Getting Started With DVC
- Eugenia Anello
- 6 min read
- 3 years ago
Data Scientist at CRIF and a Technical Writer on Towards Data Science.

Learn about DVC, the open-source command line tool to version data and models, the same way Git versions code files.
Managing data, code, and models can be a challenging and time-consuming task for data scientists. Handling file versions manually becomes inefficient, necessitating the use of external tools for simplified management. While Git is useful for code versioning, it falls short for machine learning projects that require versioning of data and models.
As a fast and intuitive choice, you would choose Git LFS for this task. However, in the long term, it may not be the best decision, since it has some undeniable limitations. Git LFS doesn’t handle really large files gracefully, it doesn’t have pipeline support, and only supports a unique Git LFS remote server, while in most cases we’d prefer to work with our favorite cloud storage, like Google Cloud Storage, Amazon S3 or Azure Blob Storage.
Enter DVC (Data Version Control), an open-source tool designed to address these limitations. Acting as an extension to Git, DVC specializes in versioning large files and data pipelines. In this blog post, we will explore why DVC is essential, examine its differences from Git, and provide a step-by-step guide on how to utilize DVC effectively.
Feel free to take a look at the project to follow the tutorial better
Table of contents:
- What is DVC and why do we need it?
- Workflow of DVC and Git
- How DVC works under the hood
- DVC basic commands
What is DVC and why do we need it?
DVC stands for Data Version Control. It is an open-source version control system specifically designed for managing data and machine learning models in projects. While traditional version control systems like Git are great for tracking code changes, they are not well-suited for handling large datasets and models that are essential components of machine learning projects. DVC aims to fill this gap by providing a dedicated solution for versioning and managing data and models. It's designed to works as an extension to Git, doesn't require us to change any of our current tooling and workflows to adapt it.
Here's why DVC is valuable in machine learning projects:
- Data versioning: DVC allows you to track and version your datasets efficiently. Large datasets can be stored externally and accessed through references, reducing the storage space required for version control. With DVC, you can easily switch between different versions of datasets, share them with collaborators, and reproduce previous experiments.
- Reproducibility: Reproducibility is a crucial aspect of machine learning research. DVC helps ensure that the exact data and models used in a particular experiment are preserved and can be replicated. By tracking dependencies between code, data, and models, DVC allows you to create reproducible machine learning pipelines.
- Collaboration: DVC facilitates collaboration among team members. It provides a unified interface for sharing and managing data, models, and code. With DVC, multiple researchers or data scientists can work on the same project, track changes, and merge their work seamlessly.
- Efficient storage and handling of large files: DVC uses Git to handle metadata and versioning, while the actual data files and models are stored outside of the Git repository. This approach allows you to efficiently manage large files without bloating your Git history.
How to version files with DVC and Git?
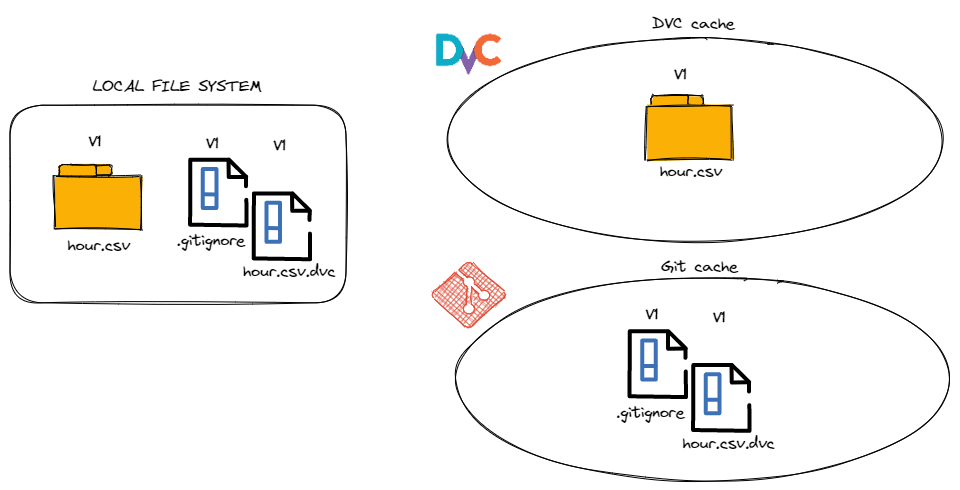
As we have seen, Git and DVC are two complementary tools: Git for versioning code and DVC for versioning data and models. Moreover, DVC relies on Git for managing the versions of data. To understand how they work together, let’s begin with a simple example.
Let’s suppose that we want to track the version of our raw data. Due to its large size, we'll use DVC to version it by running the following command:
dvc add data/raw/hour.csvBy running this command, three actions occur:
- The original
data/raw/hour.csvfile is moved to the hidden DVC cache directory and is replaced with a unique link to the file hosted in the DVC cache. - A pointer named
<file-name>.dvcis created. This file contains the path of the original file, its size, and an md5 hash. This hash is the name of the file DVC moved to its cache directory. Using this unique name, DVC knows how to connect a file with its specific version hosted in the cache. - Add the path to the original file to
.gitignore. This action is conducted to a avoid a situation where the file is tracked by both Git and DVC simultaneously.
The last step in the process will be to version the pointer file (data/raw/hour.csv.dvc) and the new .gitignore files with Git.
But what if a file versioned by DVC was modified?
To track a new version of a file, we can use either the dvc add or the dvc commit commands.
dvc add data/raw/hour.csv
By tracking the new version with DVC, it will create a new version of the file in the cache directory and update the information in the pointer file.

How to retrieve a data or model file versioned by DVC?
This is where DVC shines! We can retrieve a specific version of a file tracked by DVC by running two commands.
First, we retrieve the version of the DVC pointer file, tracked by Git, that points to the version of the file you want to retrieve. We can do that with various commands such as git checkout <commit-hash>.
Once that is done, all you need to do is run dvc checkout if the file was versioned locally, or dvc pull -r <remote name> if the file is hosted on a remote storage.
DVC basic commands
In this section we'll learn how to install DVC, initialize it in our project and version a file.
Set up the project
To easily follow the tutorial, you can clone a branch of my repository with just a command:
git clone --branch template https://dagshub.com/eugenia.anello/dvc-getting-started-guide.gitInstall DVC
You can install DVC using pip by running the following command:
pip install dvcor using conda:
conda install -c conda-forge mamba
mamba install -c conda-forge dvcIn the first case, it’s required to have a virtual environment, while the other case needs the installation of Anaconda or Minicoda.
Initialize DVC
Once DVC is installed, you can run the following command within the root directory of the git project:
dvc initThis command will generate a .dvc/ directory, that contains the cache location and other internal files. Some of these are:
.dvc/.gitignore- the gitignore file to hide internal files in Git.dvc/config- the DVC configuration file
After, we can commit the changes:
git commit -m "Initialize DVC"Version data with DVC
We will use the dvc add commands as shown above to version the new data file.
dvc add data/raw/hour.csvThis command will update the .gitignore file and will generate a DVC pointer file, hour.csv.dvc, that hold information about the original version of the data file. Let's see what it holds
md5: f0d1505e8213eccada8c2a02c6491dac
size: 1144480
path: hour.csvThis output confirms that dvc calculates the MD5 hash of the data, and records the size and the original path of the file.
Next we will add and commit the changes to Git:
git add data/raw/hour.csv.dvc .gitignore
git commit -m "Add raw file"In case you want to track the entire directory, you just need to specify the folder:
dvc add data/rawConclusion
DVC provides efficient versioning capabilities for data and models in machine learning projects. On top of that, DVC offers features such as data versioning, reproducibility, collaboration, and efficient storage of large files. By seamlessly integrating with Git and utilizing external storage options like Google Cloud Storage, Amazon S3, or Azure Blob Storage, DVC becomes an indispensable tool for data scientists and machine learning practitioners.
Resources:
- DVC documentation: https://dvc.org/doc/
- Data Pipeline tutorial: https://dvc.org/doc/start/data-management/data-pipelines
- DVC GitHub community: https://github.com/iterative/dvc/community



