means your mom can give birth to you, but you can't give birth to your mom.
In this way, partial orders help to define the reachability of DAGs.
Transitive Closure
A graph's transitive closure is another graph, with the same set of nodes, where every pair of nodes that is reachable, has a direct edge between them. This means if we have a graph with 3 nodes A, B, and C, and there is an edge from A->B and another from B->C, the transitive closure will also have an edge from A->C, since C is reachable from A.
Let's use airports as an example. If each node of a graph is an airport, and edges mean there is a flight from on airport to the other, the transitive closure of that graph would add a nonstop direct flight between any two airports that you can reach with a layover.

Transitive Reduction
The transitive reduction of any directed graph is another graphical representation of the same nodes with as few edges as possible. In many ways, this is the opposite of transitive closure. In this case, the transitive reduction requires removing any "redundant" edges between nodes, that are reachable via other paths.
Transitive reductions should have the same reachability relation as the original graph. They also should share the same transitive closure.
In the case of a DAG, the transitive reduction would be a graph that has the fewest possible edges but retains the same reachability relation as the original graph.
Topological Ordering
One of the useful features of DAGs is that nodes can be ordered topologically. This means that nodes within the graph can be put into a linear sequence by "ordering" them.
If we go back to our family tree example, the topological ordering would be generations. Your grandparents (as nodes) could be ordered into Generation 1. Your parents would be Generation 2, you and your siblings would be Generation 3, and so on and so forth.
Why DAGs Are Useful
So why is all of this useful? What does it mean to us as data scientists? Well, for one thing, DAGs are great for showing relationships. The directed nature of DAGs, as well as their other properties, allow for relationships to be easily identified and extrapolated into the future.
DAGs are also useful when it comes to optimization. Once you have your nodes plotted out on your DAG, you can use algorithms to find the shortest path from one node to another (using topological ordering).
These graphs are also helpful when it comes to data processing. The fact that DAGs are directed makes them the perfect tool for plotting out a flow of events or workflow.
Real-Life Uses of DAGs
Now that you are familiar with the concept of what a DAG is, let's nail it home. It might help you to gain a full understanding of DAGs if we go over a few real-life examples where DAGs are used every day.
Machine Learning
DAGs are useful for machine learning. This shouldn't be a surprise if you're reading this post. In order for machines to learn tasks and processes formerly done by humans, those protocols need to be laid out in computer code. This is where DAGs come in.
The structure of neural networks are, in most cases, defined by DAGs. This is the "artificial brain" of many AI and ML systems.
The use of DAGs allows for deep learning. This is because the DAG framework can handle input from multiple layers, as well as provide multiple layers of output.

Cryptocurrency/Blockchain
Cryptocurrencies are all the rage these days. Elon Musk loves to tweet about them and get them to the moon. You probably heard that these coins rely on something called the blockchain.
This blockchain is defined by something called a Merkle Tree, which is a type of DAG. This means that DAGs are also responsible for one of the biggest shifts in the finance industry.
And finally pic.twitter.com/TcgwMSyjAy
— Elon Musk (@elonmusk) July 25, 2021
Retail
Another area using DAGs to help grow their industry is the retail space. Retail, as well as other industries, are starting to switch toward a concept known as "customer journey marketing."
The idea is that nobody makes an instant decision to buy something. There is a "journey" the customer must be walked through. Retailers use advertising, and introduce their product, at multiple points throughout the journey. With the hopes of ultimately getting their prospect to buy.
Retailers use DAGs to visualize these journey maps, and decide what to focus on in order to improve their business.
Biology
DAGs exist in epidemiology to detect confounders. These are "unexpected variables" that can affect a study.
The structure of a DAG allows the person studying it to use it as a visual aid. This allows them to have easier discussions about underlying relations between possible causes. This is especially true for issues that have quite complex variables associated with them.
Versioning
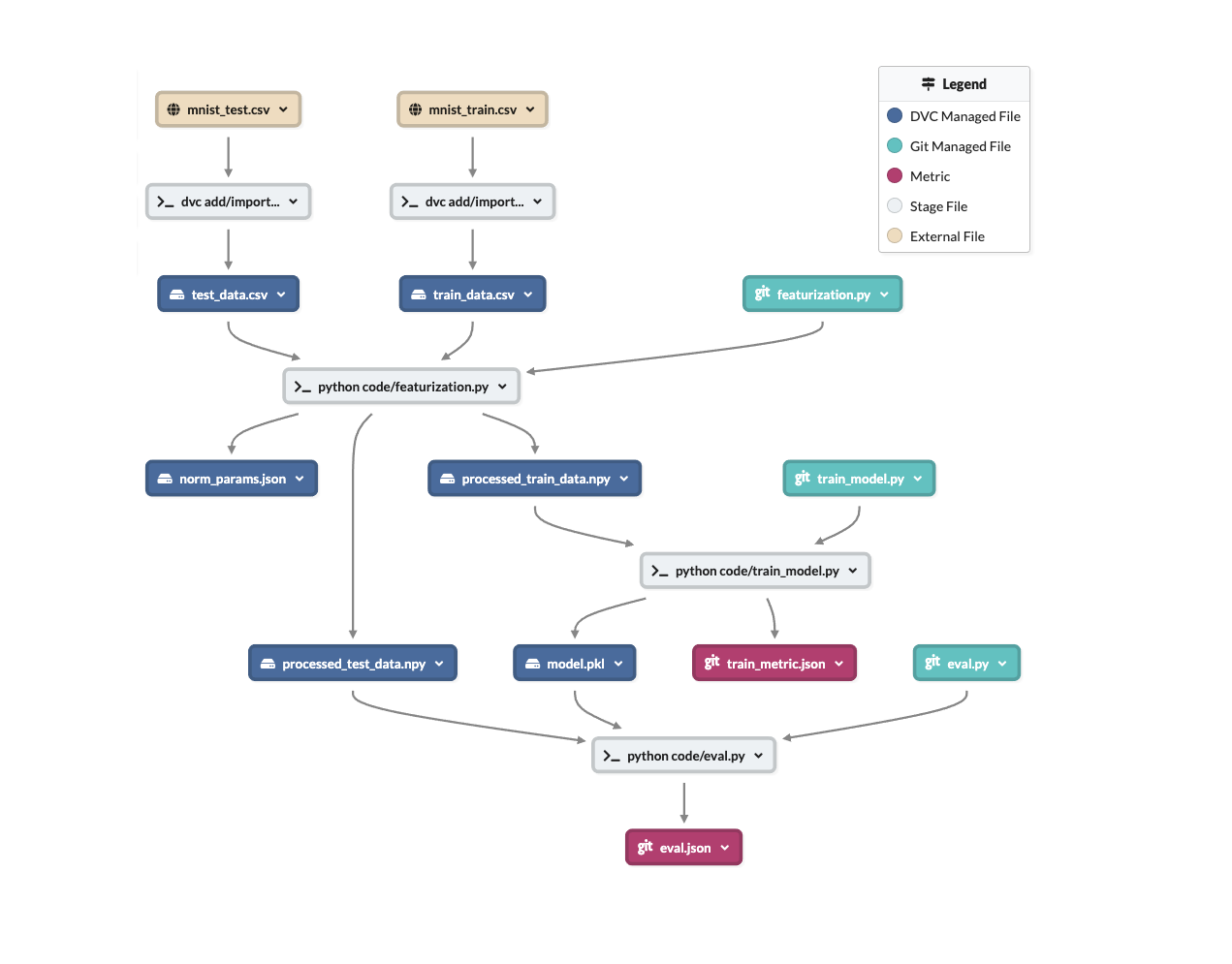
When committing changes to a build, in Git or other source control methods, the underlying structure used to track changes is a DAG (a Merkle tree similar to the blockchain). having a visualization of how those changes get applied can help. Each node contains the changes and each edge represents a relationship between states (this change came after that other change).
Using a DAG helps in making sure teams can work on the same codebase without stepping on each others' toes, and while being able to add changes that others introduced into their own project. The same principals apply to data versioning.

Scheduling
In computer science, you can use DAGs to ensure computers know when they are going to get input or not. You can use a DAG as a set of instructions to inform a program of how it should schedule processes.
If one part of the program needs input that another has not generated yet, it could be a problem. Thus, this prioritizes the right processes at the right order.
Data Pipelines – Apache Airflow
An example for the scheduling use case in the world of data science is Apache Airflow. Airflow, and other scheduling tools allow the creation of workflow diagrams, which are DAGs used for scheduling data processing. These are used to ensure data is processed in the correct order.
A Directed Acyclic Graph Explained
There you have it! You've completed this very high level crash course into directed acyclic graph. DAGs already play a major part in our world, and they will continue to do so in years to come.
If you have any questions about data science, machine learning, or any other applications for DAGs, contact us anytime. We are here to help you on your journey through the wonderful world of data science.
We hope you enjoyed this article and came out a bit wiser on the other end!



