Free Dataset & Model Hosting with Zero Configuration – Launching DAGsHub Storage
- Dean Pleban
- 4 min read
- 6 years ago
Co-Founder & CEO of DAGsHub. Building the home for data science collaboration. Interested in machine learning, physics and philosophy. Join https://DAGsHub.com | DagsHub Co-Founder & CEO

Data Scientists deserve to browse, preview, share, fork, and merge data & models alongside code
TL;DR: Jump directly to the docs if you want to see how to set up DAGsHub Storage.
Since we launched DAGsHub, and specifically DVC remote storage browsing (example), and Data Science PRs (example), we’ve spoken to many data scientists and users from different backgrounds. We’ve received a TON of great feedback, but one thing that bugged us and was a recurring theme was how involved the process for setting up a DVC remote for data and model storage. We repeatedly saw people getting confused by setting up storage bucket permissions or if they tried Git-LFS, being frustrated by storage limits or the fact that it wasn’t a generic format (supporting their cloud storage natively).
That’s why we’re launching DAGsHub Storage. DAGsHub Storage is a DVC remote that requires 0 Configuration (works out of the box), includes team and organization access controls, and easy visibility. Since it is a type of DVC remote, you get all the benefits of using DVC without worrying about cloud setup. It works like adding a Git remote to your project.
Zero Configuration Data & Model Hosting
This will be especially useful for data scientists that want to share their work including data and models with others or collaborate on a project – whether it’s research, a hobby project, or even a Kaggle competition. It also means that sharing work with non-DVC users is much easier, as there is no cloud setup required on their end.
Solving Data Bugs and Dead Models
Data Scientists face many challenges in their work. Some are “straightforward” such as bugs in your data, while others relate to the ability to reuse and share models and results between teams or individuals. Everyone agrees that easy-to-reproduce access to models and the ability to get more data, or more up-to-date data is a net positive for the community (whether research or industry), but the tools to support that effort didn’t exist.
Part of the solution is a change in our mental models. If datasets are constantly updated, they should be treated as a kind of source code. If models need to be easy to access and share, we must put an extra emphasis on logging the pipelines and the experiments that led to the current model. However, better mental models aren’t enough, and the tools that support these mental models must be amazing as well, for the change to be easy. These tools are mainly data and model version control, and making it easy and accessible is exactly what DAGsHub Storage is for.

The Solution
If we want to encourage individual contributors to collaborate on data science, we must make their lives as easy as possible, without losing the goal we started with. DAGsHub supports the cloud storages that users tend to adopt – S3, GCS, GDrive. When we started noticing users are still struggling with cloud or remote setup, it was clear that this wouldn’t do.
DAGsHub Storage means that the entire setup process is simplified to adding the remote link to your project and pushing the data. Sharing data and models then becomes as easy as sharing a link, which leads collaborators to an easy overview including project data, models, code, experiments, and pipelines. The easiest way to see it in action is to go through our basic tutorial.
We hope that the free storage and ease of use will result in much less friction for teams and individuals that want to share and collaborate on data and models in the same way they collaborate on code, unlocking new opportunities for the data science community.
Since DAGsHub is based on Git, DVC, and other open-source tools and formats, all this good doesn’t require you to give up on GitHub, or your favorite orchestration engine. You can just connect an existing project and push your data and models to DAGsHub in parallel.
The Open Source Data Science Angle
At DAGsHub, we put Open Source Data Science first. We care deeply about helping people work together on community projects and always consider it when adding new capabilities to the platform. We also spend some time explaining how these new capabilities help promote Open Source Data Science specifically.
In this case, not much needs to be said, since it is very clear how having free, easy to access data and model storage will help the community.
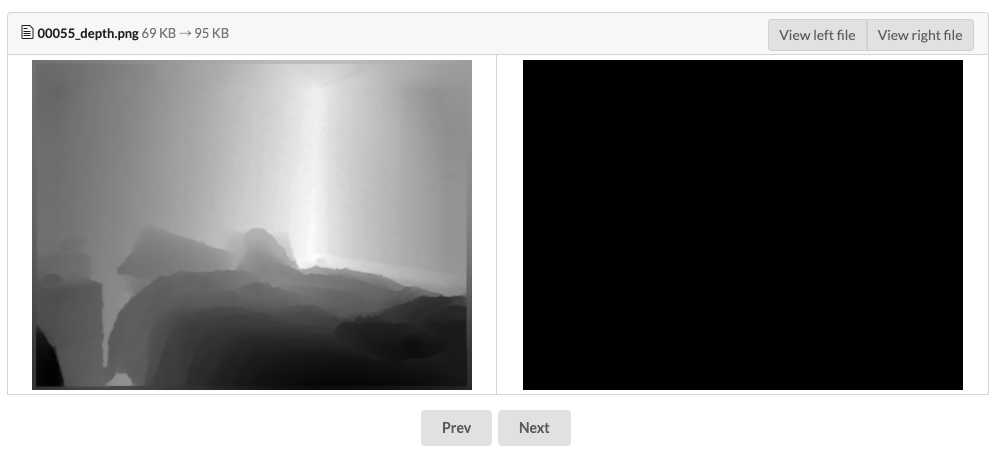
In one computer vision project I’ve been working on, an individual contributor reviewing the raw data realized that there was a normalization bug, and all the label images (this is an image-to-image task) were completely black. He could see this within the project page, create an issue describing the problem, and suggest a solution. After merging a bugfix PR, I could see the comparison of data versions and verify that the fix had worked. I’ll dive deeper into this specific case in an upcoming post.
Your Feedback is more than Welcome
DAGsHub Storage simplifies Machine Learning Collaboration and makes it much more accessible. We’re excited to see what the community builds with it.
There are many more interesting things we’re working on, and we’d love to hear your feedback on what we should tackle next. The easiest way to participate is to join our Discord Channel.




{kind=link}