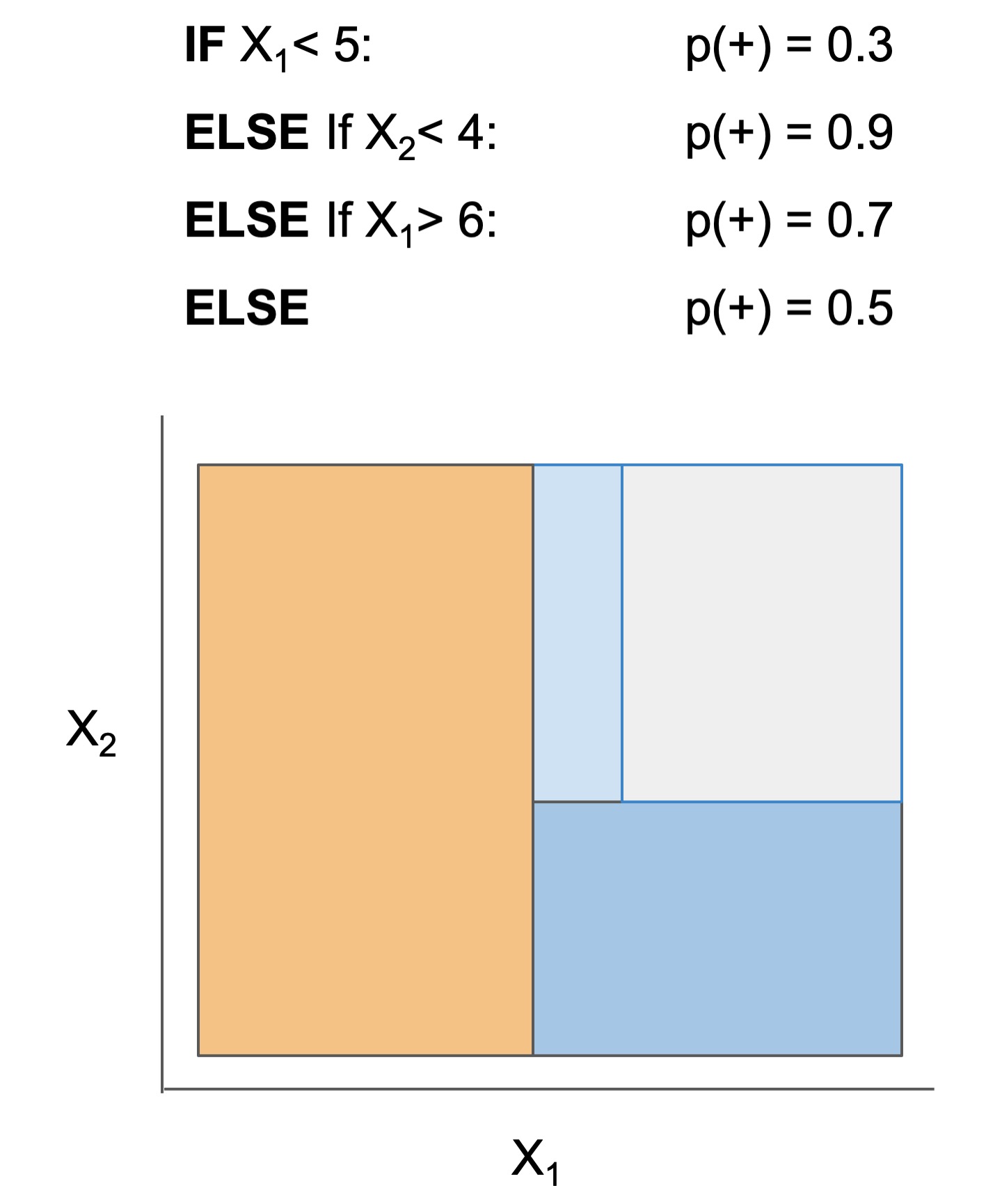
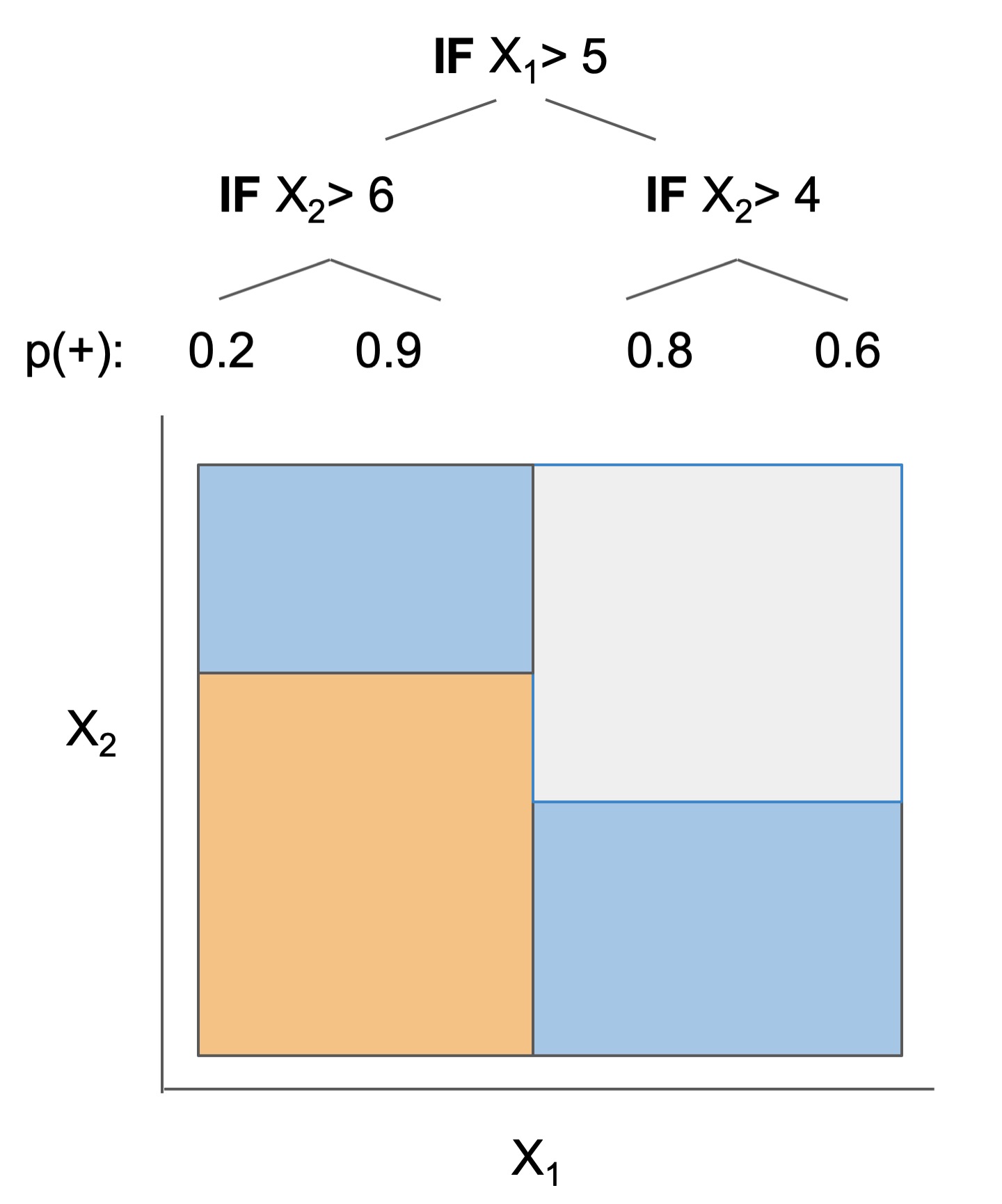
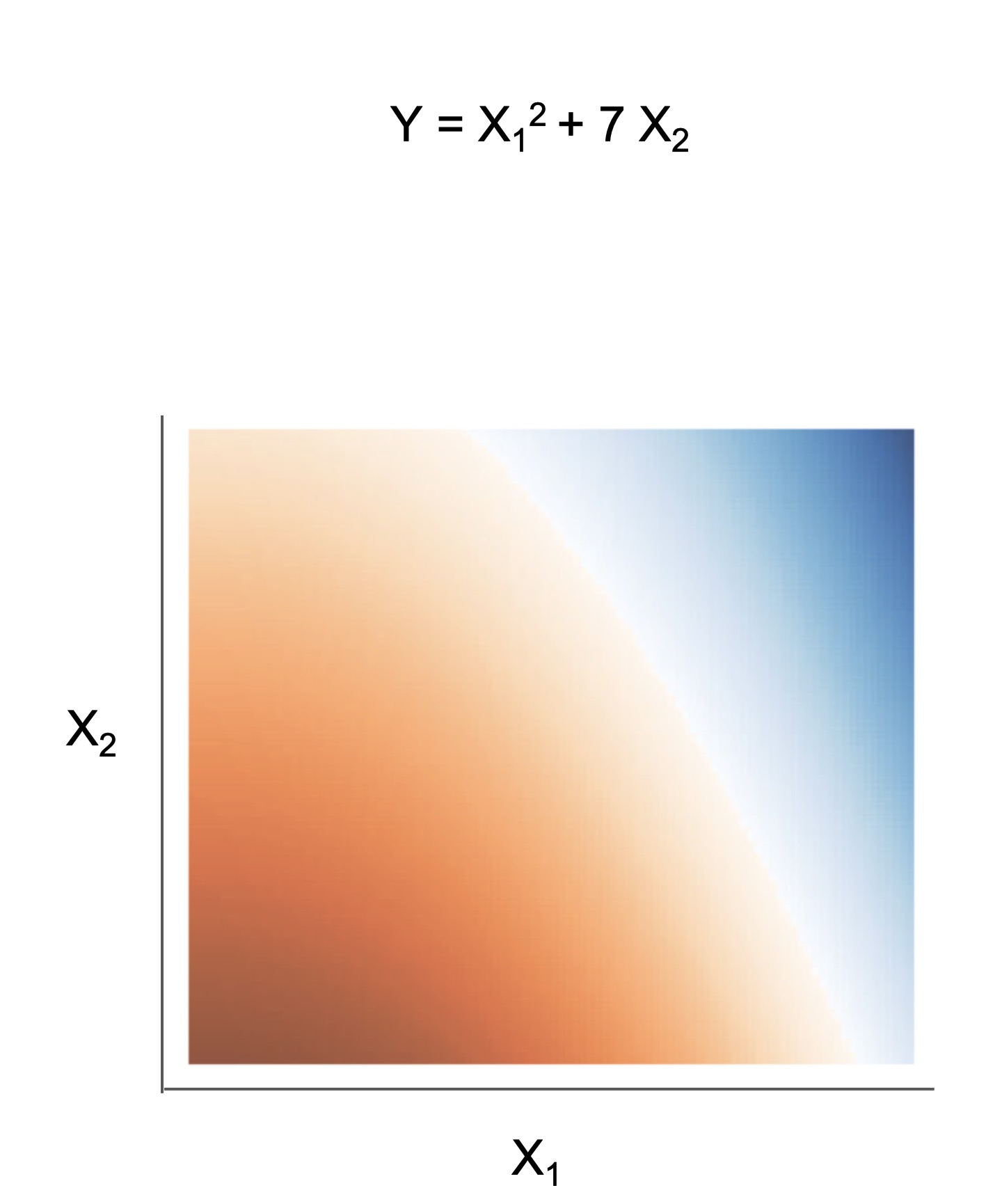
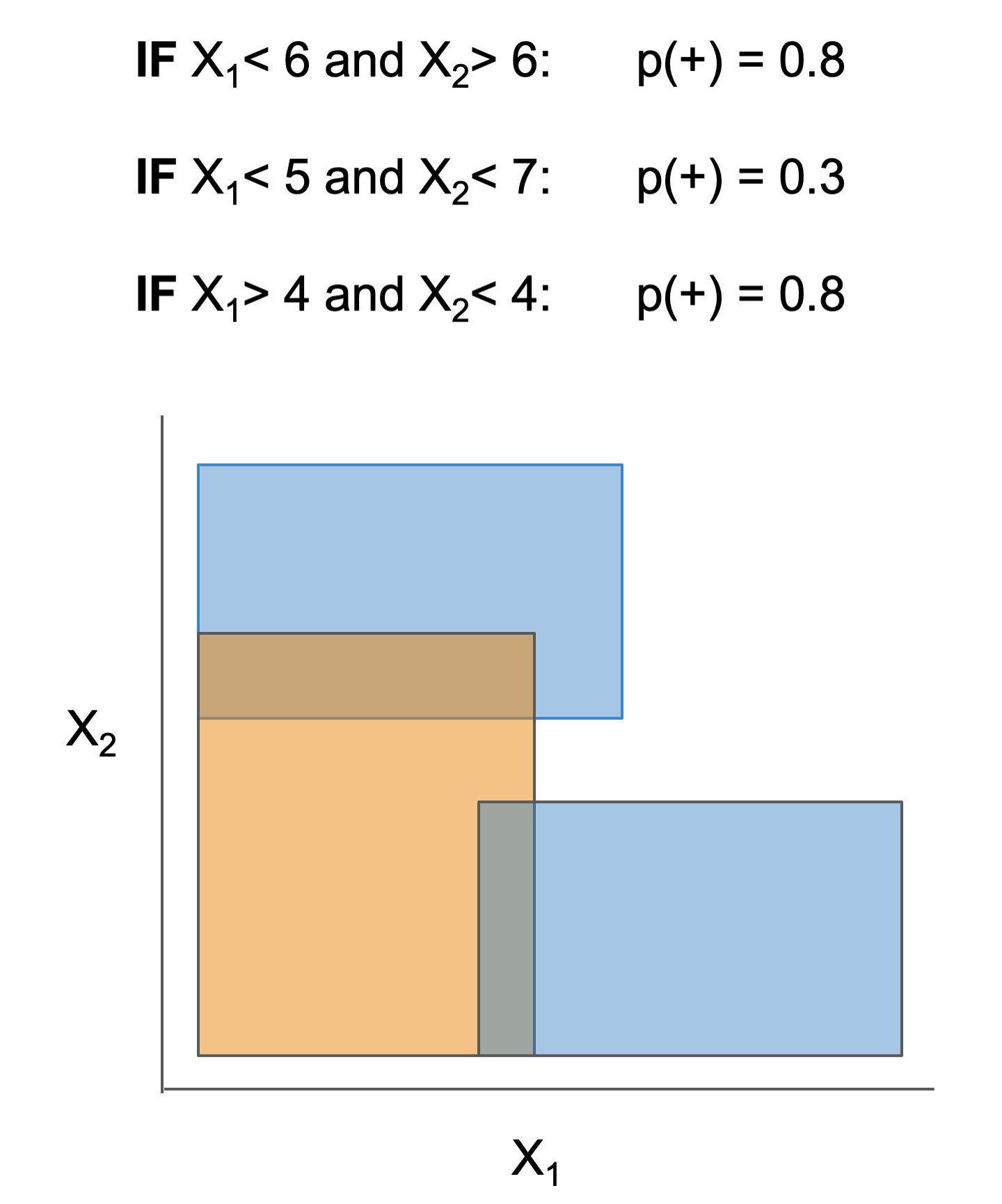Module imodels.algebraic
Generic class for models that take the form of algebraic equations (e.g. linear models).
Expand source code
'''Generic class for models that take the form of algebraic equations (e.g. linear models).
'''Sub-modules
imodels.algebraic.slim-
Wrapper for sparse, integer linear models …