
In machine learning, a loss function, also known as a cost function, is a method used to estimate the discrepancy between the actual output and the predicted output of a machine learning or deep learning model. The function quantifies the error in prediction, providing a numerical value that the model seeks to minimize during the training process. The choice of loss function is crucial as it directly impacts the performance and efficiency of a machine learning model.
Loss functions can be broadly categorized into two types: regression loss functions, used in regression problems where the output is a continuous value, and classification loss functions, used in classification problems where the output is a categorical value. This article comprehensively explains various types of loss functions used in machine learning, their mathematical formulations, and their applications.
Improve your data
quality for better AI
Easily curate and annotate your vision, audio,
and document data with a single platform

What are Loss Functions?
Loss functions are fundamental to the process of machine learning. They provide a means to measure the performance of a model by calculating the difference between the predicted and actual values. The loss function is the guiding light for the learning algorithm, pointing the way toward the optimal solution. The model adjusts its parameters iteratively to minimize the value returned by the loss function, thereby improving its predictions.
The loss function choice depends on the problem at hand and the type of machine learning algorithm being used. Different loss functions are suitable for different types of problems and data. Understanding the characteristics and applications of various loss functions is essential for selecting the appropriate one for a given machine learning task.
Components of a Loss Function
A loss function consists of two main components: the actual value and the predicted value. The actual value, also known as the ground truth, is the true output value for a given input. The predicted value is the output value estimated by the ML model for the same input. The loss function calculates the difference between these two values to quantify the error in prediction.
The loss function can also include other components, such as regularization terms, which are used to prevent overfitting. Overfitting is a common problem in machine learning where the model performs well on the training data but poorly on unseen data. Regularization terms add a penalty to the loss function for complex models, encouraging the learning algorithm to find simpler solutions that generalize better to unseen data.
Properties of a Good Loss Function
A good loss function should be able to accurately measure the error in prediction and guide the learning algorithm towards the optimal solution. It should be differentiable, meaning that it has a derivative at all points in its domain. This property is important because many machine learning algorithms, such as gradient descent, rely on the derivative of the loss function to update the model parameters.
A good loss function should also be robust to outliers, meaning that it should not be overly influenced by extreme values in the data. Outliers can skew the loss function and lead the learning algorithm off target, resulting in a suboptimal solution. Robust loss functions are designed to be less sensitive to outliers, providing a more accurate measure of the error in prediction.
Types of Loss Functions
There are numerous types of loss functions used in machine learning, each with its own strengths and weaknesses. The choice of loss function depends on the specific problem at hand and the type of machine learning algorithm being used. This section provides a detailed explanation of various types of loss functions, their mathematical formulations, and their applications.
Loss functions can be broadly categorized into two types:
Regression Loss Functions
Regression loss functions are used in regression problems where the output is a continuous value. These loss functions measure the discrepancy between the predicted and actual values, providing a numerical value that the model seeks to minimize. Common regression loss functions include mean squared error, mean absolute error, and Huber loss.
Mean Squared Error
Mean squared error (MSE) is the most commonly used regression loss function. It calculates the square of the difference between the predicted and actual values, averaging these squared differences over all data points. MSE is sensitive to outliers as it squares the differences, causing large errors to have a disproportionately large impact on the total loss.
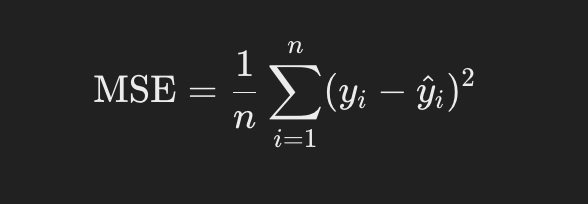
Where:
- n is the number of samples.
- yi is the actual value for the i-th sample.
- ŷi is the predicted value for the i-th sample.
Mean Absolute Error
Mean absolute error (MAE) is another commonly used regression loss function. It calculates the absolute difference between the predicted and actual values, averaging these absolute differences over all data points. MAE is less sensitive to outliers than MSE as it does not square the differences. However, it is not differentiable at zero, which can cause problems for certain optimization algorithms.
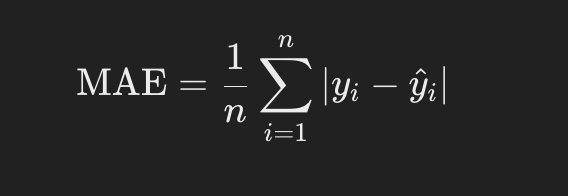
Where:
- n is the number of samples.
- yi is the actual value for the i-th sample.
- ŷi is the predicted value for the i-th sample.
- |.| denotes the absolute value.
Huber Loss
Huber loss, also known as smooth mean absolute error, is a hybrid of MSE and MAE. It calculates the square of the difference for small errors and the absolute difference for large errors, providing a balance between the sensitivity to outliers of MSE and the robustness of MAE. Huber loss is differentiable everywhere, making it suitable for use with all optimization algorithms.
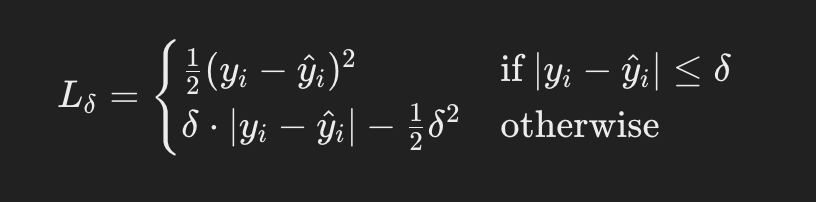
Where:
- yi is the actual value for the i-th sample.
- ŷi is the predicted value for the i-th sample.
- δ is a hyperparameter that controls the threshold between the quadratic and linear regions of the loss function.
Classification Loss Functions
Classification loss functions are used in classification problems where the output is a categorical value. These loss functions measure the discrepancy between the predicted and actual classes, providing a numerical value that the model seeks to minimize. Common classification loss functions include cross-entropy loss, hinge loss, and log loss.
Cross Entropy Loss
Cross-entropy loss, also known as log loss, is the most commonly used classification loss function. It calculates the negative logarithm of the predicted probability for the actual class, averaging these negative logarithms over all data points. Cross-entropy loss is sensitive to the confidence of the predictions, penalizing confident and incorrect predictions more than unconfident and incorrect predictions. There are two main types of cross-entropy loss, the first one is binary cross-entropy loss used for binary classification problems, and another one is categorical cross-entropy loss used for multiclass classification problems.
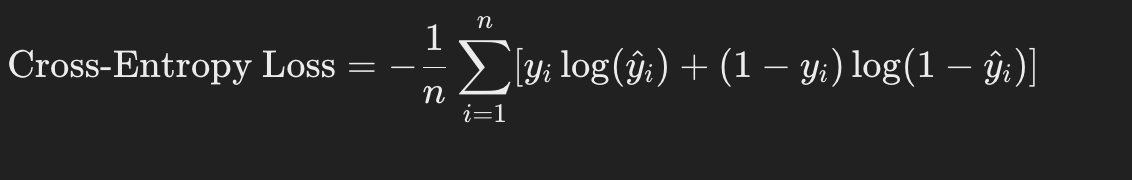
Where:
- n is the number of samples.
- yi is the actual value for the i-th sample.
- ŷi is the predicted value for the i-th sample.
Hinge Loss
Hinge loss is another commonly used classification loss function, particularly in support vector machines. It calculates the maximum of zero and the difference between one and the product of the actual and predicted classes. Hinge loss encourages a margin of separation between classes, penalizing predictions that are on the wrong side of the margin more than predictions that are on the right side but close to the margin.
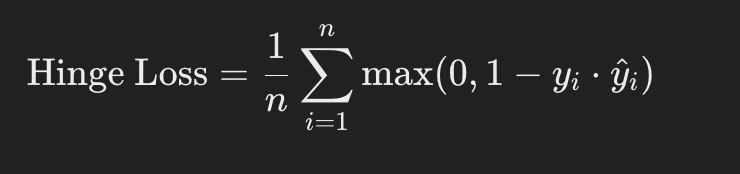
Where:
- n is the number of samples.
- yi is the actual value for the i-th sample.
- ŷi is the predicted value for the i-th sample.
Log Loss
Logistic loss, also known as logit loss, is a variant of cross-entropy loss used in logistic regression. It calculates the logarithm of one plus the exponential of the negative product of the actual and predicted classes, averaging these logarithms over all data points. Logistic loss is sensitive to the confidence of the predictions, penalizing confident and incorrect predictions more than unconfident and incorrect predictions.
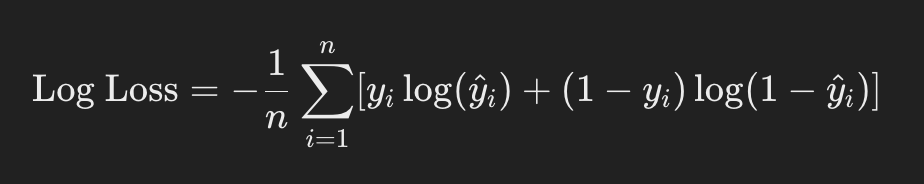
Where:
- n is the number of samples.
- yi is the actual value for the i-th sample.
- ŷi is the predicted value for the i-th sample.
Choosing the Right Loss Function
Choosing the right loss function is crucial for the performance and efficiency of a machine learning model. The choice depends on the specific problem at hand, the type of machine learning algorithm being used, and the nature of the data. This section provides some guidelines for choosing the right loss function for a given machine learning task.
Regression Problems
For regression problems, if the data contains many outliers, it may be better to use a robust loss function such as MAE or Huber loss. If the data does not contain many outliers and the distribution of the residuals is approximately normal, MSE may be a good choice. If the distribution of the residuals is skewed or heavy-tailed, it may be better to use a loss function that is less sensitive to large errors, such as MAE or Huber loss.
Classification Problems
For classification problems, if the classes are balanced and the cost of misclassification is the same for all classes, cross-entropy loss may be a good choice. If the classes are imbalanced or the cost of misclassification varies between classes, it may be better to use a loss function that takes into account the class imbalance or the cost matrix, such as weighted cross-entropy loss or cost-sensitive loss.
If the problem is multi-class classification, one-vs-all loss or one-vs-one loss may be appropriate. One-vs-all loss treats each class as a separate binary classification problem, while one-vs-one loss treats each pair of classes as a separate binary classification problem. These loss functions can handle multi-class classification problems, but they may be computationally expensive for problems with a large number of classes.
Considerations for Deep Learning
In deep learning, the choice of loss function can also depend on the activation function used in the output layer of the neural network. For example, if the output layer uses a sigmoid activation function, cross-entropy loss may be a good choice as it can help mitigate the problem of vanishing gradients. If the output layer uses a softmax activation function, categorical cross-entropy loss may be a good choice as it can handle multi-class classification problems.
It’s also important to consider the computational efficiency of the loss function. Some loss functions, such as cross-entropy loss and hinge loss, can be computationally expensive to calculate, especially for large datasets. In such cases, it may be beneficial to use a simpler loss function, such as squared error loss or mean absolute error loss, even if they are not the most theoretically optimal choice.
Improve your data
quality for better AI
Easily curate and annotate your vision, audio,
and document data with a single platform
