Not Waiting for Two Days to Work on My Dataset
- Jinen Setpal
- 3 min read
- 3 years ago
Machine Learning Engineer @ DAGsHub. Research in Interpretable Model Optimization within CV/NLP.

In July, I began a project that uses the SYNTHIA dataset. It’s a huge image dataset, and I have an awful ISP:
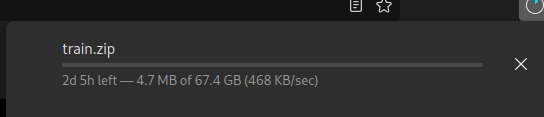
Waiting two days and change just to get started on a task is annoying. However, with the Data Engine, I’m able to come up with a much quicker way to begin working.
From there, I can use the data engine to query and subset the dataset without needing to have data present locally. I can lazily stream any specific samples I need to evaluate if everything is working on my development machine. Once I’m ready to begin a training run, I can bump the AWS instance to a GPU instance, restart it, pull the repository and immediately begin training.
To begin, I setup a t2.micro EC2 instance on AWS:

I then went to the downloads page of the dataset, and used devtools to log network traffic for when I pressed the download button:

I then cancelled the download location, and then copied the request with file train.zip as a curl request:
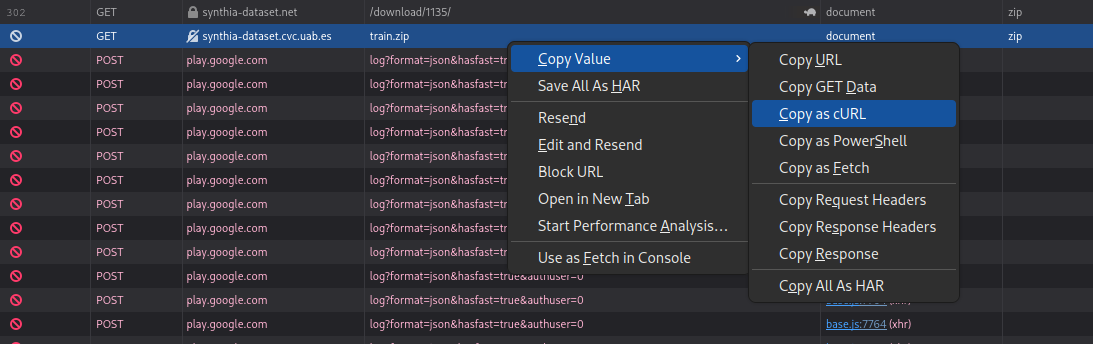
I cleared the UA information from the curl request, and pushed the process to the background:
$ nohup curl -O <http://synthia-dataset.cvc.uab.es/SYNTHIA-AL/train.zip> &
Just like that, the dataset download wait time is cut down to a couple of hours. If I’m in a greater hurry, I could also opt for an instance with a higher network throughput, but this will do for now.
Next, we'll unzip the data, and sync it to the S3 bucket. This has two advantages:
- Since it's internal Amazon infrastructure, the data transfer is fast.
- When we connect the bucket to the repository, we do not need to wait until the complete dataset is ready in the remote, unlike DVC. This let's us experiment with a sample quicker; once our code is ready to run a full training set, so is the dataset!
Here's the code to unzip and sync:
$ unzip train.zip ; aws s3 cp train s3://data-bucket/ --recursiveI then added the bucket to the repository. Here’s the synced the S3 bucket with the data:
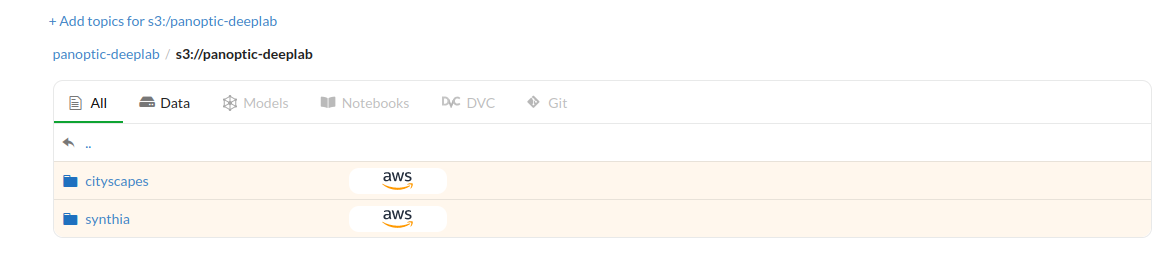
Now, I can browse, view and download files as I need it. This is a good start, but I still can’t setup a data processing pipeline just yet. To fix that, I’ll integrate this with the new Data Engine by creating a datasource, and print the resultant dataframe:
In [1]: from dagshub.data_engine import datasources
In [2]: ds = datasources.get_datasource('jinensetpal/panoptic-deeplab', name='synthia')
In [3]: data = ds.head()
In [4]: data.dataframe
Out[4]:
path ... size
0 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 14694
1 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 15480
2 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 59839
3 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 204669
4 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 14847
.. ... ... ...
95 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 21672
96 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 204746
97 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 15139
98 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 68168
99 test/test5_10segs_weather_0_spawn_0_roadTextur... ... 15068
[100 rows x 4 columns]Just like that, I can view the SYNTHIA dataset, enrich it with metadata, query it for subsets and setup a dataloader that automatically streams inputs towards training! 🎊



