Resources
Docs
Blog
Datasets
Glossary
Case Studies
Tutorials & Webinars
Product
Data Engine
LLMs
Platform
Enterprise
Pricing
Explore
DagsHub:main
from
idivyanshbansal:patch-1
![]()
The ability of sound to enhance human wellbeing has been known since ancient civilizations, and methods can be found today across domains of health and within a variety of cultures.
 EmoSynth is a dataset of 144 audio files which have been labelled by 40 listeners for their the perceived emotion, in regards to the dimensions of Valence and Arousal.
EmoSynth is a dataset of 144 audio files which have been labelled by 40 listeners for their the perceived emotion, in regards to the dimensions of Valence and Arousal.
The similar version of dataset is uploaded to DagsHub: EmoSynth , enabling you to preview the dataset before downloading it.
The dataset is small (106MB) and simple to navigate as it has only one folder based containing synthetic audio files. We also have an audio_labels.csv file, which contains details about the classification of audio based on the dimensions of Valence and Arousal. Each audio file is approximate 5 seconds long and 430 KB in size.
For the best experience keep your volume high to listen to the sounds.
<root directory>
|
.- README.md
|
.- meta.txt
|
.- citation.txt
|
.- audio_labels.csv
|
.- Audio-Data/
|
.- s1_a0_d1.wav
|
.- s1_a0_d2.wav
|
.- s1_a1_d1.wav
| ...
Results on the dataset show that Arousal does correlate moderately to fundamental frequency, and that the sine waveform is perceived as significantly different to square and sawtooth waveforms when evaluating perceived Arousal. The general results suggest that isolated synthetic audio can be modelled as a means of evoking affective states of emotion.
First, I would like to thank Baird, Alice and Parada-Cabaleiro, Emilia and Fraser, Cameron and Hantke, Simone and Schuller, Bjorn for publishing dataset on Zendo and explaining the results. Secondly, I would like to thank Zenodo for maintaining amazing open source dataset.
Alice Baird; Emilia Parada-Cabaleiro, Aug 20, 2019
Original Dataset: EmoSynth| Zenodo
DAGsHub Dataset: kingabzpro/EmoSynth
Photo by Jonathan Borba on Unsplash
This open source contribution is part of DagsHub x Hacktoberfest
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
Cleaned Dataset for Voice gender detection using the VoxCeleb dataset (7000+ unique speakers and utterances, 3683 males / 2312 females). The VoxCeleb is an audio-visual dataset consisting of short clips of human speech, extracted from interview videos uploaded to YouTube. VoxCeleb contains speech from speakers spanning a wide range of different ethnicities, accents, professions and ages.
The similar version of dataset is uploaded to DagsHub, enabling you to preview the dataset before downloading it.
The author have downloaded all the files from VoxCeleb2. After this, he cleaned the data to separate all the males from the females. I took one voice file at random for all the males and females so as to provide unique files.
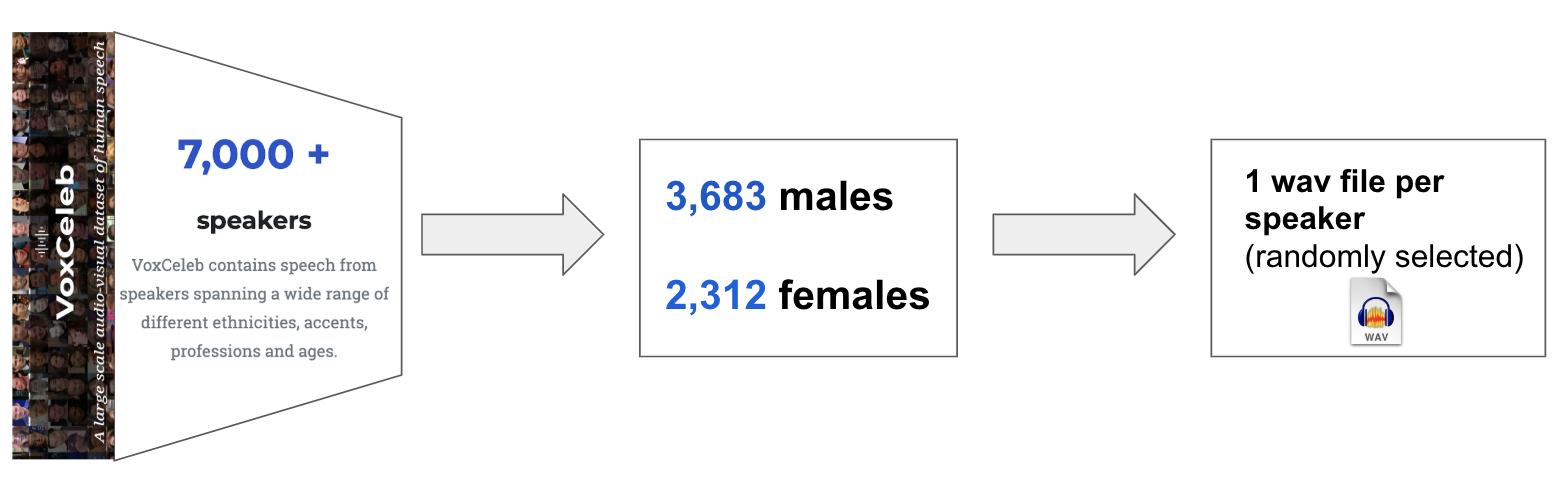
To prepare the dataset, He put the 'males' and 'females' folders in the data directory of this repository. This will allow for us to featurize the files and train machine learning models via the provided training scripts.

The original files that I downloaded were in .m4a format which is not detectable by DAGsHub audio visualization, so I used Python script to convert m4a files to wav files (github.com) to convert my dataset into .wav format. I ran code for the males and females folder separately.
The dataset is large (1.26GB) and simple to navigate as it has 2 folders based on binary gender. Males folder contains 3682 .wav audio files from unique speakers all over the world. Similar to the males folder we have females fold containing 2312 .wav files of unique females speakers. The audio duration range from 5~30 seconds to approximately 194 KB size. The following ASCII diagram depicts the directory structure.
<root directory>
|
.- README.md
|
.- fileconvert.py
|
.- females/
|
.- males/
|
.- 0.wav
|
.- 1.wav
|
.- 2.wav
| ...
The dataset is used to train a machine learning model to detect males from females from audio files (90.7% +/- 1.3% accuracy). You can find more about code and results here.
Decision tree accuracy (+/-) 0.007327676542764603
0.7398596519424567
Gaussian NB accuracy (+/-) 0.016660391044338484
0.8682797740896762
SKlearn classifier accuracy (+/-) 0.00079538963465451
0.5157270607408913
Adaboost classifier accuracy (+/-) 0.013940745120583124
0.8892763651333413
Gradient boosting accuracy (+/-) 0.01950292233912751
0.8669747415791165
Logistic regression accuracy (+/-) 0.012678238150779661
0.894515837971657
Hard voting accuracy (+/-) 0.013226860908589952
0.9076178049591996
K Nearest Neighbors accuracy (+/-) 0.017244722910655787
0.731352177051436
Random forest accuracy (+/-) 0.02258623279374182
0.8079923672086033
svm accuracy (+/-) 0.022841304608332974
0.8781480823563248
most accurate classifier is Hard Voting with audio features (mfcc coefficients).
First, I would like to thank Jim Schwoebel for publishing dataset on GitHub and explaining in depth how to use this dataset. Secondly, I would like to thank VoxCeleb for providing amazing open source dataset.
The VoxCeleb is supported by the EPSRC programme grant Seebibyte EP/M013774/1: Visual Search for the Era of Big Data.
Jim Schwoebel, Aug 8, 2020
Original Dataset: Voice Gender Detection
DAGsHub Dataset: kingabzpro/voice_gender_detection
This open source contribution is part of DagsHub x Hacktoberfest