Model Registry for ML - Managing Models in Production
- Arjun Vikram
- 5 min read
- 4 years ago
Open Source Data Scientist @ DagsHub

Machine Learning Engineer
em · ell · eee ~ noun
An intelligent being that crafts fresh data into models using expensive GPUs and even more expensive coffee.
But what does the Machine Learning Engineer do with a model once they train it? Fax it to their boss? Copy it to a floppy disk and pass it around the office? Place it on a network share in a location only written in the bottom of a locked filing cabinet stuck in a disused lavatory with a sign on the door saying 'Beware of the Leopard'? Maybe sprinkle a bit of MLOps on it?

To keep the work of this MLE from going to waste, these models need to be collected and harnessed, not left to rot. But that's easier said than done. Data Science teams are often disconnected from the consumers of their work: the teams taking their models and extracting usable value from them. Even when there is constant communication between the two, there is a lot of overhead involved in using new and updated models.
To keep track of these constantly evolving models, Data Science teams often resort to tools like spreadsheets. However, external organization systems are just that—external—and will quickly get out of sync and therefore become useless. In addition, these manual systems cannot possibly track every bit of metadata about models, leaving developers to manually inspect models and sleuth out the data and code used at the time of training.
That's where model registries come in.
What is a Model Registry?
Model Registry
A magical place to facilitate model storage, versioning, tracing, discovery, and deployment.
A model registry replaces the ad-hoc spreadsheet and file-share of yore, providing a single source of truth for all models. Data Science teams automatically upload each trained model to the registry, and consumers browse and download models from the registry.
Let’s take a look at the essential pillars of a model registry, and the problems they solve.
Essential Pillars for Model Registry Tools
Model Storage
This part is pretty obvious. The basic requirement of a model registry is allowing Data Scientists to store models in the registry.
A registry lets Data Science teams share their models with their consumers “without a DevOps degree,”—no creating and configuring shared filesystems or object storage buckets or cloud credentials needed. The goal of a model registry is to act as the singular storage layer between model producers and consumers. Of course, it makes use of shared filesystems or object storage behind the scenes, but that’s all configured in a “set and forget” fashion, never to be touched again by anybody but the sysadmin.
A well-designed registry supports uploads and downloads from a variety of different environments, facilitating its use across clouds and on-premise domains. Unifying registry access controls from those environments allows developers and users to simplify access without worrying about complex cloud IAM identities. To Data Science teams, uploading to the registry should feel just like magic!

Model Versioning
Models are constantly being changed, and one of the key features of a model registry is the ability to save every version of a model.

Coming from the software development world, one may be forgiven for thinking that the consumers should always make use of the “latest” model, to reap the rewards of the Data Science team’s most recent efforts. However, because Data Science is inherently driven by research and experimentation, the most recent model is not necessarily the best model, or even production ready at all. They can represent experimental techniques, disproved hypotheses, interrupted training runs, or simply worse performing models.
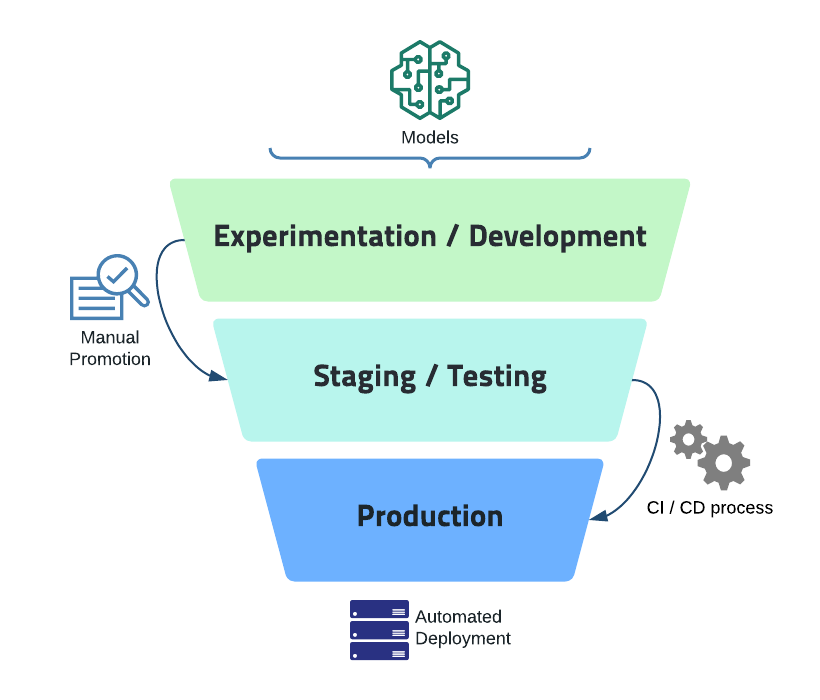
Instead, model registries keep track of which versions of models are to be used in which places. Models are labeled as for experimentation, testing, or production, allowing automated processes to consume the correct version without confusion. This allows Data Science teams to upload and evaluate an unlimited number of models without impacting QA and production environments.
Data Science teams can then promote model versions from experimentation to testing and then production, after conducting integration and data tests. This allows for seamless Continuous Integration between Data Science teams and their consumers.
Model Tracing
Whether a model is being used in production or is simply being experimented on, it is important to be able to trace it back to the data, dependencies, code, and pipeline used to train it.
Model registries store this metadata directly alongside the models, allowing for it to be easily checked even at deploy time. This lets the Data Science team rapidly answer queries like
- “Was the production model trained using a version of Tensorflow with a security vulnerability?”
- “Was the new dataset the reason for the improvement in the performance of the latest model?”
- “Did we fix the training bug before or after the testing model was trained?”
With a well-designed model registry, this metadata comes directly from the source, leaving no chance that it is incorrect because a Data Scientist forgot to update a config somewhere.
Model Discovery
What good is a model if it’s not being used?
Model registries provide an interface for the business to discover the value being produced by Data Science teams. In addition to their programmatic interfaces, registries provide a UI designed for non-technical users to browse through models.
This is key to extracting value from a business’ data and data science arms. For instance, if a business team is interested in predicting user churn, they might search through the registry for a model—perhaps finding one that predicts user value over time, which they can adapt for their purposes.
Without a centralized, searchable registry, the models produced by Data Science teams are put to work for one purpose only, or, worse, never used by the business at all!
Model Deployment
By collecting uniformly-formatted models in one central place, the model registry is uniquely suited to assist with deploying these models to production. Though a model registry isn’t required to handle model deployment, those that do have a clear advantage.
Ideally, a model registry would support built-in zero-configuration deployment. It should allow you to quickly spin up an inference API for any of the models uploaded by the Data Science team without writing a single line of code.
In addition, it should also allow you to connect your own external deployment tools through an API, so you can manage the deployment lifecycle of your models through the registry.

How can DagsHub help?
We've seen the pillars of a modern model registry – what you should expect to get when evaluating possible solutions and why they are needed in general.
Stay tuned for Part two of ML Model Registries is out! Check it out to learn about DagsHub’s model registry capabilities, and see how easy it is to take advantage of them!



