Stable Diffusion: Best Open Source Version of DALL·E 2
- Nir Barazida
- 6 min read
- 4 years ago
MLOps Team Lead @ DagsHub

Created by the researchers and engineers from Stability AI, CompVis, and LAION, “Stable Diffusion” claims the crown from Craiyon, formerly known as DALL·E-Mini, to be the new state-of-the-art, text-to-image, open-source model.
Although generating images from text already feels like ancient technology, Stable Diffusion manages to bring innovation to the table, which is even more surprising given that it's an open-source project.
Let's dive into the details, and check what Stable Diffusion has in store for the data science community!
Introducing Stable Diffusion
Stable Diffusion is an open source implementation of the Latent Diffusion architecture, trained to denoise random gaussian noise, in a lower dimensional latent space, to get a sample of interest.
Diffusion models are trained to predict a way to slightly denoise a sample in each step, and after a few iterations, a result is obtained. Diffusion models have already been applied to a variety of generation tasks, such as image, speech, 3D shape, and graph synthesis.

Diffusion models consist of two steps:
- Forward Diffusion - Maps data to noise by gradually perturbing the input data. This is formally achieved by a simple stochastic process that starts from a data sample and iteratively generates noisier samples using a simple Gaussian diffusion kernel.This process is used only during training and not on inference.
- Parametrized Reverse - Undoes the forward diffusion and performs iterative denoising. This process represents data synthesis and is trained to generate data by converting random noise into realistic data.
The forward and reverse processes require sequential repetition of thousands of steps, injecting and reducing noise, which makes the whole process slow and heavy on computational resources.
To enable training on limited resources while retaining its quality and flexibility, the creators of Stable Diffusion adopted the method suggested in the paper. Instead of using the actual pixel space, they applied the diffusion process over a lower dimensional latent space.
For example, the autoencoder used in Stable Diffusion has a reduction factor of 8. This means that an image of shape(3, 512, 512)becomes(3, 64, 64)in latent space, which requires8 × 8 = 64times less memory.
official “Stable Diffusion” release notes
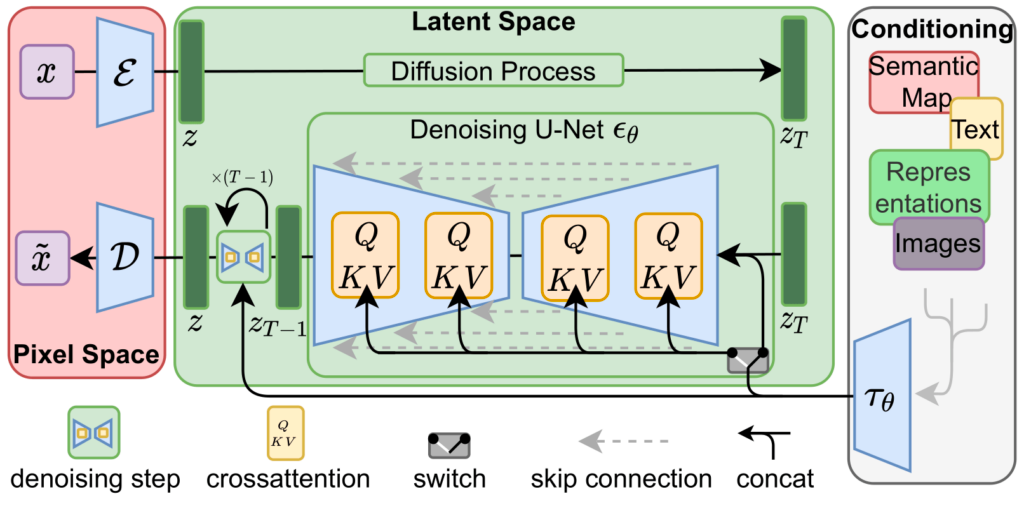
Stable Diffusion Architecture
The Stable Diffusion architecture has three main components, two for reducing the sample to a lower dimensional latent space and then denoising random gaussian noise, and one for text processing.
1) The Autoencoder: The input of the model is a random noise of the size of the desired output. It will first reduce the sample to a lower dimensional latent space. For that, the authors used the VAE Architecture, which consists of two parts - encoder and decoder. The encoder is used during training to convert the sample into a lower latent representation and passes it as input to the next block. On inference, the denoised, generated samples undergo reverse diffusion and are transformed back to their original dimensional latent space.
2) U-Net: The U-Net block, comprised of ResNet, receives the noisy sample in a lower latency space, compresses it, and then decodes it back with less noise. The estimated noise residual from the U-Net output is used to construct the expected denoised sample representation.
3) Text Encoder: The text encoder is responsible for the text processing, transforming the prompt into an embedding space. Similar to Google's Imagen, Stable Diffusion uses a frozen CLIP ViT-L/14 Text Encoder.
Technical details
Stable Diffusion v1 was pre-trained on 256x256 images and then fine-tuned on 512x512 images, all from a subset of the LAION-5B database. It uses a downsampling-factor 8 autoencoder with an 860M UNet and CLIP ViT-L/14 text encoder for the diffusion model. Stable Diffusion is relatively lightweight and runs on a GPU with 10GB VRAM, and even less when using float16 precision instead of the default float32.
The team has currently published the following checkpoints:
sd-v1-1.ckpt: 237k steps at resolution256x256on laion2B-en. 194k steps at resolution512x512on laion-high-resolution (170M examples from LAION-5B with resolution>= 1024x1024).sd-v1-2.ckpt: Resumed fromsd-v1-1.ckpt. 515k steps at resolution512x512on laion-aesthetics v2 5+ (a subset of laion2B-en with estimated aesthetics score> 5.0, and additionally filtered to images with an original size>= 512x512, and an estimated watermark probability< 0.5. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using the LAION-Aesthetics Predictor V2).sd-v1-3.ckpt: Resumed fromsd-v1-2.ckpt. 195k steps at resolution512x512on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.sd-v1-4.ckpt: Resumed fromsd-v1-2.ckpt. 225k steps at resolution512x512on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.
Model Performance
To assess the quality of images created by generative models, it is common to use the Fréchet inception distance (FID) metric. In a nutshell, FID calculates the distance between the feature vectors of real images and generated images. ****On the COCO benchmark, Imagen currently achieved the best (lowest) zero-shot FID score of 7.27, outperforming DALL·E 2 with a 10.39 FID score.
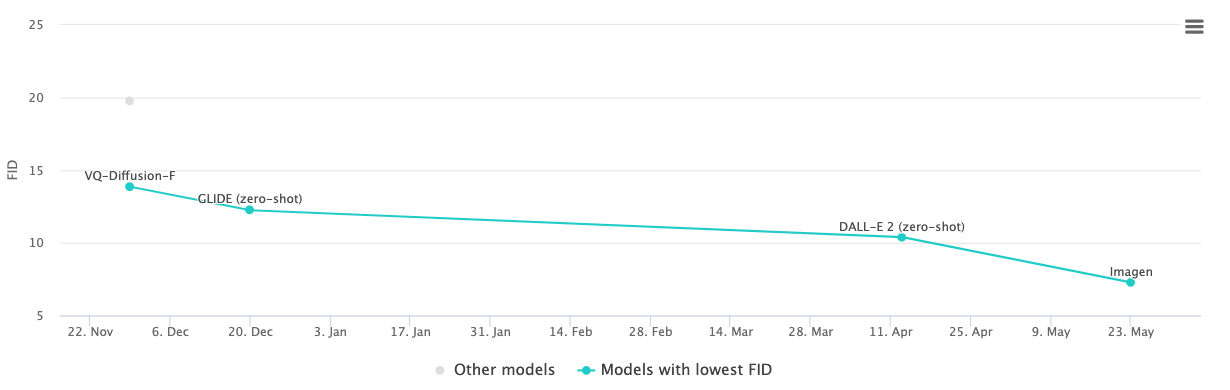
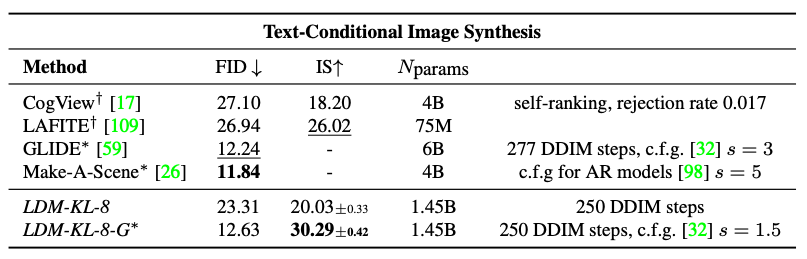
The Stable Diffusion team hasn’t published any benchmark scores to enable comparison to other models. From the original Latent Diffusion paper (see below), the Latent Diffusion Model (LDM) has reached a 12.63 FID score using the 56 × 256-sized MS-COCO dataset: with 250 DDIM steps.
The best part of text-to-image models is that we can easily qualitatively assess the model's performances. Let's see how Stable Diffusion performs compare to SOTA close source model, DALL·E 2.
Stable Diffusion vs DALL·E 2
Boston Terrier with a mermaid tail, at the bottom of the ocean, dramatic, digital art.


A Boston Terrier jedi holding a dark green lightsaber, photorealistic


I can't help but marvel at the results these models produce, it is absolutely mind-blowing. The future is here!
From the results it can be seen that DALL·E-2 manages to understand and produce images that are more suitable to the prompt, while Stable Diffusion struggles. For example, the dog is standing on a fish instead of having a tail. However, the quality of the image, color, lighting, and style, are nothing less than impressive.
Stable Diffusion vs Craiyon (DALL·E Mini)
But as good data scientists, we’d like to compare apples to apples. Let’s compare Stable Diffusion to an Open Source project, Craiyon.
Nerdy boston terrier with glasses behind computer writing code anime style


As we can immediately see, Stable Diffusion produces much more realistic images while Craiyon struggles to shape the dog’s face.
The Controversial Side of Stable Diffusion
Stable Diffusion has generated a lot of debate in its short time of existence. Unlike DALL·E 2, Stable Diffusion has very few constraints on the content it can generate. Upon its release, users tested its limitations, generating images of people by name, pornographic images, and ones that suspiciously resemble works by artists who did not consent to the use of their materials.

All these have generated a lot of discussions on Twitter and Reddit, where people called to stop the project due to safety issues. As for writing this blog, Twitter decided to block the project account, and the model hosted on HugginFace Space was restricted on the content it can generate, named “Safety Classifier” which is intended to remove NSFW images.
Conclusion
Stable Diffusion is one of the most exciting OSDS projects recently released. It provides state-of-the-art results and a significant improvement on all fronts compared to previous OS text-to-image models.



