The Data Engine will allow you to share your queries and results with your teammates so they can continue where you left off.
We’re covering all steps to create training ready datasets

Simple interface to connect your external storage, no DevOps needed.
We currently support S3, Google Cloud, and S3 compatible, with more to be added in the near future.

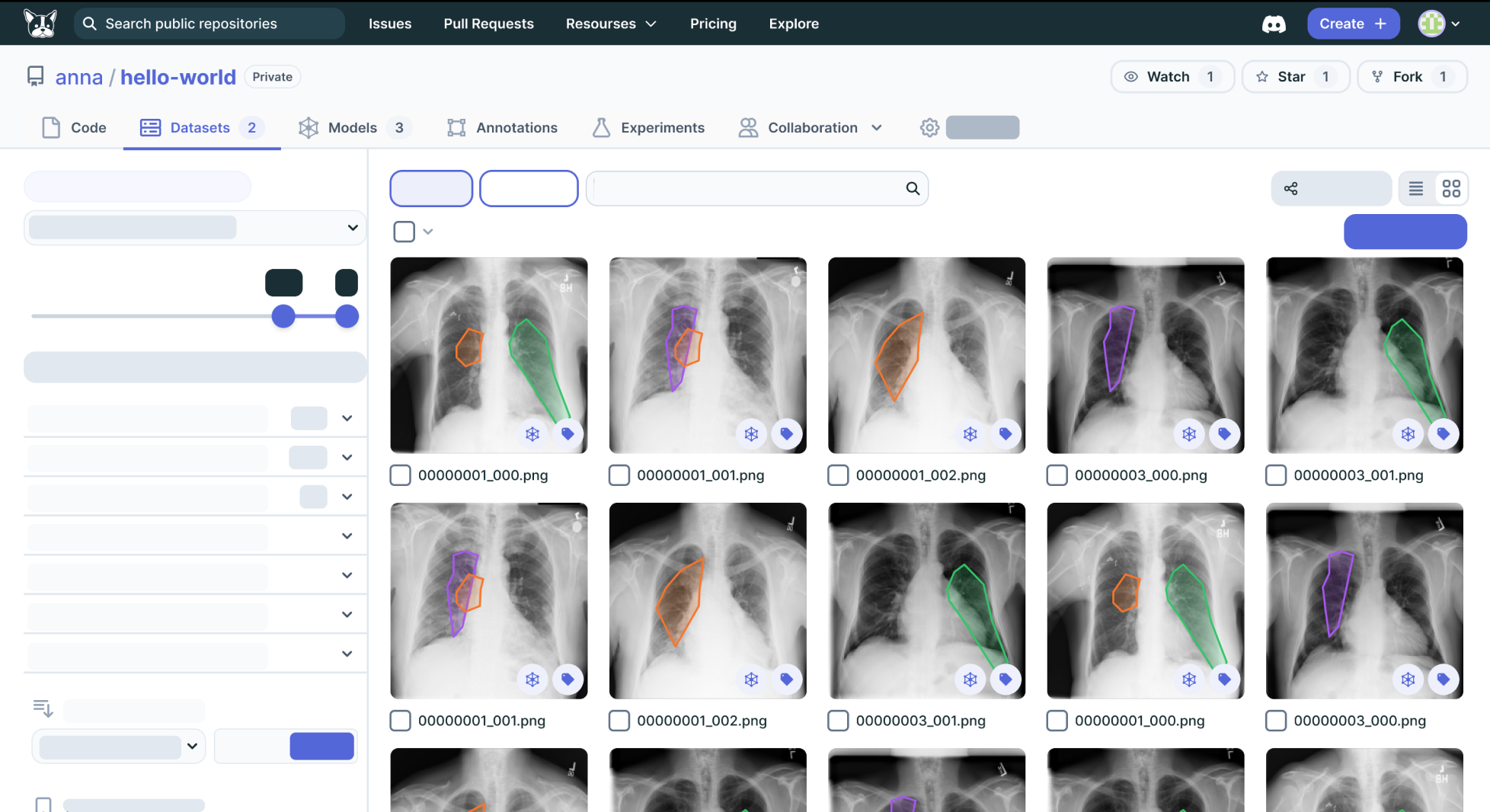
Clear & organized display of your datasets,
including visual lineage that connects datasets, models, experiments, labels and predictions

Pick and choose the most relevant data points to improve a model where performance is low. This can be achieved by filtering, sorting, and searching for similar examples to create and save a new training-ready version of the dataset

Annotate relevant data points in one click with zero setup. Use existing models to automatically label your data, and fine tune manually.

Use subsets of your data to experiment and retrain your model by streaming it directly to your pipeline and track your experiments within DagsHub.


We provide out-of-the-box solution for data queries, visualizations, versioning and annotations. No need for you to set up and maintain complicated infrastructure


Manage and display all your datasets, code, labels, experiments, models and queries, all in one platform.

