YOLOv6: next generation object detection - review and comparison
- Nir Barazida
- 6 min read
- 4 years ago
MLOps Team Lead @ DagsHub
The field of computer vision has rapidly evolved in recent years and achieved results that seemed like science fiction a few years back. From analyzing X-ray images and diagnosing patients to (semi-)autonomous cars, we're witnessing a revolution in the making. These breakthroughs have many causes – building better, more accessible compute resources, but also the fact that they are the closest thing we have to Open Source Data Science (OSDS). Revealing the source code to the community unlocks the "wisdom of the crowd" and enables innovation and problem-solving at scale.
One of the most popular OS projects in computer vision is YOLO (You Only Look Once). YOLO is an efficient real-time object detection algorithm, first described in the seminal 2015 paper by Joseph Redmon et al. YOLO divides an image into a grid system, and each grid detects objects within itself. It can be used for real-time inference and require very few computational resources.
Today, 7 years after the first version of YOLO was released, the research group at Meituan published the new YOLOv6 model - and it's here to kick a**!
The History of YOLO
Object detection before YOLO
Before YOLO, the two-stage object detection architecture dominated the field. It used region-based classifiers to locate areas and then pass them to a more robust classifier. While this method gives accurate results, with a high mean Average Precision (mAP), it is very resource-intensive, requiring many iterations in its operation.
How does YOLO work?
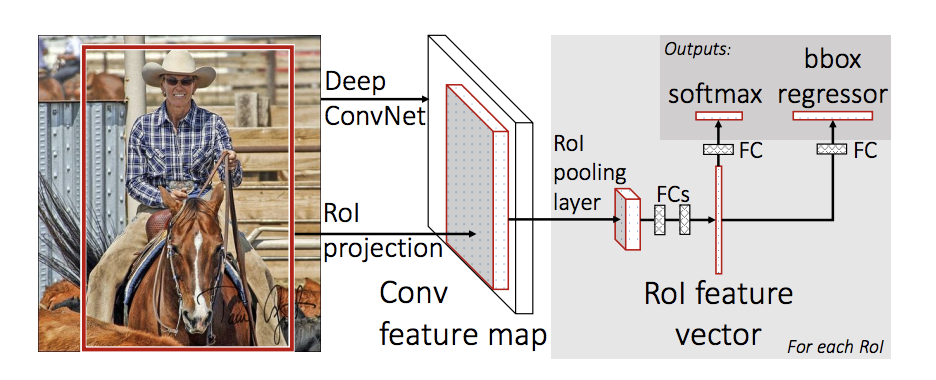
YOLO suggested a different methodology where both stages are conducted in the same neural network. First, the image is divided into cells, each having an equal dimensional region of SxS. Then, each cell detects and locates the objects it contains with bounding box coordinates (relative to its coordinates) with the object label and probability of the thing being present in the cell.
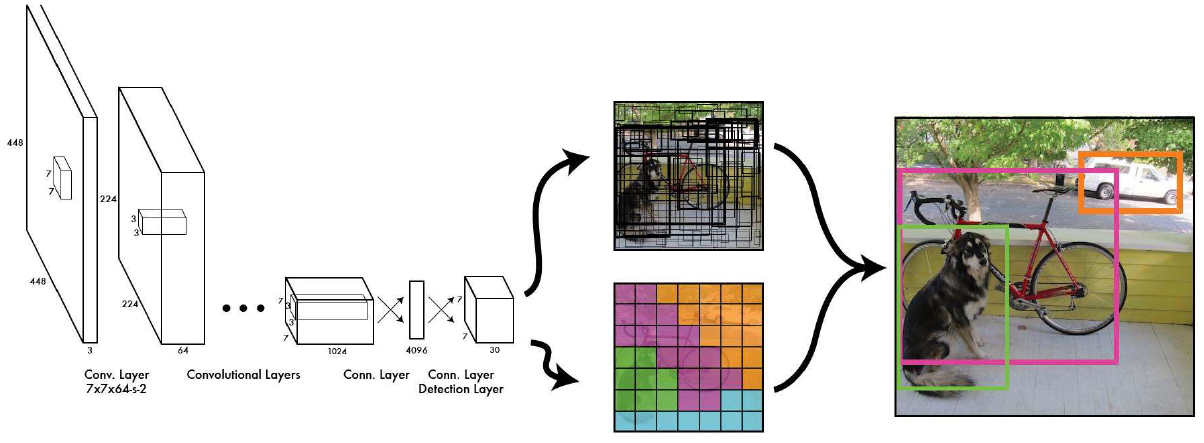
Because each cell "works on its own" it can process the grid simultaneously and reduces the required computing powers and time needed to train and infer. In fact, YOLO achieves state-of-the-art results, beating other real-time object detection algorithms.
What versions does YOLO have?
- YOLOv1 (Jun, 2015): You Only Look Once: Unified, Real-Time Object Detection
- YOLOv2 (Dec, 2016): YOLO9000:Better, Faster, Stronger
- YOLOv3 (Apr, 2018): YOLOv3: An Incremental Improvement
- YOLOv4 (Apr, 2020): YOLOv4: Optimal Speed and Accuracy of Object Detection
- YOLOv5 (May, 2020): Github repo (No paper was released yet)
YOLOv6 is here to kick A** and Take Names
MT-YOLOv6 was inspired by the original one-stage YOLO architecture and thus was (bravely) named YOLOv6 by its authors. Though it provides outstanding results, it's important to note that MT-YOLOv6 is not part of the official YOLO series.
YOLOv6 is a single-stage object detection framework dedicated to industrial applications, with hardware-friendly efficient design and high performance. It outperforms YOLOv5 in detection accuracy and inference speed, making it the best OS version of YOLO architecture for production applications.
YOLOv6 Achievements
- YOLOv6-nano - achieves 35.0 mAP on COCO val2017 dataset with 1242 FPS on T4 using TensorRT FP16 for bs32 inference
- YOLOv6-s - achieves 43.1 mAP on COCO val2017 dataset with 520 FPS on T4 using TensorRT FP16 for bs32 inference.
Single Image Inference
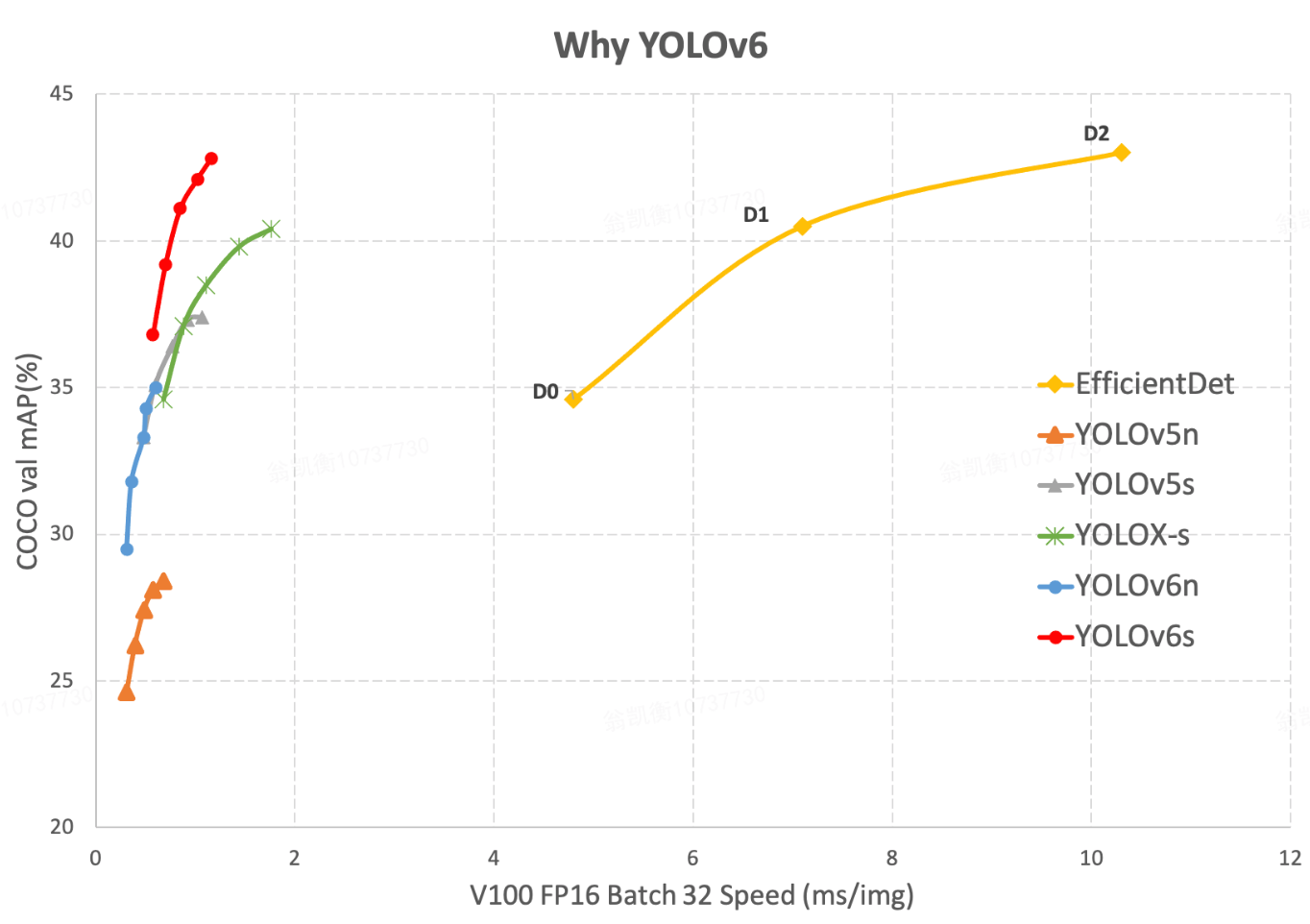
YOLOv6s (red) provide a better mean Average Precision (mAP) than all the previous versions of YOLOv5, with approximately 2x faster inference time. We can also see a huge performance gap between YOLO-based architecture and EfficientDet, which is based on two-stage object detection.
Video Inference
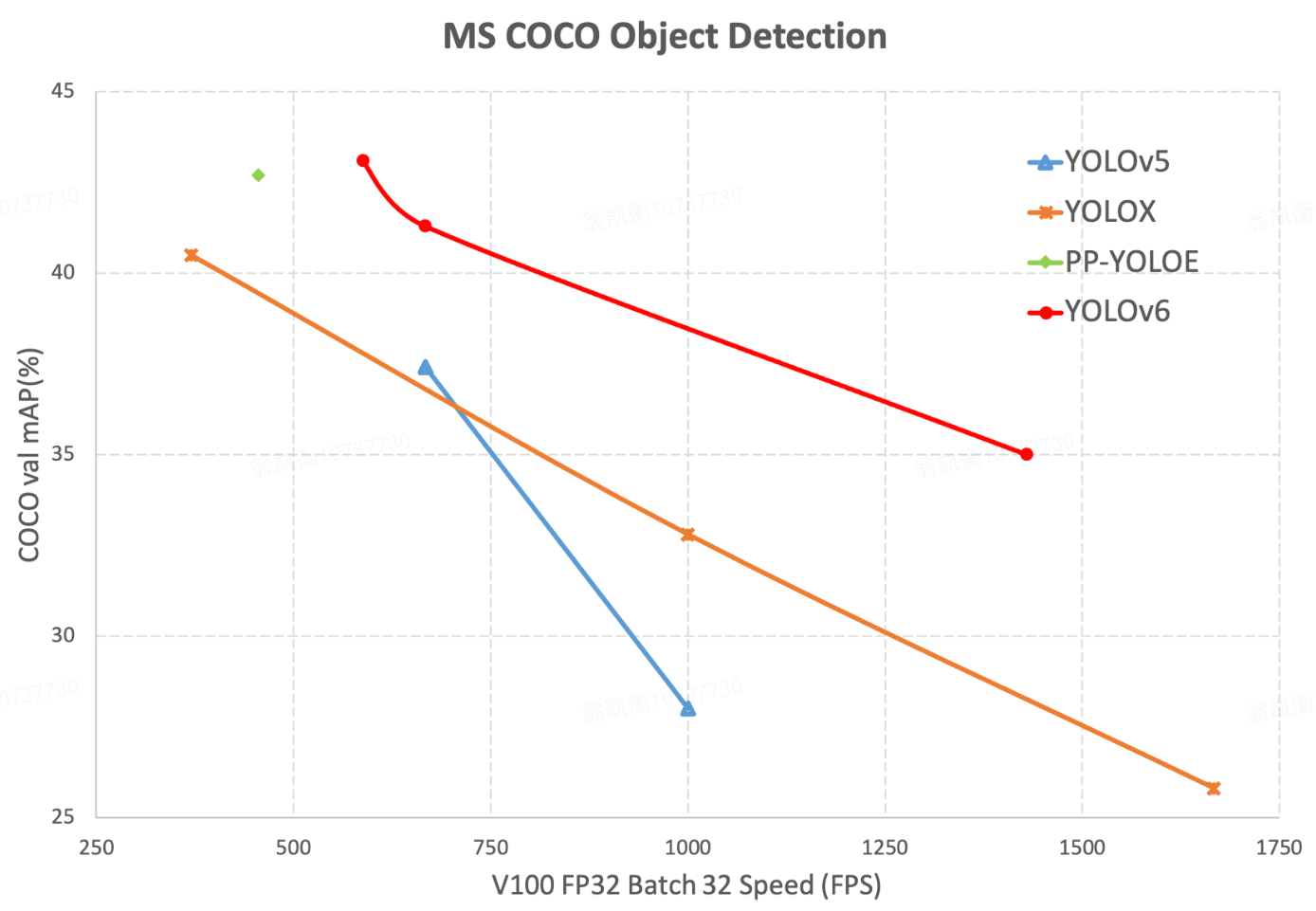
Same as in the single image inference, YOLOv6 provides better results for video on all the FPS spectrum. It’s interesting to note the change in the curve for ~550-620 FPS. I wonder if it has anything to do with hardware performance and whether or not the maintainers reduce the bias of hardware when conducting their experiments.
Benchmark
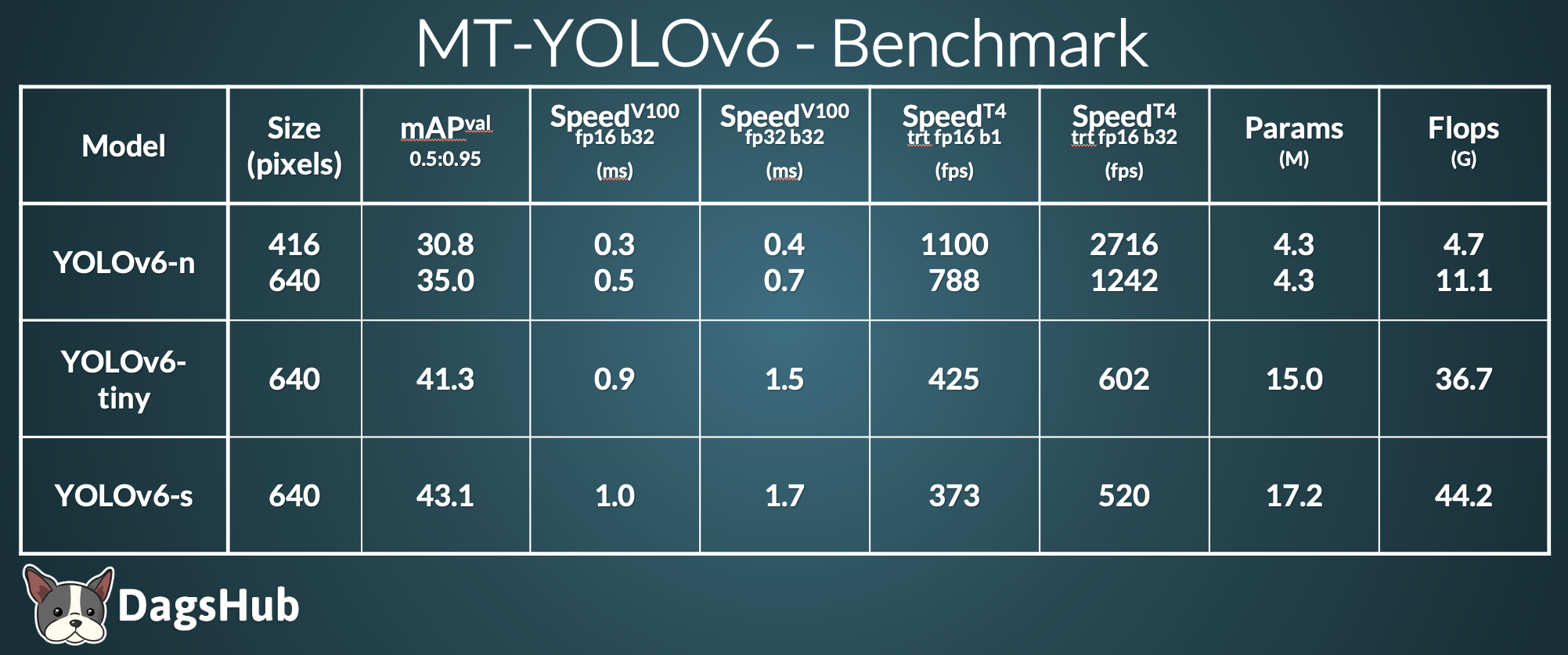
- Comparisons of the mAP and speed of different object detectors are tested on COCO val2017 dataset.
- Speed results of other methods were tested in the maintainers’ environment using the official codebase and model if not found from the corresponding official release.
Disclaimer: The above review is based on the authors’ claims, and we have yet to verify them.
YOLOv5 vs. YOLOv6
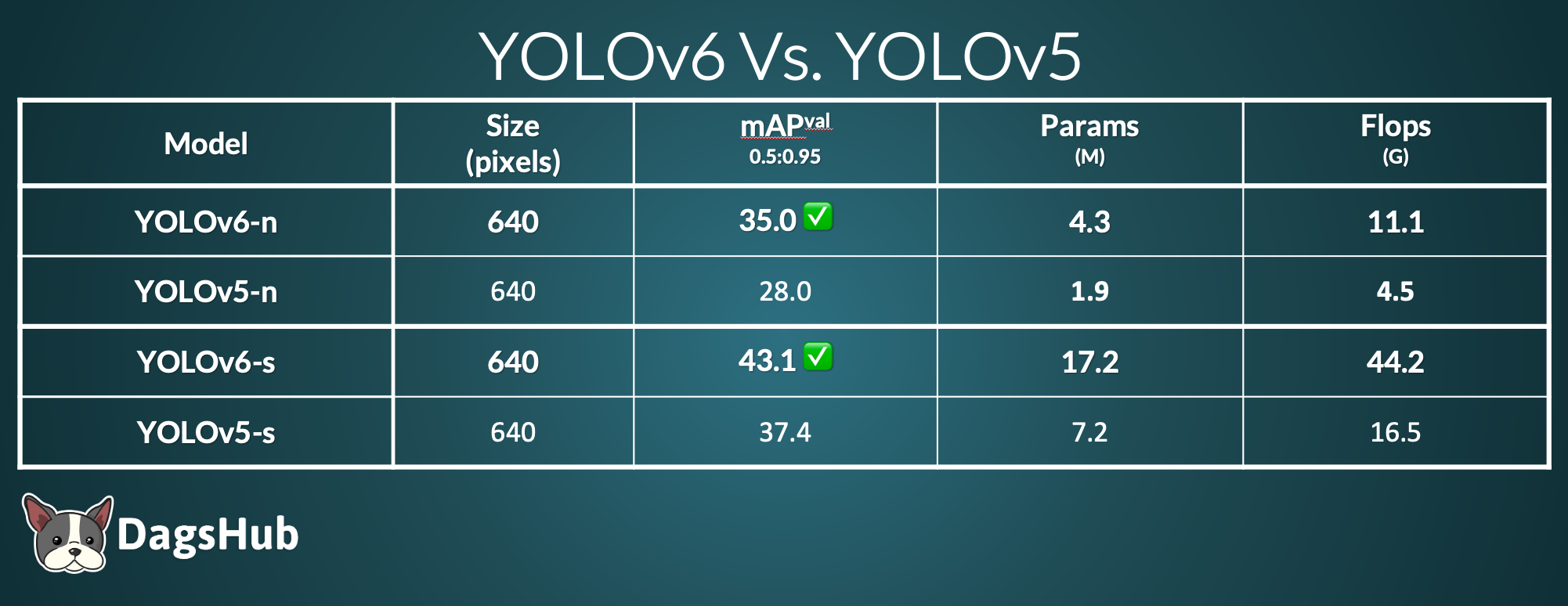
Benchmark comparison between YOLOv5 and YOLOv6
While looking into the benchmarks of both models, I found it hard to compare apples to apples. YOLOv6 has fewer types of models (lacking m/l/x) and doesn't have any information about images larger than 640 pixels. For the benchmarks both projects reported, we can clearly see the improvement in mAP for YOLOv6. However, v6 has 2x the number of parameters and Flops from v5, making me want to dive into the training process myself and double-check the results below.
Qualitative comparison between YOLOv5 and YOLOv6
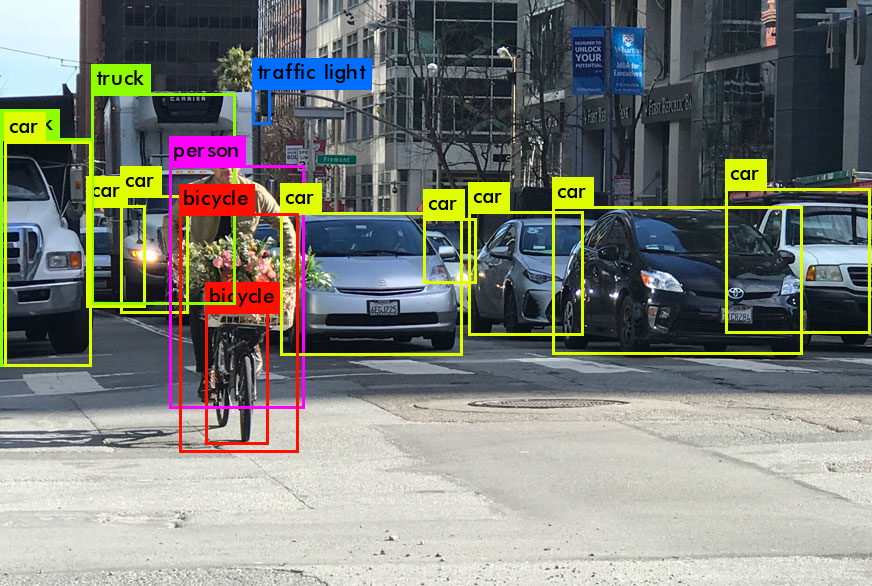
I used the s version of both models to detect objects on the following images






We can clearly see that YOLOv6s detects more objects in the image and has higher confidence about their label.
Flexibility
Both projects have similar approaches to creating different model sizes. The biggest difference is that YOLOv5 uses YAML, whereas YOLOv6 defines the model parameters directly in Python. A precursory glance also indicates that YOLOv5 might be a bit more customizable to a certain extent.
However, the fact that YOLOv6 is so flexible means that we could see larger versions of YOLOv6 in the future with even higher accuracy predictions!
If you create a larger YOLOv6 model, let us know on Discord! We’d love to see it!
Usage
You can interact with the latest version of YOLOv6 using DagsHub’s application. If you want to use it on your local machine follow these steps:
Installation
git clone https://dagshub.com/nirbarazida/YOLOv6 cd
YOLOv6 pip install -r requirements.txt
dvc pullInference
- Use YOLOv6s
python tools/infer.py --weights yolov6s.pt --source <path to image/directory>
- Use YOLOv6n
python tools/infer.py --weights yolov6n.pt --source <path to image/directory>
Conclusion
YOLOv6 is one of the most exciting OSDS projects recently released. It provides state-of-the-art results and a significant improvement on all fronts compared to previous YOLO versions. The maintainers are currently focused on enriching the types of models, deployment options, and quantization tools. Still, as with any open source project, the community can greatly impact its roadmap and progress curve.
Although the project is still in its early days, it looks very promising, and I'm intrigued to see what other benchmarks it will break in the future.



