Speech_Commands_Dataset

The dataset (1.4 GB) has 65,000 one-second long utterances of 30 short words, by thousands of different people, contributed by members of the public through the AIY website. This is a set of one-second .wav audio files, each containing a single spoken English word. These words are from a small set of commands, and are spoken by a variety of different speakers. The audio files are organized into folders based on the word they contain, and this data set is designed to help train simple machine learning models.
The similar version of dataset is uploaded to DagsHub: Speech Commands Dataset, enabling you to preview the dataset before downloading it.
History
This is version 0.01 of the data set containing 64,727 audio files, released on August 3rd 2017. [Update April 11th 2018 - This is now superceded by a new version of the dataset with more audio clips and improved label quality, available at http://download.tensorflow.org/data/speech_commands_v0.02.tar.gz. There is also now a research paper on this dataset at https://arxiv.org/abs/1804.03209.]
Collection
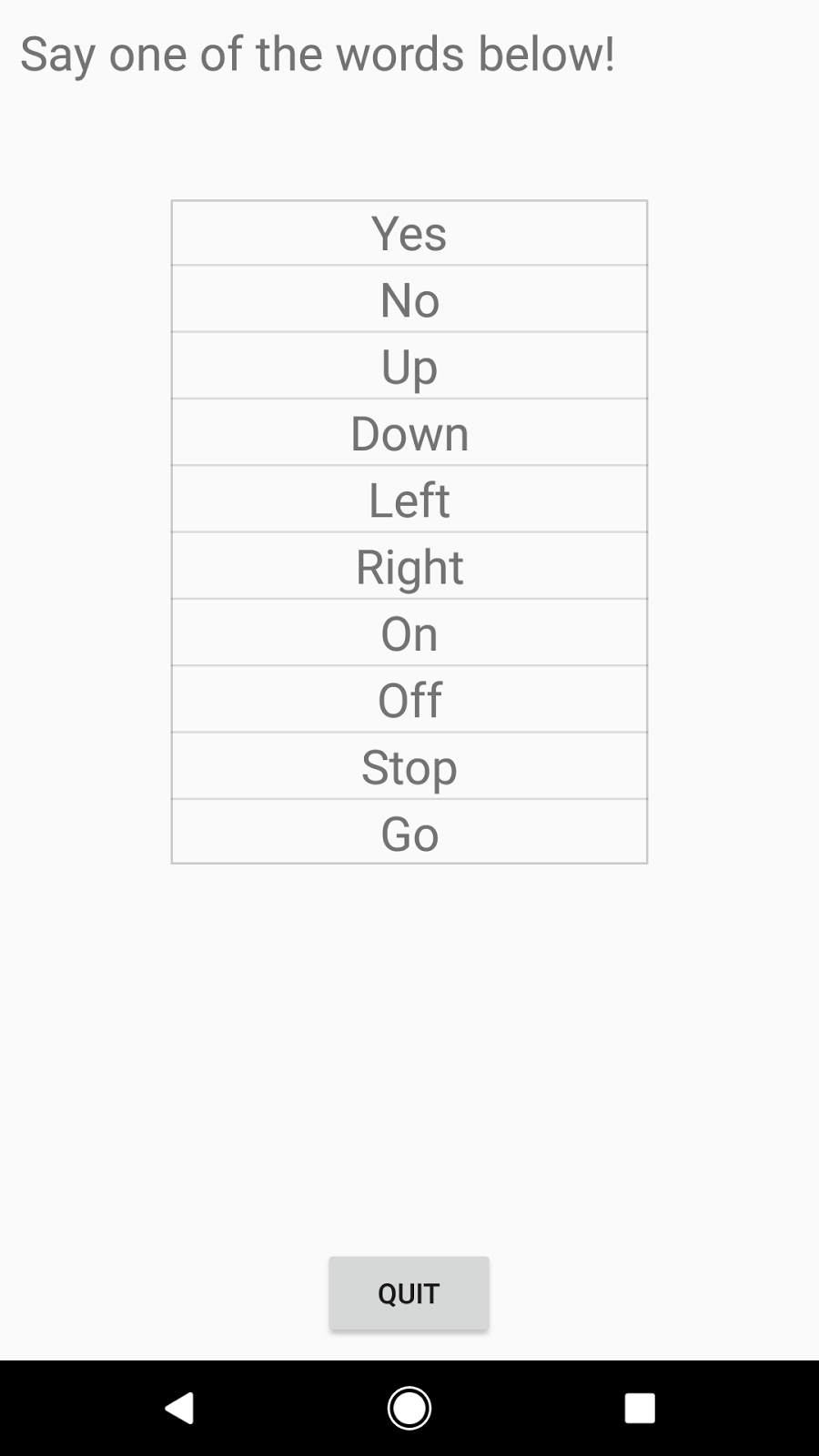
The audio files were collected using crowdsourcing, see aiyprojects.withgoogle.com/open_speech_recording for some of the open source audio collection code we used (and please consider contributing to enlarge this data set). The goal was to gather examples of people speaking single-word commands, rather than conversational sentences, so they were prompted for individual words over the course of a five minute session. Twenty core command words were recorded, with most speakers saying each of them five times. The core words are "Yes", "No", "Up", "Down", "Left",
"Right", "On", "Off", "Stop", "Go", "Zero", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", and "Nine". To help distinguish unrecognized words, there are also ten auxiliary words, which most speakers only said once. These include "Bed", "Bird", "Cat", "Dog", "Happy", "House", "Marvin", "Sheila",
"Tree", and "Wow".
The infrastructure we used to create the data has been open sourced too, and we hope to see it used by the wider community to create their own versions, especially to cover underserved languages and applications.
To try it out for yourself, download the prebuilt set of the TensorFlow Android demo applications and open up “TF Speech”. You’ll be asked for permission to access your microphone, and then see a list of ten words, each of which should light up as you say them.

The results will depend on whether your speech patterns are covered by the dataset, so it may not be perfect — commercial speech recognition systems are a lot more complex than this teaching example. But we’re hoping that as more accents and variations are added to the dataset, and as the community contributes improved models to TensorFlow, we’ll continue to see improvements and extensions.
Organization
The files are organized into folders and subfolders. Main folders contans sub groups with each directory name labelling the word that is spoken in all the contained audio files. No details were kept of any of the participants age, gender, or location, and random ids were assigned to each individual. These ids are stable though, and encoded in each file name as the first part before the underscore. If a participant contributed multiple utterances of the same word, these are distinguished by the number at the end of the file name. For example, the file path Miscellaneous/happy/3cfc6b3a_nohash_2.wav indicates that the word spoken was "happy", the speaker's id was "3cfc6b3a", and this is the third utterance of that word by this speaker in the data set. The 'nohash' section is to ensure that all the utterances by a single speaker are sorted into the same training partition, to keep very similar repetitions from giving unrealistically optimistic evaluation scores.
<root directory>
|
.- README.md
|
.- Animals/
|
.- Miscellaneous/
|
.- Number/
|
.- People/
|
.- Simple Commands/
|
.- bed/
|
.- down/
|
.- go/
|
.- left/
|
.- no/
|
.- off/
|
.- on/
|
.- right/
|
.- stop/
|
.- three/
|
.- up/
|
.- yes/
|
.- 1eddce1d_nohash_1.wav
|
.- 9a7c1f83_nohash_3.wav
|
...
- Folder Labels:
- Animals
- Miscellaneous
- _background_noise_
- happy
- house
- wow
- Number
- one
- two
- three
- four
- five
- six
- seven
- eight
- nine
- zero
- People
- Simple Commands
- bed
- down
- go
- left
- no
- off
- on
- right
- stop
- tree
- up
- yes
Processing
The original audio files were collected in uncontrolled locations by people around the world. We requested that they do the recording in a closed room for privacy reasons, but didn't stipulate any quality requirements. This was by design, since we wanted examples of the sort of speech data that we're likely to
encounter in consumer and robotics applications, where we don't have much control over the recording equipment or environment. The data was captured in a variety of formats, for example Ogg Vorbis encoding for the web app, and then converted to a 16-bit little-endian PCM-encoded WAVE file at a 16000 sample rate. The audio was then trimmed to a one second length to align most utterances, using the
extract_loudest_section tool. The audio files were then screened for silence or incorrect words, and arranged into folders by label.
Background Noise
To help train networks to cope with noisy environments, it can be helpful to mix in realistic background audio. The _background_noise_ folder contains a set of longer audio clips that are either recordings or mathematical simulations of noise. For more details, see the _background_noise_/README.md.
Training Model
You can also learn how to train your own version of this model through the new audio recognition tutorial on TensorFlow.org. With the latest development version of the framework and a modern desktop machine, you can download the dataset and train the model in just a few hours. You’ll also see a wide variety of options to customize the neural network for different problems, and to make different latency, size, and accuracy tradeoffs to run on different platforms.
Citations
If you use the Speech Commands dataset in your work, please cite it as: APA-style citation: "Warden P. Speech Commands: A public dataset for single-word speech recognition, 2017. Available from http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz".
BibTeX @article{speechcommands, title={Speech Commands: A public dataset for single-word speech recognition.}, author={Warden, Pete}, journal={Dataset available from http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz}, year={2017} }
License
It's licensed under the Creative Commons BY 4.0 license.
Acknowledgments
Massive thanks are due to everyone who donated recordings to this data set, We are very grateful. Also this dataset couldn't have put together without the help and support of Billy Rutledge, Rajat Monga, Raziel Alvarez, Brad Krueger, Barbara Petit, Gursheesh Kour, and all the TensorFlow and AIY teams. We also wanted to thank thousands of different people who help build dataset diverse, contributed by members of the public through the AIY website.
Pete Warden, petewarden@google.com
Original Dataset: The Speech Commands Dataset
DAGsHub Dataset: Speech_Commands_Dataset
Photo by Malte Helmhold on Unsplash
This open source contribution is part of DagsHub x Hacktoberfest



 DVC
DVC