Launching DagsHub 2.0
- Dean Pleban
- 8 min read
- 5 years ago
Co-Founder & CEO of DAGsHub. Building the home for data science collaboration. Interested in machine learning, physics and philosophy. Join https://DAGsHub.com | DagsHub Co-Founder & CEO

This is an exciting day for us at DagsHub. We’re updating DagsHub with amazing new capabilities, enabling you to close the data loop efficiently, zero DevOps required, as well as upgrading the data teamwork experience!
We’re launching many awesome things like a new homepage, support for additional data types, and larger datasets, but today, I’d like to focus on two new major features – Labeling and Discussions.
TL;DR – You can now annotate data on DagsHub and have discussions on any file on the platform. It's really easy to get started. If you just want to get your hands dirty with labeling, check out our tutorial, or try out the example project.
A mission we’ve always been on
DagsHub has always been about making data science teamwork, and especially community collaboration, possible, easy, and fun.
By enabling data scientists and machine learning engineers to work together on open-source data science projects we are setting a high bar for collaborative data tools – If 2 data developers from opposite sides of the globe can work together towards the same goal, especially if they didn’t know each other before, then any team will collaborate more effectively with DagsHub.
We’re already seeing huge international teams manage their projects on DagsHub, splitting tasks and reviewing colleagues’ work efficiently. By using DagsHub, they are taking advantage of best practices and workflows to get data science projects to production 10x faster and at scale.
Closing the data loop with DagsHub 2.0
The idea of the data loop or machine learning loop has been circulating for a while. The idea is to have a closed-loop data system that does the following:
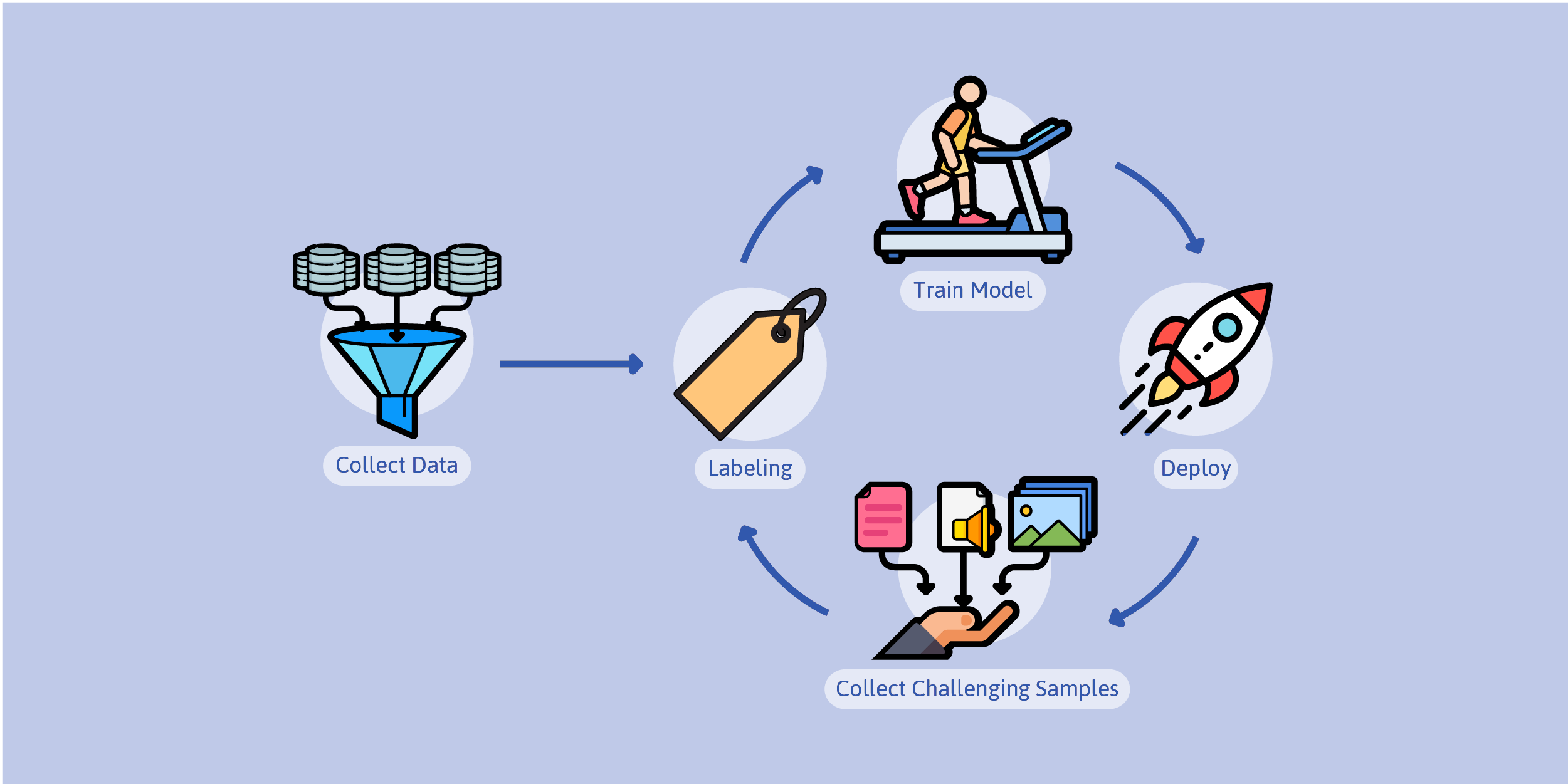
- Collect data
- Label data
- Use the data to train a model
- Deploy the model
- Collect additional data samples (usually challenging samples - hard sample mining)
- Add the new samples to the dataset (to be labeled), starting the cycle again.
In the context of Data Centric AI, this is a great way to continually improve your model performance (it’s sometimes called continual learning, lifelong learning, or human-in-the-loop learning).
Many teams we’ve spoken with about this process, say that even though it’s easy to explain, implementing it is an enormous challenge. We’ve written about recurring challenges that come up when collecting data and throughout the labeling process, but here is a summary:
A. It’s unclear how to connect labeling to the rest of the loop and how to version labels as they evolve
Even though many tools help you annotate your data, most teams find it hard to connect that stage (2), to data collection (1) and modeling (3). They have to move data to third-party platforms, synchronize annotations with the training data, and do a lot of DevOps heavy lifting to set everything up. Reinventing this wheel is especially hard since the process involves multiple stakeholders with different backgrounds and technical proficiencies (data engineers, data scientists, MLEs, annotators, and domain experts).
B. The last part of the loop is mostly unsolved
Teams that have successfully created a solution for steps 1-4 of the loop find it hard to build out the last two steps – collecting additional data and feeding them back into the dataset. Even if the entire cycle from data to deployed model is automated, collecting new data and getting it through to the point where you have a better model deployed is mostly manual if it even exists.
C. It’s hard to build context throughout the loop
Information about data projects is spread over many systems and tools – Slack, experiment tracking, code repositories, and even your labeling tool. This causes knowledge to fall through the cracks, making handoffs and reviews challenging, debugging a frustrating process, and the collaborative process slow and inefficient.
Introducing DagsHub Annotations
Our approach at DagsHub is to take awesome, popular, open-source tools, and connect them to the platform in a seamless way. Lowering the barrier for entry by doing the DevOps work for you while providing a coherent workflow that makes sense for production-oriented teams and our open-source community.
We’ve done it with Git (GitHub, GitLab & others), DVC, MLflow, and Jenkins, and today, I’m happy to announce that Label Studio is joining the DagsHub toolbox.
Label Studio is already used by thousands of teams to label images, text, audio, time series, video, and structured data. It provides an easy-to-use and intuitive UI for annotating data, and of course, it’s completely open-source.

DagsHub added value
At the basic level, this integration is already providing some awesome capabilities:
1. Zero DevOps Labeling – Using Label Studio locally is one thing, but when you want a central annotation tool for your team, hosting it becomes a challenge. With DagsHub Annotations, just go to your Annotations tab, create a new annotations project and get a built-in Label Studio instance fired up and ready to go.
2. Team Access Controls – Now that you have a central labeling platform, you want to add teammates to help you out. Some might annotate, some might only need viewing access, and others will be reviewers. DagsHub makes it easy to set permissions for everyone in your team. Seeing which team member annotated each data point is also easily built-in.
But we didn’t stop there. We created an amazing set of new (and exclusive) features that define a workflow for connecting the raw data into DagsHub Annotations, connecting the labeled data into the training step, and closing the data loop.
3. Sync Data Versions from your Git or DVC Remote – When you create a new DagsHub Annotations project, you will go through a wizard to select which data from your repository you’d like to label, the samples will then automatically be connected to Label Studio so you can start annotation. This means that:
- After pushing a data version to DagsHub you don’t need to do anything else to label it – connecting between data collection (1) and labeling (2) is solved.
- DagsHub annotations are version-specific! If your data changes and you want to label a specific version, you can create multiple labeling projects per repo, so you can manage the annotation process with a Git-like flow.
4. Commit Annotation to DagsHub – Annotations change over time and new data is added. Most teams use “stone-age” versioning to manage the changing annotation versions (labels_v1.json, labels_v2.json, etc). With DagsHub Annotations, they no longer have to. Every Annotations project includes a green Commit button at the top right of the screen. Once you’re ready with a version of labels, click that button to commit a version of your labels alongside your data. This means you can:
- Time Travel your Annotations – Your annotations will be saved to a dedicated
.labelstudiofolder tracked by Git, that we use to enable you to go back to an old annotation version – Just go the version you want, create a new Annotations Project from it, and the state of annotations as they were at the time will be there, ready to edit or review. - Commit an Annotations File for Training – You can export your annotation to any one of the many supported file types such as
JSON,CSV,TSV,COCO,YOLO, and many more! Once you’ve finished annotating your data, you can already start modeling and experimenting, with no delays. Justgit + dvc pull(orfds pull) your project, and you’re ready to go. This covers connecting the labeling step (2) and the training step (3).

So we’ve seen how DagsHub solves the problem of connecting labeling to the rest of the loop (A). How about the other two?
Actually closing the loop
All of these capabilities, alongside our Jenkins integration (or connecting DagsHub with your favorite automation tool), mean you can also easily close the data loop (B) just by collecting new data samples you want to add to your training dataset.
Simply update the dataset with the data you collected, and push the updated dataset to DagsHub with DVC. Once it’s on the platform, open your labeling project, label the new data, and commit. Some of our community members demonstrated how to automate training when data is updated – Creating CML (continuous machine learning) with Jenkins. You get an updated model with performance metrics tracked in your DagsHub experiments tab. Decide whether to deploy the new model or not and the loop is complete!
Introducing DagsHub Discussions to build project context
We’re still left with the problem of building context throughout the loop (C) – It’s hard to build context throughout the loop. DagsHub aims to centralize project context, so you can find everything in one place.
One thing that constantly came up speaking with our users is the need to just “write a note” on some data point, or discuss the model architecture next to the model file. It was clear that issues, which are meant for describing issues, bugs, and feature requests for a repository, weren’t good enough for this.
Commenting on anything
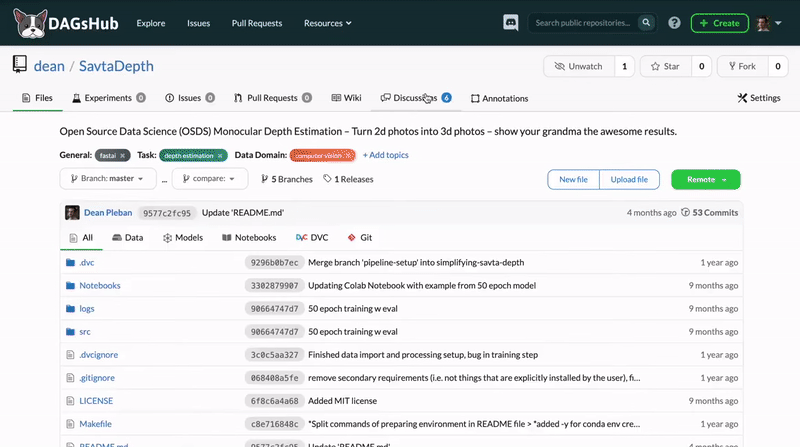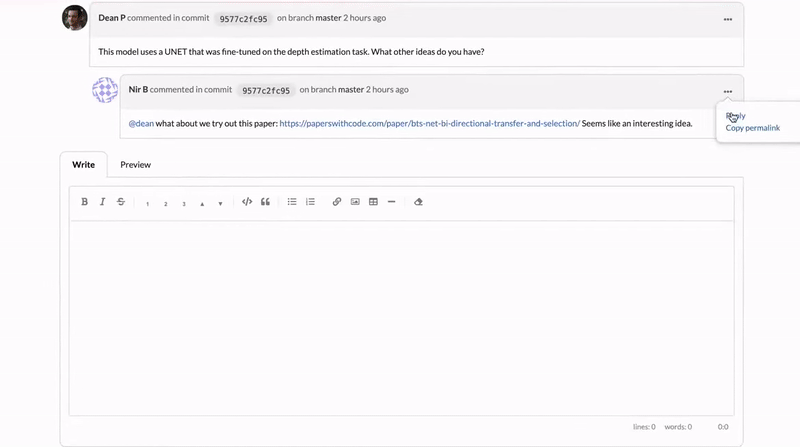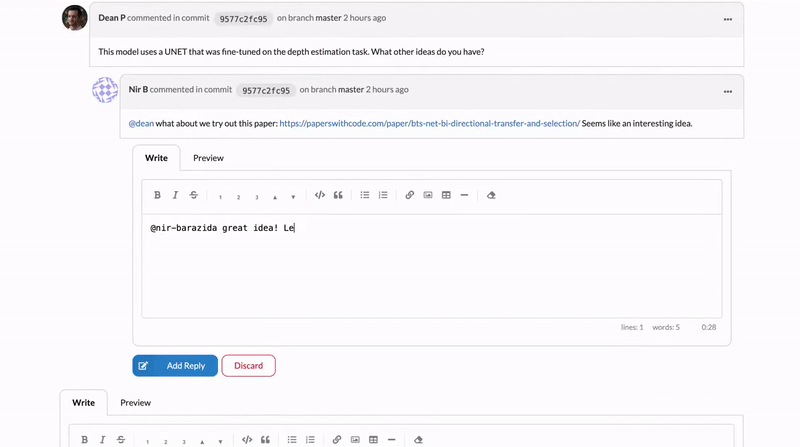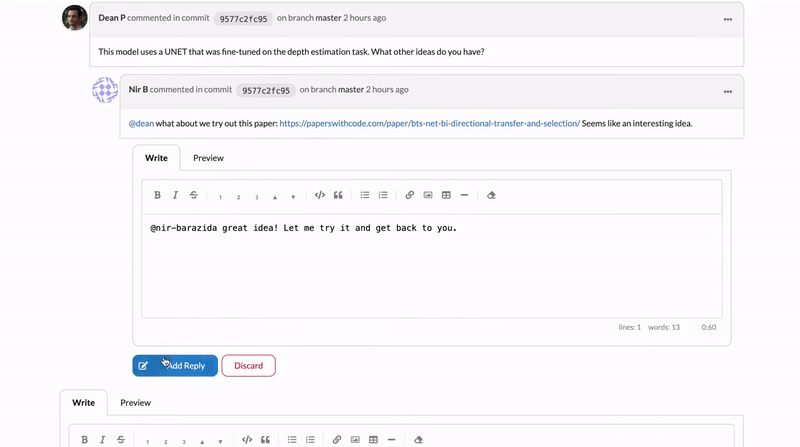
That’s why today we’re also launching DagsHub Discussions, or as we like to call them internally – “Comment-On-EVERYTHING”. You can now have a discussion on any file stored on DagsHub. You can comment on files, folders, lines of code, data files, and even on bounding boxes in images.
Discussions also appear in a central location in the discussions tab, allowing you to easily find where the interesting conversations are happening and join in.
We’ve already seen many users (in the beta) take advantage of this feature to have meaningful discussions, and we plan on making it better, with more features and the ability to comment on even more things (table cells, charts, etc.) in the future.
Building context the right way
With discussions, comments are attributed to the version they were created in, so you can also see the relationship between a discussion and the changes in a project. Tag collaborators, create an issue from a discussion, or attach an image – it’s as easy as a click.
Since all the core components of a data project are connected to DagsHub, you can have your entire project context in one place, easily building the knowledge required for faster handoffs and better decision making.
What’s next for DagsHub
DagsHub 2.0 is a quantum leap forward for data science collaboration. But we don’t want to stop here.
To make closing the loop even easier than it is, we’re going to integrate tools that make it easy to deploy models, monitor and collect challenging data samples, and add them into the dataset, using generic formats and open source tools.
We’ll double down on existing integrations, making it easier to work with the tools and platforms that we already integrate – with GitHub leading the way. We’ll add support for additional data types because we believe that data team workflows should be data-type-agnostic. Whether you’re working with tabular data, text, or medical imaging, we believe you deserve a first-class collaborative experience.
As always, we’d love to get your feedback. Feel free to reach out to us via our Discord channel, where our team is waiting to answer your questions, help out in any way, or just talk about data, machine learning, and the secrets of the universe.



