Overcome the Reproducibility Challenge when Working with Snowflake
- Nir Barazida
- 5 min read
- 3 years ago
MLOps Team Lead @ DagsHub

Snowflake, is a cloud-based data warehousing platform for structured and semi-structured data that has gained a lot of popularity in recent years. The data is stored in micro-partitions, which are small, self-contained units of data that can be accessed and processed independently. This allows Snowflake to achieve high levels of concurrency and performance.
However, one of the challenges that come with using Snowflake is the difficulty in accessing old versions of the data. This is a major concern when it comes to reproducing results and machine learning models.
In this blog, we'll explore what Snowflake is, and then dive into the challenges of reproducibility that come with using it. Finally, I'll offer some tips and solutions to help you overcome these challenges and achieve reproducible results when working with Snowflake.
Why host data on a cloud-based service?
Organizations may experience challenges when managing their own on-premise data infrastructure, such as high costs for hardware, maintenance, and upgrades, as well as limited scalability, performance, and security.
Cloud-based data warehousing solutions like Snowflake address these challenges by offering flexible pricing, easy scalability, high-performance computing, and automatic upgrades and maintenance.
They can easily scale up and down a cloud database to accommodate changing data storage needs. They also can access a massive amount of data from any local machine with an internet connection without worrying about losing data access due to hardware failure.
Moreover, storing data on the cloud unlocks the possibility for collaboration, making it easier for teams to work together on projects regardless of their location or device. With cloud storage, multiple users can access and work on the same file simultaneously. This can streamline workflows, increase efficiency, and reduce errors caused by version conflicts.
What is Snowflake?
Snowflake is a cloud-based data warehousing and analytics platform that enables organizations to store, manage, and analyze large amounts of structured and semi-structured data.
Snowflake's architecture is designed to handle complex queries and data processing at high speeds. It uses a combination of columnar storage, vectorization, and parallel processing to deliver fast query performance.
One of the key benefits of Snowflake is that it separates storage and computing, which allows users to pay only for the resources they use. Additionally, Snowflake has a number of built-in features that make it easy to manage data and perform analytics, including support for SQL queries, machine learning, and data sharing.

How Does Snowflake Works?
Snowflake has 4 main components - Storage, Compute, Query, and Data access.
Storage in Snowflake
Snowflake uses cloud storage providers like Amazon S3, Microsoft Azure Blob Storage, and Google Cloud Storage to store data and adds its own proprietary storage layer on top of it that is optimized for cloud-based data warehousing.
The data is stored in micro-partitions, which are small, self-contained units of data that can be accessed and processed independently. This allows Snowflake to achieve high levels of concurrency and performance. Snowflake automatically manages data compression, encryption, and replication, so you don't have to worry about these details.
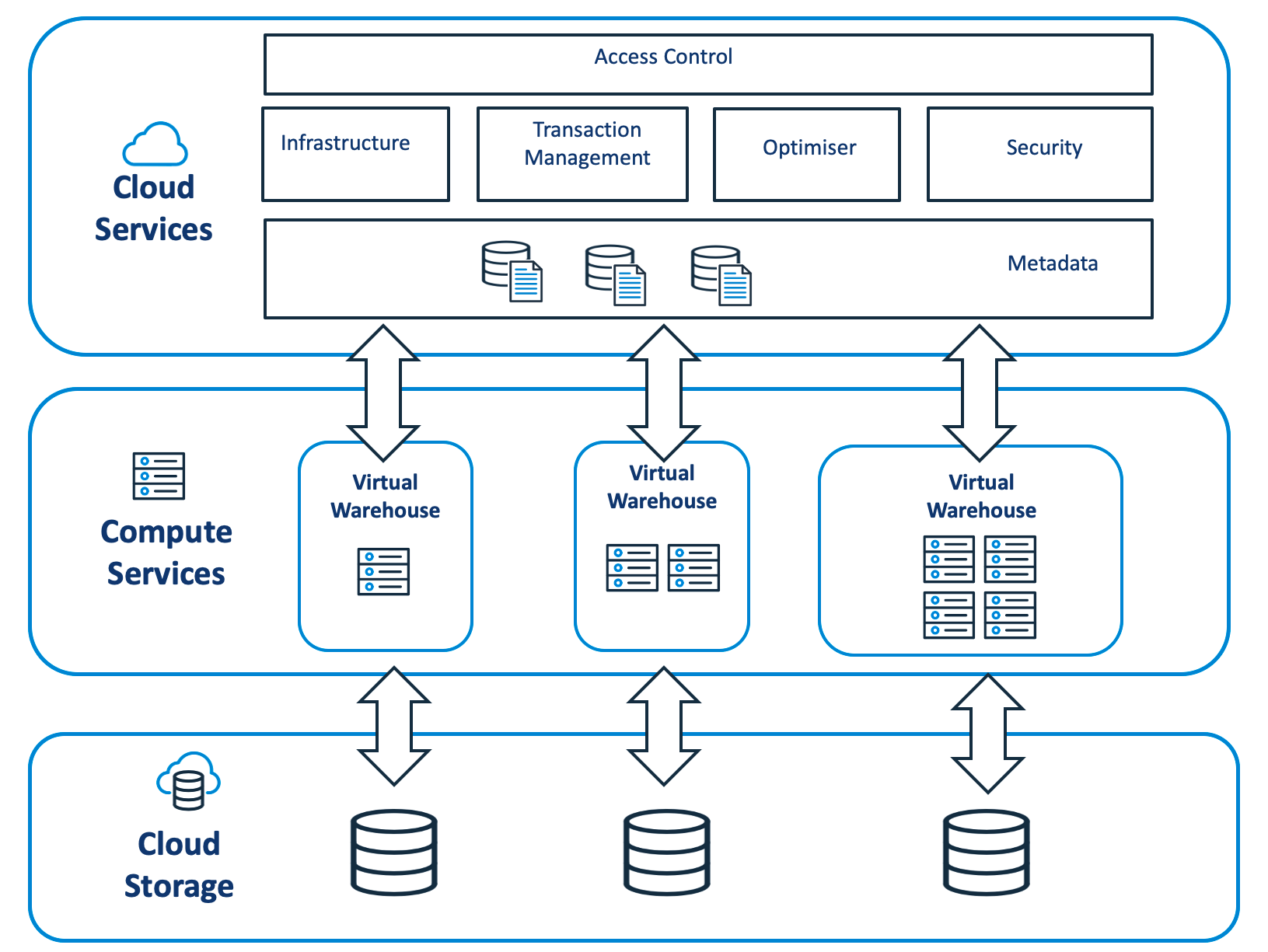
Query Processing in Snowflake
Snowflake supports standard SQL for querying data. When you submit a query, Snowflake's query optimizer evaluates the query and determines the most efficient way to execute it. Snowflake can also automatically optimize queries based on the underlying data and workload.
Compute in Snowflake
Snowflake's compute layer consists of virtual warehouses, which are clusters of compute resources that can be scaled up or down depending on the workload. When you submit a query to Snowflake, it automatically spins up a virtual warehouse and assigns compute resources to execute the query.
Accessing Snowflake Data
Users can access Snowflake data using a variety of tools, including SQL clients, BI tools, and programming languages. Snowflake provides connectors for popular data integration tools, such as Apache Kafka, Apache Spark, and Talend, to simplify data loading and extraction. Snowflake also provides a web-based user interface that allows users to interact with the platform and manage their data.
The Reproducibility Challenge when using Snowflake
When working with complex data pipelines in Snowflake, or mutable data that changes over time, one of the biggest challenges is to track the lineage between the model and the data used to train it.
While Snowflake offers some versioning capabilities, such as the Time Travel feature, it has some limitations. For example, the community tier enables traveling back up to 1 day, while the enterprise edition only goes up to 90 days.
Additionally, queries may become not reproducible due to differences in query syntax or settings. For instance, the same query may produce different results if run with different SQL dialects or optimization settings.
Furthermore, queries may also become not reproducible if there are changes made to the underlying code or database schema. If the code or schema changes, the same query may not produce the same results even if run on the same data.
All these means that not all queries are reproducible, and it's not enough to simply version the query itself.
How to overcome the reproducibility challenge when using Snowflake?
There are some techniques that can help overcome the challenges mentioned above, and achieve reproducibility to a certain extent.
Lightweight and Limited Approach
One approach is to version the query and metadata provided by Snowflake, such as where the data was extracted from. This allows you to know what data was used to train the model.
However, this approach has some limitations. For example, if the data is mutable, it might change over time, making it impossible to reproduce the exact data used to train the model. Additionally, you may need to build a custom data loader that doesn’t use the Snowflake API, but rather loads the data directly from the bucket. This can introduce additional processing steps, as the data may not be in the same format as queried from Snowflake (such as CSV versus Parquet). Lastly, you need to also make sure to use the same data warehouse settings and schema.
Despite these challenges, the lightweight approach has some advantages, such as not requiring using new MLOps tools, and not needing to set up another storage for the versioned data.
Heavy and Fully Reproducible Approach
Another approach is to version not only the query and metadata but also the query output. This allows you to achieve full reproducibility, for any data-related aspect.
One way to accomplish this is by using a tool like DVC, which can version the data efficiently and is based on Git which means we can keep using the good old GitOps workflow. While, this approach is “heavier”, as it requires additional tools and storage, it is fully reproducible.
If you're interested in achieving full data reproducibility when using Snowflake and learning about this approach of versioning, you can check out this blog post by Yichen that dives into the technical details.
Conclusion
Cloud-based data warehousing solutions like Snowflake offer organizations a cost-effective, scalable, and high-performance way to manage large amounts of structured and semi-structured data. With Snowflake's separation of storage and computing, support for standard SQL queries, and virtual warehouses, users can easily and efficiently manage their data and perform analytics.
However, reproducibility challenges can arise when working with complex data pipelines or mutable data that changes over time. While there are techniques to achieve reproducibility to a certain extent, such as versioning queries and metadata, organizations need to carefully consider their data management and MLOps strategies to overcome these challenges and ensure that their models are reproducible and reliable.



