Cookiecutter MLOps – A production-focused ML project template
- Dean Pleban
- 11 min read
- 4 years ago
Co-Founder & CEO of DAGsHub. Building the home for data science collaboration. Interested in machine learning, physics and philosophy. Join https://DAGsHub.com | DagsHub Co-Founder & CEO

A while back, A thought-provoking tweetstorm by Shreya Shankar about MLOps principles every ML platform should have, caused a frenzy on Twitter.
I probably should have written this years ago, but here are some MLOps principles I think every ML platform (codebase, data management platform) should have: 1/n
— Shreya Shankar (@sh_reya) May 4, 2022
Many people discuss MLOps and how to achieve better tooling for getting models into production, but few share practical tips you can more or less implement for your use case, and see immediate value. The list was split into maturity levels (beginner, intermediate, and advanced), and included 9 recommendations overall.
It was almost begging for someone to go ahead and make a repo that implemented as many of these rules, to make them even more concrete, actionable, and adaptable to real-life use cases.
So that is exactly what we did!
In this post, we’ll review the principles laid out by the MLOps Twitter thread, and show how we implemented them in a repo you can use today to improve your MLOps game and prevent the next messy-machine-learning-code-life-crisis.
The Rules of MLOps (according to the tweet)
“The first rule of MLOps is: you do not talk about MLOps” - Tyler Durden
Beginner
- Use pre-commit hooks: With so many easy-to-detect issues with your code, why wouldn’t you want to check automatically before submitting your code for review or production? Since dirty and unstructured code can hide bugs or problems, adding hooks helps discover things as soon as possible. The tweet specifically mentions black, isort, pydocstyle, mypy, check-ast, and eof-fixer, which are all great. Thanks also to Ori Cohen for recommending a few additional ones. If you have additional recommendations, let us know in the issues section.
- Attach a Git hash to each trained model: Do this by making sure you only train with committed code. You can use tools like DVC that run a pipeline and commit outputs automatically so that your model is actually committed alongside your code, but even if that’s not an option for you, making sure code is committed for every model version is critical. Another way to approach this, if you’re using tools like MLflow to track experiments, is to attach the
run_idthat had the model training to the git commit. This is a good place to also recommend you track your experiment parameters and metrics. It will help you make sense of this model, and if the hash exists both in your code and the experiment tracking table, it’ll provide a good way to debug your models. - Use a Monorepo: This refers to having a single project that encompasses your entire pipeline, including data processing, model training, evaluation, and deployment. This reduces complexity by having interfaces between project components in the same place, making it easier to understand what’s going on, get to the bottom of issues and collaborate.
- Version your data: Data is a part of the ML source code, and should be treated as such. Being able to reproduce a model is critical. The easiest way here is to use tools like DVC or LakeFS for data version control (assuming you have unstructured – i.e. non-DB-stored data). For DBs you have other options, like Delta Lake, but each format has its caveats. You can read more about this in our comparison of data versioning tools.
- Set data quality SLAs: This is perhaps the least intuitive point in this segment. Since data is part of the source code, it might have bugs in it as well. Automate things as much as possible, but they aren’t airtight. Having a human in the loop to sanity-check your data can save you a lot of grief. This might seems like a privileged approach since you don’t always have time or (wo)manpower to do a lot of manual testing. However, I believe that no matter how small your team is, dedicating a small percentage of your time to manually checking your data will pay off greatly later down the line. Starting to build a healthy culture here is never too early.
Intermediate
- Monitor your models: Many times teams thinking about monitoring fall into two buckets – either they decide not to invest any time into making it work due to complexity or delayed labels. Or they go all in and look for an end-2-end enterprise platform. In the tweet thread, Shreya advocates a middle ground. Even if you are at the beginning of your monitoring journey, manual labeling of a few predictions and updating a metric is a great way to get reasonable-scale monitoring. If we want to avoid buzzwords, calling this a baseline would also be a good description, but it’s the simplest starting point and will help you avoid a lot of downstream problems, without a huge upfront investment.
- Retrain models on a regular cadence: Many teams try setting a metric bar for retraining, but that can create a lot of cognitive overhead + a need to develop custom systems to identify metric changes. A simpler and very effective alternative is to set a regular time interval (e.g. once a month) to retrain. This is easier to set up and maintain. You can rely on the aforementioned metric to select the appropriate cadence for you.
Advanced
- Deploy a simpler model in parallel to your main one: Shreya approaches this from a reliability perspective. In addition to your main model, deploy a shadow model built on a simpler/smaller architecture that can substitute for your main model if it goes down or has a bug. This is useful since debugging ML models is notoriously hard. Another fine point here is you can also use this for Inference Triage – this means you use the simpler model to run inference first, make sure that it also produces a confidence interval, and then only use the larger model for inference when the smaller one is unsure.
- Continuous Integration for ML: You should obviously write unit tests for your code, even when it’s ML related, but the principle here is to do more than that. You should also use your CI system to test things that are purely ML-related like overfitting your training pipeline to a tiny batch of data, verifying data shape, integrity checking for features, etc. We can think of these as data tests and model tests. A good way to start is with end-to-end tests, and then work our way to more specific tests that are relevant to our project and use case.
These brilliant ideas inspired us, but on Twitter, they were presented as exactly that, ideas. They weren’t implemented in a way that might make building with them in mind easy. We decided to take on that challenge and created a template so those of you who enjoyed reading them may use them in your next projects. Introducing the Cookiecutter-MLOps Template.
Cookiecutter MLOps
As a first step, we decided to implement the first 5 principles dubbed beginner. We’d love to accept contributions for the other rules, and might add them ourselves if we see this is useful to the community.
Let us know if you think that could be helpful on our Discord channel.
Below is an explanation of the principles we implemented and how we approached each one. If you just want to look at the code, here’s a link to the project.
1. Beginner: Use pre-commit hooks
Pre-commit hooks are, as their name suggests, essentially scripts that run before a git commit is made. Many times, they are used to enforce certain behaviors or standards on the code being committed, so that even if you forget to implement the standards, you get a reminder and a nudge in the right direction.
To implement pre-commit hooks, we chose to utilize pre-commit, an open-source framework that contains pre-commit hook recipes for many programming languages. The template utilizes 7 pre-commit hooks:
- check-yaml: Verifies the syntax of all YAML files
- end-of-file-fixer: Ensures that files terminate with a newline and nothing else
- check-ast: Simply determine if files parse as correct Python
- trailing-whitespace: Trims trailing whitespace but can also be customized to trim specific characters
- black: Python code formatter
- mypy: Static type checking for Pythonisort: Utility to sort your python imports
- isort: Utility to sort your python imports

For the implementation details, check out the .pre-commit-config.yaml in the project.
To make sure your hooks are installed correctly, run make pre-commit-install. Now every time you commit something, these tiny helpers will make sure you don’t miss anything important.
Here is an example of what pre-commit hooks running before a commit look like:

2+3+4. Beginner: Attach a Git hash to each trained model + Use a Monorepo + Version your data
The easiest way to do this is to treat your data as part of the source code, and in our case, version your model as well. At DagsHub, we use the open-source tool DVC to accomplish precisely this.
If you use DVC and DagsHub, this comes out of the box. In our project, we built a DVC pipeline that contains a stage for processing data and training the model. Of course, you will need to edit the make_dataset.py and train_model.py files to fit your use case, but as long as you put your raw data in the data/raw folder, and the code files properly output the processed data and models to the data/processed and models folders respectively, they will be automatically versioned. In Figure 1 below, you can see the resulting pipeline we built.
This also addresses the Monorepo architecture, since the entire pipeline is contained within the project (see image below), you have the interfaces set out very clearly, and they are mostly based on file I/O, which is versioned and transparent.
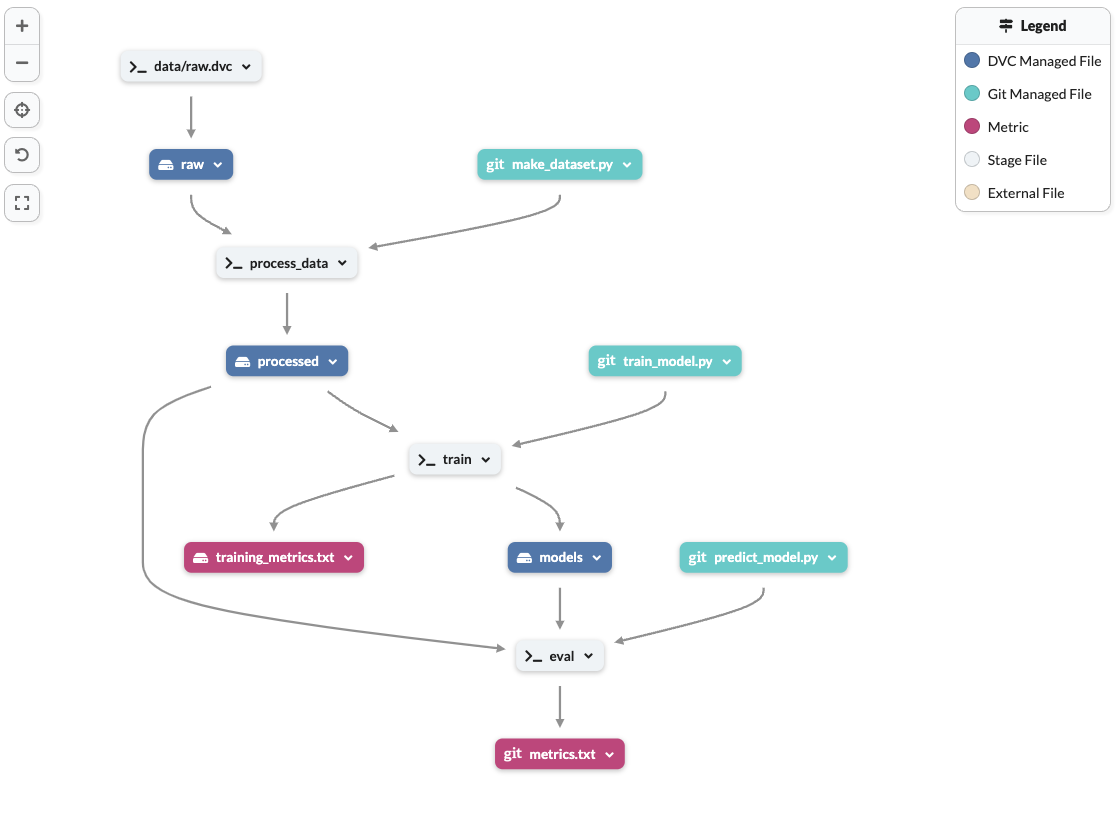
For a great guide to using DVC for data and model tracking check out our Get Started tutorial
5. Beginner: Set data quality SLAs
The next step was to implement SLAs for data quality as our next action. This is much more of a solved problem for tabular data, but once you stray off the beaten path into the realms of unstructured data – e.g. computer vision or NLP, it’s much harder to find solutions. We searched far and wide for the finest data testing tools for ML data, models, and pipelines, the main solutions we found, from simplest to the most complex, were TDDA, Deepchecks, and Great Expectations, which have predefined test suites for tabular data and a decent solution for computer vision. We decided to use Great Expectations, which also provides (non-simple) ways to create custom expectations.
We tried to make our template as universal as we could, but the data for various ML tasks cannot be generalized for validation. The template we provide is not prescriptive since creating a template for tests requires additional information about the data. However, we also supply an example for tabular data that provides the end-to-end implementation – see the example branch for more details.
We provide two main preset commands for data quality SLAs: make setup-data-validation which will help you set up great expectations in your project, using their nifty Jupyter notebook-based wizard, and make run-data-validation which will run your data tests end-2-end and create the interactive documentation you see below.
Setting up Great Expectations is use-case specific, but for a Get Started tutorial check out their documentation

Now that you have a template, you’re pretty much ready to go with your project, applying MLOps best practices as you go along.
However, we are aware that it’s sometimes hard to understand how this template works in real life, and that’s why we created the example-project branch. The next section of the blog covers how we implemented this template for a simple movie review sentiment analysis. It’s by no means necessary to make use of the template but might make it easier if you’re not sure how to start.
An End-to-End Example
Let’s walk through a simple sentiment analysis example project, using the IMDB movie review dataset and inspired by a great Kaggle notebook to understand the template better. You can switch to the branch example-project to try it out yourself.
Data versioning and validation
We downloaded the IMDB Large Movie Review Dataset and place it in the data/raw directory in our project. We then add it to DVC so that our raw data is versioned. We also add tests for it using Great Expectations – In this case, we tried using their automated profiler to create expectations based on the data structure, but we still needed to manually edit them since the tests were too lenient (e.g. testing column data types with the expectation that they are in a broad set, whereas in reality, it should only be a string).
We then add preprocessing code into our make_dataset.py file, so that we can automate the preprocessing step in the future. The important thing to note here is that to use DVC’s automation and output versioning capabilities, the script must read the input from a file, and save the output to a file. If you use very large raw data stored in a DB, you might want to take the opportunity to query and track the dataset you train on as a file, as opposed to working on it directly from and to your DB.
I also recommend not hard-coding data locations in the various script, instead passing them as arguments to enable easier customization.
Running Pre-Commit Hooks & Data Checks
We ran the pre-commit hooks before each commit, and if the data changed, we would re-run data validation. As a bonus concept, the data validation could be added as a custom pre-commit hook, so that it would run tests before every commit as well.
Training & Evaluation
We use a simple KNN Classifier for our binary classification task along with cross-validation. Running the command `dvc repro` re-runs the entire pipeline, performing processing, training, and evaluation of our model while saving metrics in a format parseable by experiment tracking tools like DagsHub or DVC.
What’s next?
Nothing beats community-based learning and there is still a lot of work to do. With so many more rules left to build, we encourage YOU to contribute to the template with what you think would be essential for a healthy ML Pipeline. Let’s join hands to make this template THE go-to for everyone starting an ML project!
A huge thanks to Shreya Shankar, without who this project and blog wouldn’t have existed. Totally follow her on Twitter! If you have comments or if you want to share your thoughts about this project, feel free to reach out to us and join our amazing community on Discord.
Thanks also to Ori Cohen for his invaluable feedback.



