Point·E: Generate 3D Point Clouds from Complex Prompts
- Nir Barazida
- 6 min read
- 4 years ago
MLOps Team Lead @ DagsHub
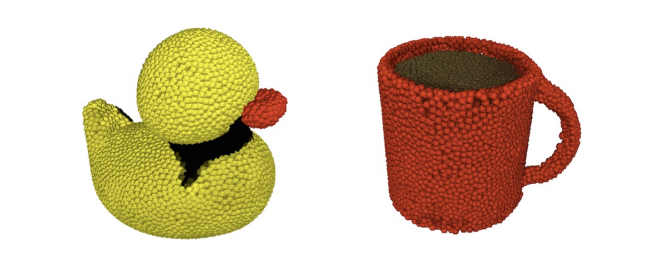
It's hard to believe that just a month ago, OpenAI released ChatGPT, a state-of-the-art chatbot model that has taken the world by storm. And now, it seems the team at OpenAI has done it again with the release of Point-E, a revolutionary new model for generating 3D point clouds from complex prompts. This model aims to improve the speed of 3D object generation, which has previously been a time-consuming process.

🃏 Try out Point-e
We were so excited about the results (and overall coolness 😎) of Point-E, that we decided to share the fun with EVERYONE!
We've build deployed a Streamlit app to generate 3D point cloud from images using Point-E 🤖 . The best part is that with DagsHub's data catalog, you can view the 3D model and share it with friends!
🚀 Take me to the app 🚀
One of the key features of Point-E is its use of diffusion models to generate synthetic views and 3D point clouds. These models use text input to generate an image, which is then used as a reference for generating the 3D point cloud. This process takes only 1-2 minutes on a single GPU, making it much faster than previous state-of-the-art methods.
While the quality of the samples produced by Point-E may not be as high as those produced by other methods, the speed of generation makes it a practical option for certain use cases.
OpenAI has also released the pre-trained point cloud diffusion models, as well as evaluation code and models, making it easy for others to use and build upon this technology.
Background & Methods
Point-E is based on the concept of diffusion models, which were first proposed by Sohl-Dickstein et al. (2015) and have been further developed in recent years ( Song & Ermon, 2020b; Ho et al., 2020). These models involve a noising process that gradually adds Gaussian noise to a signal over a series of timesteps, with the amount of noise added at each step determined by a noise schedule. This process can then be reversed to generate a sample from the distribution.
Point-E employs a Gaussian diffusion setup and uses a noise schedule such that, by the final timestep, the sample contains almost no information. The model also uses a neural network approximation to approximate the distribution and generate samples.
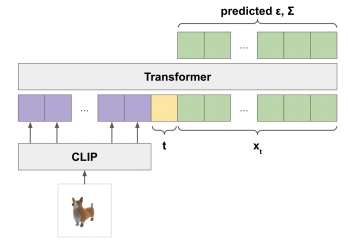
Point-E uses a second-order ODE solver to sample from the diffusion models, which is a good trade-off between quality and efficiency. The model also employs classifier-free guidance, where a conditional diffusion model is trained with the class label randomly dropped and replaced with an additional class.
During sampling, the model's output is linearly extrapolated away from the unconditional prediction towards the conditional prediction, allowing for the trade-off of sample diversity for fidelity.
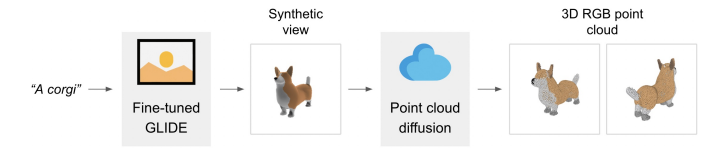
Rather than training a single generative model to directly produce point clouds conditioned on text, we instead break the generation process into three steps. First, we generate a synthetic view conditioned on a text caption. Next, we produce a coarse point cloud (1,024 points) conditioned on the synthetic view. And finally, we produce a fine point cloud (4,096 points) conditioned on the low-resolution point cloud and the synthetic view
Dataset
The dataset used to train Point-E consists of several million 3D models. To improve the data quality, the 3D models were rendered from multiple angles using Blender and the resulting renderings were converted into point clouds using dense point clouds and farthest point sampling. This process allows for the construction of point clouds directly from the rendered views, which can sidestep issues that might arise from attempting to sample points directly from 3D meshes, such as sampling points that are contained within the model or dealing with 3D models stored in unusual file formats.
In addition to constructing point clouds from the renderings, various heuristics were employed to reduce the frequency of low-quality models in the dataset. These heuristics included eliminating flat objects by computing the singular value decomposition of each point cloud and retaining those with a sufficiently large smallest singular value, clustering the dataset using CLIP features, and binning the resulting clusters into several buckets of varying quality. The final dataset was then created using a weighted mixture of these buckets.
To ensure that the model could correctly handle synthetic views, the dataset was also fine-tuned with a mixture of the original dataset and a dataset of 3D renderings. The 3D renderings were produced using the same renderer and lighting settings as the original dataset, allowing for the generation of 3D renders that match the distribution of the dataset. The 3D renderings were sampled 5% of the time during fine-tuning, with the original dataset being used for the remaining 95%. This allowed the model to make several epochs over the 3D dataset while still being primarily trained on the original dataset.
Results
In evaluating Point-E, the authors used a combination of sample-based and prompt-based metrics. The sample-based metrics included point cloud Inception Score (P-IS) and point cloud Fréchet Inception Distance (P-FID), which were designed to be analogous to Inception Score and Fréchet Inception Distance, respectively, but for point clouds. The authors also used CLIP R-Precision, a prompt-based metric that measures the ability of the model to generate a target object in response to a written description.
- 40M (uncond.): a small model without any conditioning information.
- 40M (text vec.): a small model which only conditions on text captions, not rendered images. The text caption is embedded with CLIP, and the CLIP embedding is appended as a single extra token of context. This model depends on the text captions present in our 3D dataset, and does not leverage the fine-tuned GLIDE model.
- 40M (image vec.): a small model which conditions on CLIP image embeddings of rendered images, similar to Sanghi et al. (2021). This differs from the other image-conditional models in that the image is encoded into a single token of context, rather than as a sequence of latents corresponding to the CLIP latent grid.
- 40M: a small model with full image conditioning through a grid of CLIP latents.
- 300M: a medium model with full image conditioning through a grid of CLIP latents.
- 1B: a large model with full image conditioning through a grid of CLIP latents.



In the experiments, the authors found that models that were conditioned on images (either through image embeddings or a grid of CLIP latents) performed significantly better than those that were only conditioned on text captions. They also found that larger models (those with more parameters) generally performed better than smaller models, but that there was diminishing returns in model size beyond a certain point.
Overall, the authors found that Point-E could generate point clouds of similar quality to the state-of-the-art, but could do so significantly faster (1-2 minutes per sample on a single GPU, compared to several hours for other methods). They also found that Point-E was able to generate point clouds that were more diverse than those generated by other methods, as measured by P-IS.
Comparison to other methods
As text-conditional 3D synthesis is a fairly new area of research, there is not yet a standard set of benchmarks for this task. However, several other works evaluate 3D generation using CLIP R-Precision, and we can compare to OpenAI's method in terms of performance and efficiency.
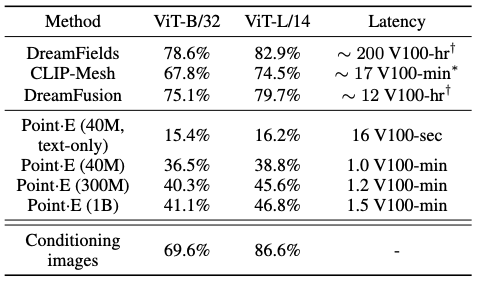
While this method performs worse than the current state-of-the-art, we note that our method is one to two orders of magnitude faster to sample from, offering a practical trade-off for some use cases. Additionally, this method compares favorably to other techniques in terms of sampling compute requirements, with significantly lower requirements than some other methods.
Conclusion
Point-E is a groundbreaking new open-source model that allows for the fast generation of high-quality 3D point clouds from complex prompts. By leveraging the power of diffusion-based models and image conditioning, Point-E is able to produce 3D models in just a matter of minutes, making it a practical option for a variety of use cases. While there is still room for improvement in terms of sample quality, the speed and diversity offered by Point-E make it a promising step forward in the field of text-conditional 3D object generation.



