


How to fine-tune LLMs
LLMs exist to be fine-tuned. Fine-tuning is the process that transforms a large language model from a generic predictive resource to one that is fully differentiated with respect to an organization’s unique datasets. To make an analogy with cooking, pre-training an LLM amounts to preparing a recipe’s base, and fine-tuning aligns with adding the spices that give a dish its unique flavor. Without the final step of fine-tuning, LLMs act as general knowledge resources, often without knowledge of a specific task or domain setting. Alternatively, LLMs that have not been fine-tuned might be less fluent and inadequately align with human expectations in their responses. They might provide responses that fail to yield the information sought by the user, or they might respond in a way that is harmful or biased. This can cause catastrophic consequences in a business context where the accuracy and safety of LLM responses is crucial.
In this article, we give a birds-eye overview of LLMs and fine-tuning before proceeding to illustrate its practical usage and benefits in a variety of business contexts as well as more technical settings. After going through the material presented here, you'll have a solid understanding of the benefits of LLM fine-tuning, common tricks and techniques for fine-tuning LLMs, and an appreciation for how LLMs might be best utilized for their specific end goal.
A Bit of History
Despite being a relatively new concept, large language models have a rich history stemming from years of precursive research and development work. The notion of language modeling has been around since the earliest days of NLP, but nascent approaches used simple statistical methodologies based on n-grams arising from splitting a long text into length n sequences of tokens. From there, early models were trained to predict the next token in a text given the n-gram preceding it.
Of course, while early n-gram models lacked much of the predictive power of those of our current era, the LLMs of today are still trained using the same fundamental idea, that of predicting the next token in a body of text. However, new modeling techniques such as attention, which allow LLMs to attend to many tokens of text simultaneously, improved GPU capabilities, multi-billion parameter models, internet-scale text corpora, and fine-tuning methods such as Reinforcement Learning from Human Feedback (RLHF), which enable models to align their outputs with human preferences, have vastly improved the fluency and generalizability of language models. No longer is language modeling a niche research technology. Instead, it is a commodifiable product upon which a slew of modern enterprises are being built.
This blog post gives a great overview of the latest and greatest architectures in the LLM ecosystem.
Popular Pre-Trained LLMs and their Fine-Tuned Variants
The current universe of LLMs is incomprehensibly vast, but some model architectures are more popular than others. You’ve likely heard the names of some of the latest-and-greatest LLMs and their associated development teams such as OpenAI’s GPT-4, Anthropic’s Claude, and Meta’s Llama-2. But new pre-trained and fine-tuned LLMs are in development all the time, and you’re less likely to hear about the ones that are tailored to niche, industry-specific tasks. Here are just a few examples:
- SciBERT – a BERT model pretrained on scientific texts
- ChemBERTa – an LLM pretrained on SMILES strings for molecular property prediction
- OpenAI Codex – an LLM trained to translate natural language instructions to code
- MPT-7B-StoryWriter-65k+ – an LLM with a super long context length trained for story writing
- Alpaca – A LLAMA-7B model fine-tuned for instruction-following tasks
- Mistral 7B – A new and high-performing LLM
- Llama 2 – Meta’s answer to GPT-4
- Claude – A ChatGPT competitor built by the AI safety company, Anthropic.
- Gemini – Google’s answer to ChatGPT
- ChatGPT – so famous that it needs no introduction
Due to the large computational requirements necessary for training them, many of the LLMs listed here have been developed by large companies such as Meta, OpenAI, and Google. However, a few open-source competitors have emerged as well, primarily BLOOM and OPT.
A Technical Guide to Fine-Tuning
While libraries such as PyTorch Lightning and HuggingFace exist to make distributed training and LLM fine-tuning easier, it still can often be a complex task. In fine-tuning, the frozen layers of a pre-trained LLM are downloaded and loaded into the training library (e.g. PyTorch) before training is resumed from the frozen state. LLM fine-tuning can use the same language modeling objective as pre-training, but with new data, or a new prediction head can be instantiated as the final layer in the neural network so that the base layers can be adapted to a new task such as classification, summarization, or question answering. The latter approach is sometimes referred to as feature extraction, in which the learned features from the pre-trained model are applied to a downstream task, but the language modeling head from the base model is discarded. As in all neural network training, fine-tuning proceeds using gradient descent, Adam, or a similar optimization method combined with backpropagation to update the model’s weights after evaluating a loss function tailored to a specific task.
Specialized Fine-Tuning Techniques
While vanilla gradient descent and Adam with a static learning rate are often sufficient for fine-tuning, sometimes specialized fine-tuning techniques can give outsized improvements.
Differential Learning Rates
In this strategy, one fine-tunes the model by applying different learning rates to each layer. Sometimes this is necessary due to differences in magnitude of the gradients across layers. This can be caused by different layer types, for example, an attention layer vs. a linear layer.
Layer-Wise Learning Rate Decay
This is a specific style of the differential learning rates approach, in which one steadily decreases the learning rate from the last layer to the first layer. The idea here is that, because the final layers are the ones which need to be completely fine-tuned from scratch, the learning rate should be the highest for these. The feature layers from the pre-trained model, in contrast, require only slight adjustments, so the learning rates for these layers can be comparatively small.
Frameworks, Libraries, GPUs, and Services
PyTorch
The most common library for training and fine-tuning LLMs is PyTorch. In fact, you’d be hard-pressed to find an LLM that isn’t coded in PyTorch in one way or another. There do exist some models written and trained using JAX, the more advanced successor to Google’s Tensorflow, but JAX’s market share is still far less than that of PyTorch. JAX does offer some advantages relative to PyTorch however, due to JIT compilation which can speed up inference on CPU, and the ability to backpropagate through advanced control flow operations. However, the ecosystem and tooling around JAX are not nearly as robust as that surrounding PyTorch.
HuggingFace Transformers
What started as a niche library for training transformer models has now become a behemoth player in the LLM space. HuggingFace, a startup now valued at over $4.5 billion, provides a rich set of tooling around training large language models and the transformer components that comprise them. What’s more, HuggingFace hosts a huge library of pre-trained models and datasets, any of which can be downloaded and used for fine-tuning with a few Python imports and function calls.
Distributed Fine-Tuning
One of the issues that arises when fine-tuning LLMs is due to the size of the models. As data and compute have grown cheaper, LLM parameter counts have increased correspondingly. As such, many models have exceeded the size of what can fit on a single GPU. Thus, fine-tuning using multiple GPUs is now necessary to train and fine-tune some of the most advanced LLMs. When the GPUs are hosted across different machines, this becomes even more complicated and leads to a state of affairs termed distributed fine-tuning.
Even when multiple GPUs aren’t strictly necessary to hold a model, data and model parallel fine-tuning can still greatly improve the speed of training. Data parallel refers to the process of splitting the dataset across GPUs so that the same model can be fine-tuned on multiple subsets of the data in parallel, simultaneously. In model parallel fine-tuning, the model weights are split up and distributed across the GPUs and each model split is fine-tuned using the full dataset.
Pure data parallel training strategies can be implemented easily using the built-in PyTorch DistributedDataParallel library. However, when using model parallelism and mixed data/model parallel strategies, it can often be beneficial to use an external library such as HuggingFace Accelerate or Microsoft DeepSpeed which greatly simplify the implementation. The HuggingFace documentation provides a great overview of different distributed training and fine-tuning strategies from basic to advanced.
API Services
If fine-tuning open source models sounds daunting or if one wants to fine-tune a proprietary model such as GPT, API services from companies like OpenAI and Databricks provide a foolproof and user-friendly way to fine-tune LLMs. Using one of these services, the process of fine-tuning usually looks like the following:
- Upload training data
- The API service fine-tunes a model on the uploaded data
- The model is provided using a web-based API, and the user evaluates the fine-tuned model
- Once the user is satisfied, the model is made available via a dedicated API endpoint and the user is charged for subsequent calls to the model
Advanced LLM Fine-Tuning Strategies
While at this point we’ve covered the essentials of fine-tuning, there exist a number of advanced techniques that can be used to fine-tune LLMs to achieve greater fluency or specialized behavior. We give an overview of some of these techniques here.
Instruction Tuning
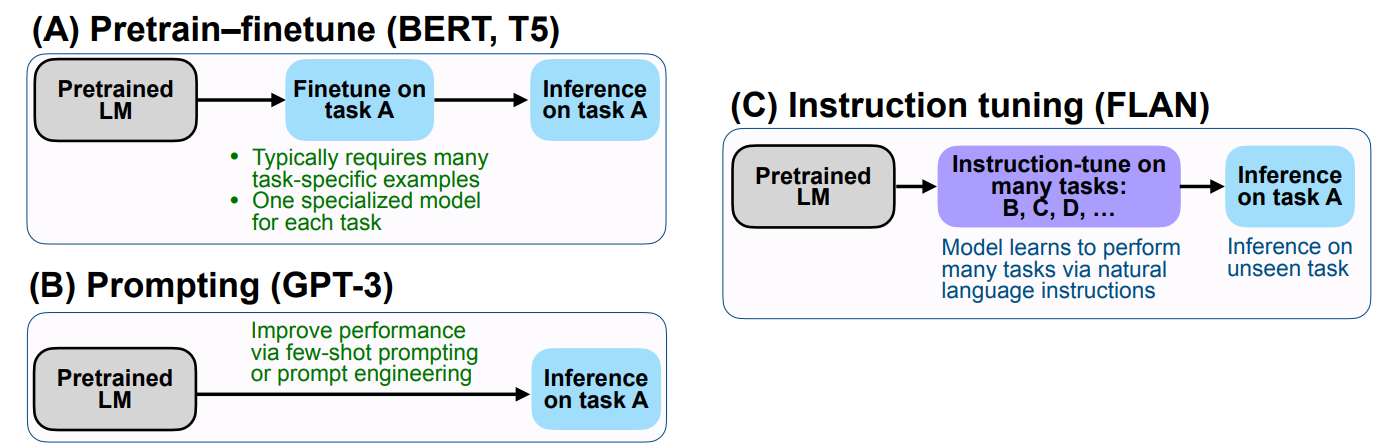
Source: https://newsletter.ruder.io/p/instruction-tuning-vol-1
In instruction tuning, one preempts the final fine-tuning stage with an intermediate step in which the model is further trained on a set of input-output pairs augmented with natural language instructions. In this way, the model learns to perform a variety of tasks from human instructions prior to being fine-tuned on a single, specific task. In a way, this can be viewed as an extended version of few-shot prompting followed by zero-shot generalization. One of the original challenges of getting instruction tuning to work was crowdsourcing a dataset of examples with instructions, but now that a variety of such datasets have been aggregated, instruction tuning is a very viable method to fine-tune an LLM. One of the best-known models trained using instruction tuning is MosaicML and Databricks’ MPT-7B Instruct. Another example of an LLM fine-tuned with instruction tuning is Google’s Flan.
Parameter-Efficient Fine-Tuning (PEFT)
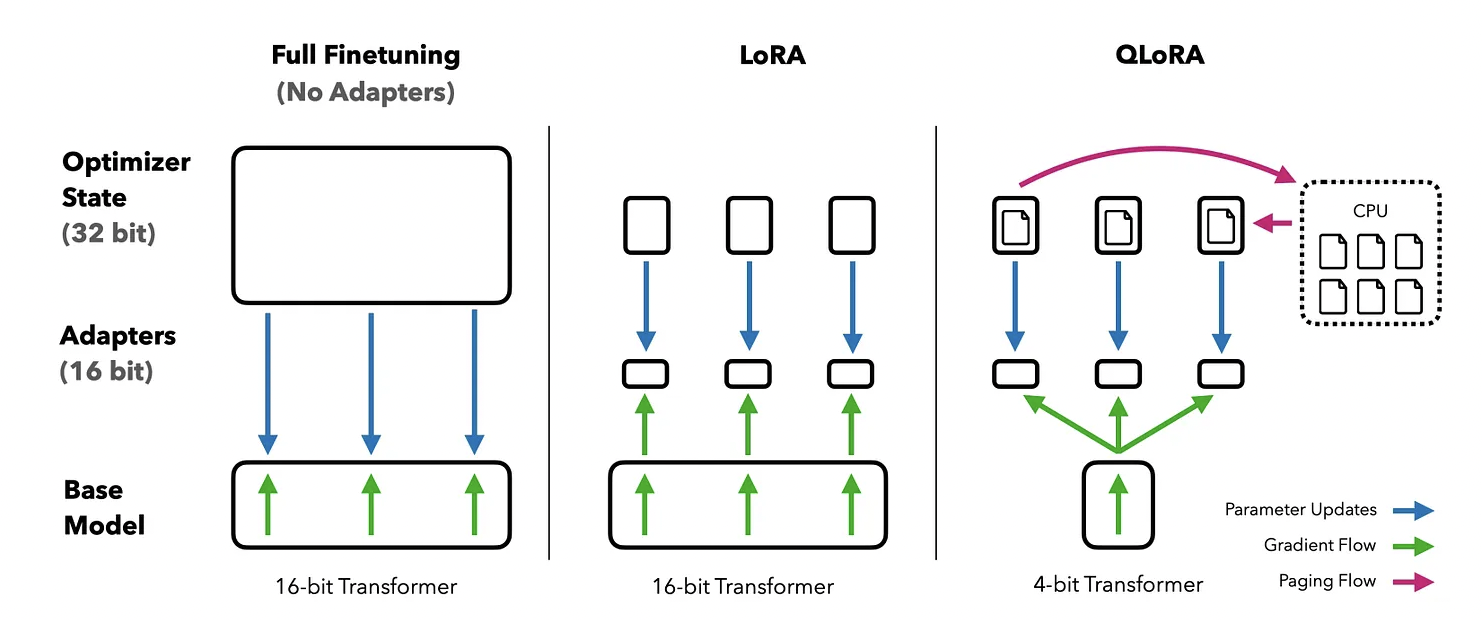
Source: https://cameronrwolfe.substack.com/p/easily-train-a-specialized-llm-peft
Different finetuning methods and their memory requirements. QLoRA improves over LoRA by quantizing the transformer model to 4-bit precision and using paged optimizers to handle memory spikes.
Low-Rank Adaptation (LoRA)
LoRA and other methods within the PEFT umbrella simplify the fine-tuning process by using a low-rank approximation to the true Jacobian (gradient) matrix update. There’s a lot of fancy mathematics underlying the LoRA algorithm, but the central idea is that the full gradient update contains a lot of extraneous, unnecessary information that can be discarded. Thus, the lower dimensional approximation can carry the gist of the gradient update while being far more efficient to compute and apply.
QLoRA
QLoRA is a quantized version of LoRA, meaning it fine-tunes the model with a lower-precision data type. While typical workflows represent model weights as 32-bit floating points, QLoRA represents parameters using a floating point representation having 4 bits (although floats large than 4 bits can also be chosen). This significantly compresses the model size, allowing it to be more easily stored in GPU memory, and also increases the speed and efficiency of model updates during the fine-tuning phase.
RLHF and DPO
Reinforcement Learning from Human Feedback (RLHF) is a technique that incorporates reinforcement learning to align language models to human preferences. In RLHF, a policy is trained to maximize a reward model. The reward model is learned from human rankings of LLM outputs in response to a prompt. Once the reward model has been trained, it can be used to fine-tune the LLM to maximize the rewards of the outputs it produces. As part of the fine-tuning process, the policy is updated using a reward optimization algorithm such as PPO.
Direct Preference Optimization (DPO) is a recent improvement to the fine-tuning process which achieves equal or better results than RLHF while side-stepping the reinforcement learning entirely. DPO greatly simplifies the notoriously tricky RLHF fine-tuning process and is now the de-facto method for training open source models that compete with ChatGPT.
Prompting and Generation
Retrieval Augmented Generation (RAG)
Despite the utility of LLMs, they are known for sometimes hallucinating, i.e. making up facts in their responses. Furthermore, an LLM’s knowledge is static based on its training and fine-tuning data. Thus, if information becomes updated, for example when a public figure dies or a world event occurs, the LLM will have no knowledge of these occurrences until it is fine-tuned on recent data. However, since fine-tuning is costly, it’s not reasonable to expect to update a model every time a new piece of information hits the web. Retrieval Augmented Generation is a strategy designed to help combat both of these issues.
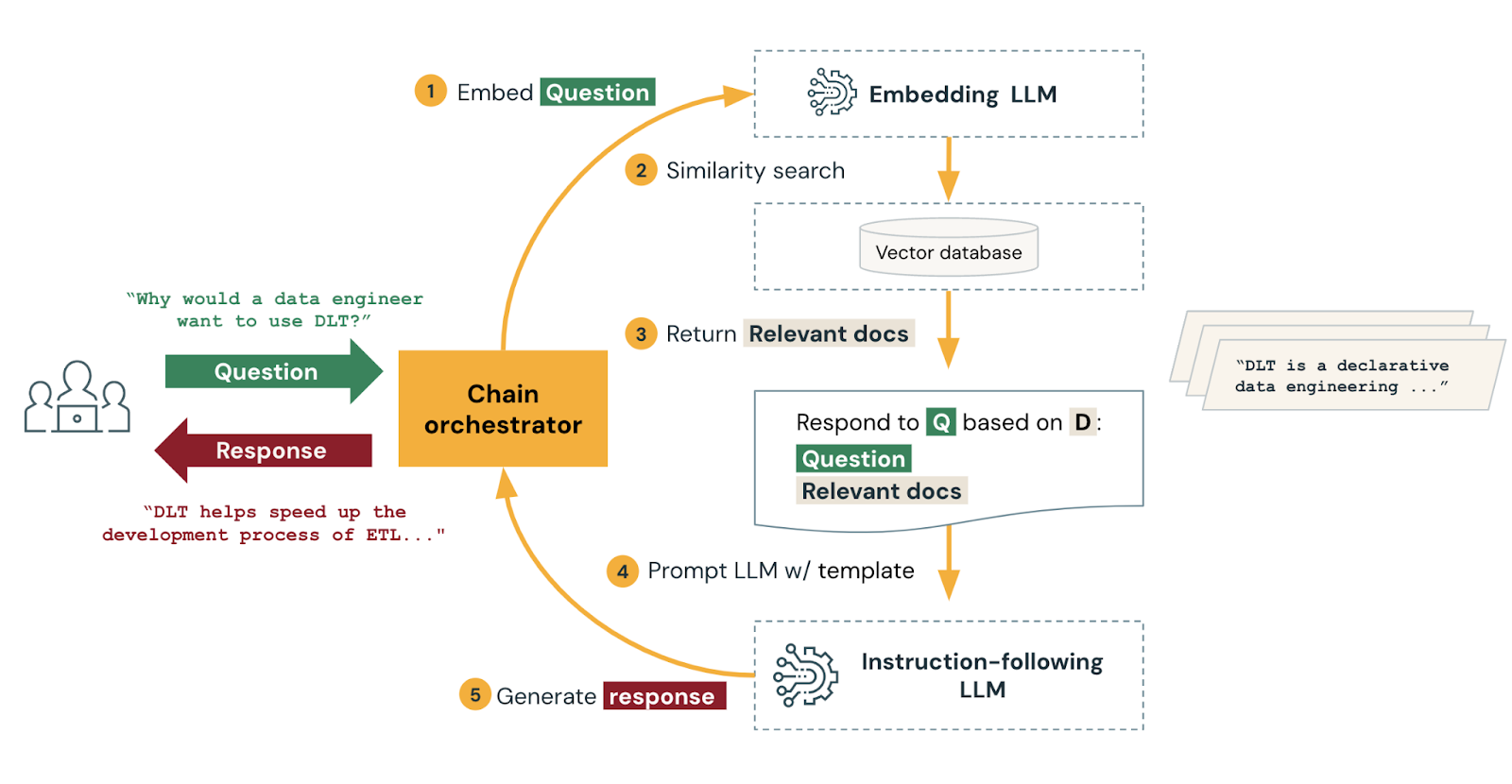
Source: https://docs.databricks.com/en/generative-ai/retrieval-augmented-generation.html
In RAG, user queries are first converted into learned embeddings. These embeddings are then run through a vector database which is regularly updated with the latest sources of information. When a high-confidence match between the user query vector and a vector in the database is detected, the database vector is returned to the LLM. The LLM then converts this vector into words and synthesizes it with its own response to the original user query. This allows the LLM to respond to the user’s request with citations to updated sources from the vector database.
RAG has been successfully applied in a variety of contexts. In this example, Nick Renotte demonstrates how RAG can be used with Llama 2 70B for finance applications. Additionally, this article from Databricks shows how companies such as JetBlue and Chevron are using RAG and similar techniques to improve their internal operations.
In-Context and Few-Shot Learning
In-context learning is a type of learning by an LLM that occurs in the context of a user prompt. In ICL, the user asks the model to learn and generalize based on something said in the prompt. Typically the prompt provides a few examples of desired behavior for the model to extrapolate from, a process called few-shot learning. For example, the user might provide the LLM with the following prompt:
Translate a song title into emojis. Here are a few examples:
I Want to Know What Love Is
i🤔😍❤️
Hit Me With Your Best Shot
🥊🤞🏻💉🔫
Under the Bridge
The user provides the model with two examples of what they’re looking for, then the model is asked to provide an answer for the final song title. Few-shot learning is one of the most powerful emergent abilities of LLMs. Generally speaking, research has demonstrated that larger models (those with higher parameter counts) tend to do better at in-context and few-shot learning.
Conclusion
While fine-tuning an LLM is far from a simple process, it gets easier every day with the variety of frameworks, libraries, and toolings devoted specifically to LLMs. In fact, the utility of LLMs in business contexts ensures that product development and fine-tuning solutions will continue to be developed to ease the barrier of entry for new users. API-based and pay-as-you-go services allow practically anyone to fine-tune an LLM to fit their needs, although it comes at the price of increased financial cost and less control over the fine-tuning process. Parameter efficient algorithms allow models to be fine-tuned using fewer and less-powerful GPUs while distributed fine-tuning techniques increase the speed of fine-tuning and the size of models that can be fine-tuned. Regardless of what approach is taken, the ubiquity of existing pre-trained and fine-tuned models show that an LLM can be fine-tuned for pretty much any type of domain and downstream task.


